
Building Private Systems in the AI Era: Resilience, Data Localization & Privacy, and Extreme Personalization — Could This Be the Next Paradigm of Computing?
AI时代构建私人系统:韧性,数据的本地化与隐私,极度个性化,会不会是下一个计算机应用的范式?(中文在后面)

AI needs to be useful
The starting point of any AI-native project can be summed up in one word: useful.
And generating a bunch of texts and AI videos that you are getting sick of, is not being that useful.
But “useful” here does not mean attracting attention, nor does it mean generating large volumes of content that sound intelligent but have no real impact. True usefulness means whether the system can enter a real-world context—whether it can actually be used by businesses, individuals, families, or organizations; whether it can integrate into daily operations, and even take on a portion of real risk and responsibility at critical points.
Why are we so dependent on AI today—almost “glued” to its interface? At the core, it’s because you feel that it “understands you.” And that feeling is not an illusion. It comes from a fundamental mechanism of large language models: their ability to generate responses based on your personal context.
This reveals an important direction: one of AI’s true strengths lies in extreme personalization. Of course, AI is also inherently powerful—its reasoning capabilities and its “near-omniscience” derived from training on vast amounts of human knowledge.
Today, AI companies are already leveraging this. By tuning model “temperature” and interaction patterns, they amplify your sense of being understood, thereby increasing user engagement. At its core, this is a business strategy.
However, I believe a more important—and overlooked—trend is emerging: the growing demand for truly personalized systems. For many people, having a highly private, reliable (not blindly agreeable), and rational assistant system will become increasingly important.
Such systems will likely share several characteristics: localized operation, private data ownership, resilience, and in some cases, the ability to function independently from the internet and cloud services. In an increasingly uncertain and unstable world, you cannot assume that critical infrastructure will always remain intact—for example, what if one day undersea cables are disrupted?
In the following sections, I will break down step by step how I arrived at these conclusions, and in the next article, I will explain in detail what the system I am designing actually looks like.
A De-Globalizing World, AI, and the Beginning of an Era
In 2026, as mature individuals, I don’t think we should still be reacting to AI news with shock and excitement. At the same time, the world itself seems to be growing more unstable: the narrative of globalization is weakening, localized conflicts are emerging, tensions in the Middle East are escalating, and a general sense of uncertainty is spreading.
All of this is reshaping the assumptions we inherited as a generation raised in the relatively stable and prosperous post–World War II environment.
Is de-globalization an important concept? Yes—very much so. Perhaps 30 years from now, we will look back and realize that many of the conditions we take for granted began with this shift. I will explain later why I see this as one of the key reasons for choosing data localization and privacy as a direction.
Unsurprisingly, in times like these—as has happened many times throughout human history under capitalism—technological iteration accelerates. Human science and technology often advance faster in turbulent and even brutal periods (major conflicts have repeatedly driven technological leaps).
But returning to my core point, let me ask a few questions:
Is there a massive bubble in AI valuations? Does AI technology equal AI companies?
Are technological value and stock market value truly equivalent?
Does having capability automatically mean achieving value?
I believe you already have your answers.
Even if today’s leading AI companies—such as OpenAI—were to fail or go bankrupt due to an inability to generate profits, we can still be certain that this technology has permanently changed the trajectory of human technological development.
AI technology ≠ AI companies.
A technological trend does not guarantee commercial success.
AI companies are still ordinary business entities—they can lose money, fail, or disappear.
We should not conflate the technology with the companies building it.
We have now come to understand the first dominant form of AI: large language models. However, AI has not yet truly integrated into productivity systems or production relationships. We are still in the phase of exploring how to operationalize it in the real world.
This has become a key principle for me, and the driving force behind everything I do publicly—whether writing articles, creating content, or building systems:
AI has not truly “landed” yet—it has not fully entered real productivity or production structures.
The key question is not model capability, but how to make it work in reality.
This requires finding a shared cognitive community—a group of people exploring together.
And what does “landing” actually mean?
It means being truly useful in the real world—bearing responsibility, involving money, and ultimately affecting the physical world.
As we deepen our understanding of this initial form of AI, we are also beginning to realize something important:
The current paradigm—centered around large language models—is absolutely not all-powerful.
And precisely because it is not all-powerful, individual builders and programmers still need to explore independently. And because it is not all-powerful, it has not yet become truly “useful.”
What Kind of Technological Paradigm Actually Allows AI to “Land in Reality” (Be Useful):
Circulating within the symbolic world alone does not equal usefulness.
You may think that by spending all day inside chat windows, you understand what’s going on—but you don’t. You’ve only temporarily used the technology.
This is not the first time humanity has faced a technological paradigm that is difficult to comprehend in its early stages. In fact, every true technological leap creates a similar cognitive vacuum: old experience fails, new structures have not yet emerged, and most people can only interpret a fundamentally different world through outdated frameworks—thereby amplifying misjudgments without realizing it.
Let me ask you a question—you may have already noticed this:
One person uses AI to summarize a 200,000-word document into 5,000 words. Another person reads those 5,000 words online and then uses AI to expand them back into 200,000 words. What value has been created here?
Of course, you could argue that both individuals gained their own understanding through summarization and expansion. That is indeed a form of personal knowledge value.
But something still feels missing. What is it?
I believe that in this era of information explosion—where content itself is not scarce—symbols are circulating within the system, but meaningful value is not being generated. Symbols must be bound to real-world structures (decisions, actions, systems).
The value of information is not determined by its length or complexity,
but by whether it crosses the boundary from the “symbolic world” to “real-world structure.”
Today, an enormous amount of symbolic content is circulating in cyberspace in a kind of “high-volume, low-value loop.”
From Web 1.0 to Web 2.0: We Actually Achieved the Crossing from Symbols to Reality
Sad truth: today’s mainstream AI has not yet reached the level of Web 2.0.
The transition from Web 1.0 to Web 2.0 marked a critical leap:
for the first time, symbols at scale penetrated and reshaped the real world.
In the Web 1.0 era, the internet primarily served as a medium for expression and display. Information was digitized and distributed, but it remained at the level of description.
With Web 2.0, represented by platforms like Facebook, a simple piece of information was no longer just read—it could directly trigger real-world actions:
You post a request and actually find a nearby nanny
You meet someone on a dating platform and end up building a real-life relationship—even a marriage lasting over a decade with children, from my own network I knew a couple like this.
Platforms like Alibaba Group pushed this even further: a single online order can mobilize production, logistics, and payment systems across regions, reshaping global trade and building highly integrated industrial supply chains
At this stage, symbols became triggers and scheduling interfaces for the real world.
A piece of digital input could initiate real resource allocation, relationship formation, and physical action.
This shift—from expression to execution—is what truly allowed the internet to change the world, and it forms the key reference point for understanding all subsequent technological paradigms.
Why Many AI Startups Fail Within ~24 Months After the Rise of LLMs
After the emergence of large language models, many AI startups instinctively tried to replicate the Web 2.0 playbook:
Platform-centric thinking
User scale as the goal
Content as the product
But at the core, they introduced something fundamentally different:
a generative logic—using models to continuously produce text, images, videos, or code, treating symbolic expansion itself as value.
This creates a mismatch:
Outer layer → Web 2.0 distribution and scale narrative
Inner layer → closed-loop symbolic generation, not linked with reality, just explosion of internet contents.
The result:
Rapid attention capture
Illusion of growth
But failure to embed into real production or decision-making systems
No sustainable value loop
So many of these projects decline or disappear within about 24 months.
Why Did Platforms Like Facebook, Alibaba, and YouTube Succeed?
At first glance, it seems similar:
Facebook → users generate content about themselves
Alibaba → merchants post product information
YouTube → creators upload videos
Why did they succeed?
Because the difference is not “user-generated content.”
The real difference is:
The symbols they generate are bound to real-world constraints and can trigger real-world actions.
Facebook:
Content is tied to real identity, real relationships, real social networks
→ Symbol → Relationship → Action
Alibaba Group:
Product listings are tied to inventory, factories, logistics, capital flow
→ Symbol → Transaction → Production
YouTube (YouTube):
Content connects to advertising systems, income distribution, career paths, and consumer behavior
→ Symbol → Attention → Resource allocation
The Core Insight
Their success does not come from “users generating content,” but from this:
Symbols are forcibly bound to real-world structures—and can be executed.
The Problem with Today’s Generative AI
Most generative AI systems:
Do not require real identity
Do not correspond to real resources
Do not trigger real transactions or actions
Are difficult to verify or constrain
So they become:
Symbol → Symbol → Symbol
A closed system.
An endless cell division within the symbolic world.
With little real-world impact—other than monetizing attention on platforms like YouTube—largely just empty talk. And too much AI generated videos is already making you sick.
I believe this is a “Generative Trap”
A successful system is not one that enables humans or AI to “say more,”but one where what is said can actually change the world.
We are using the Web 2.0 success path (content → users → scale)
to interpret a fundamentally different capability in AI (symbol generation)
This leads to a systematic misjudgment:
The assumption that “stronger generation = closer to real-world deployment”
What Does a Truly Deployable (Useful) AI System Look Like?
In the simplest terms, it must be useful.
It can be useful to yourself, to an individual, or to a family—even if it does not directly generate economic returns
Or it can be useful to a business—supporting operations and management, reducing labor, taking on responsibility, guiding decisions, and even directly generating economic value
It may even provide reliable decision-making for individuals—such as investment decisions—that ultimately create value
An AI-native system of this kind must satisfy the following:
1) Bound by Constraints
It operates under real data, real states, and permission constraints
It cannot generate arbitrarily
Everything must be traceable back to verifiable evidence, such as original records or documents
2) Consequential
Its outputs affect decisions or actions
There are costs and risks associated with those outputs
3) Verifiable
It can be validated through real-world feedback
Correctness is not judged by “does it sound right,” but by actual outcomes
And in the short term, given identical inputs, there should be confidence in producing consistent results
If AI cannot be used for decision-making, I personally can’t think of any truly important use it has for me. Generative text and videos are of little value unless you’re trying to be an influencer. So in my view, the only real path for AI to truly “land” is through embedding into reality and assisting decision-making.
Is one-person unicorn truly possible?
Sam Altman, founder of OpenAI, has said for years that AI will enable a “one-person company” to achieve the kind of scale that previously required large teams—potentially even reaching billion-dollar (unicorn) levels.
Alright, let’s not debate whether this prediction is possible. If it is possible, then how would it actually be achieved?
A single person could, in theory, possess capabilities that previously required entire teams: coding, marketing, distribution, management, and decision-making. That part is not the problem. The real question is: what kind of project could make this possible?
If we follow the Web 2.0 logic I mentioned earlier, there are already companies that, with very few developers and operators, can leverage enormous output value. One example is OnlyFans.
Based on its 2024 revenue, after paying creators, the platform’s 20% commission amounted to $1.41 billion, with approximately $684 million in pre-tax profit, while operating with only about 40–50 core staff.
This is a classic Web 2.0 platform model:
Content as the product
Attention as the monetization mechanism
The only thing that makes it different from other platforms or sharing economy models is that its content belongs to a “gray-area industry”—arguably one of the oldest and most profitable industries in human history (essentially a zero-cost business).
So if we follow Sam Altman’s logic, and imagine a one-person unicorn built on a similar model—global audience, content monetization, platform commission—could its “grayness” really exceed OnlyFans? Probably not. The only way might be to replace the human content creators with AI and capture the 80% share that currently goes to them.
Have you ever questioned whether, beyond subscriptions, tips, and advertising, there exists another way for computers, AI, and the internet to generate revenue?
If you don’t rely on massive user bases—if you don’t rely on crowds to pay you—how do you create value?
Can information itself have intrinsic value?
Yes, it already exists. Just ask BlackRock.
There are even rumors that Aladdin—Aladdin—has long been AI, though I personally don’t believe in conspiracy theories.
So what am I trying to say?
When we step outside the mental framework of Web 2.0 and rethink the problem, a more fundamental question emerges:
If value does not come from users paying, can a system still create value?
Most people operate under the assumption that:
Revenue = users paying (subscriptions / ads / tips)
But this is merely a value transfer model:
Users transfer money to the platform
The platform earns a cut
No fundamentally new value is created
OnlyFans is simply an extreme optimization of this model.
So the real question becomes:
Is there a model that is not about transferring value, but about creating value?
In other words:
Not dependent on scale
Not dependent on traffic
Not dependent on crowds
But where the system itself directly produces value
The answer is yes. And this is precisely the most important shift in the AI era.
But it is not about monetizing information.
It is about:
Decision → Action → Outcome
If we break down existing models:
1) Information Monetization (Web 2.0)
Provide content → users pay
Essentially selling information
2) Tool Monetization (SaaS)
Provide tools → users use them to make money → share a portion
Essentially selling capability, but not participating in outcomes
3) Outcome Monetization (Pre-AI but already in use)
Before the rise of modern AI, top players like BlackRock—through Aladdin—were already operating in this model:
The system participates in decision-making
The system participates in execution
The system directly produces results
Revenue comes from the results themselves—not from user payments
If we follow this logic further:
The greatest value of AI is no longer:
Attracting attention
Generating infinite content
Instead, it is:
Entering the decision layer and directly participating in the process of value creation.
If AI is to push individuals or organizations beyond the limits of existing technology, it must enter the decision layer. What you’ve been interacting with is not decision-making — it is merely optimization.
This question is actually highly abstract. I’ve only gradually come to realize it myself recently, and even now it’s still difficult to articulate precisely.
So let’s start from something everyone is familiar with — a class of classic NP-complete problems, such as the Traveling Salesman Problem. Isn’t this one of the most iconic problems in computer science?
In the past, if someone built a system for a logistics company based on something like TSP, people would consider it extremely impressive. The definition of the problem is very clear: given N cities, find the shortest possible route that visits each city exactly once.
The difficulty lies in combinatorial explosion — once the number of cities increases, the number of possible routes grows exponentially. Ten cities is manageable. Fifty becomes extremely complex. One hundred is essentially beyond human capability.
Problems like this are both classic and practical, and they easily create a strong sense of technical sophistication — as if being able to solve them means you have mastered “decision-making ability.”
I used to think the same way. Some time ago, I even wrote an article analyzing and solving problems similar to Mastermind, another NP-complete class problem. At the time, I also believed I was doing “decision-making.”
But looking back now, what I was doing was actually just optimization, not decision-making itself.
Why do I say that?
Because all NP-complete problems share a hidden premise:
as long as a problem can be fully defined, it is fundamentally a closed-world problem.
That means:
All variables are known
All rules are fixed
The objective is clearly defined
The problem can be exhaustively enumerated or approximated
In other words, although these problems are computationally difficult, they rely on a crucial assumption:
The world is complete.
The Real World Is Multi-layered and Radically Complex
But real life is the exact opposite.
The actual decisions you deal with every day — for example, your child’s education, attention issues, communication development — require you to synthesize teacher feedback, evaluation reports, and then design extracurricular plans. At the same time, you must coordinate these plans with your own work schedule, family responsibilities, another child’s timeline, while also considering cost, distance, and energy allocation.
Or consider tax decisions: whether to sell a particular stock this year, how that affects your tax burden, how to use deductions.
These are not just numerical optimization problems. They involve:
large amounts of ambiguity
constantly changing conditions
variables that are not even quantifiable
And historically, these kinds of variables could not even be incorporated into what we call “computational problems.”
In other words:
Traditional computer science deals with problems that are already well-defined
But real-world decision-making is difficult precisely because the problem itself is not clearly defined
Real Decision-Making Happens Before Optimization
The same logic applies to companies.
When you build a TSP algorithm for a logistics company, it looks like you are solving a highly complex problem. But in reality, what they have given you is simply the cleanest and most simplified optimization problem.
The real decision-making has already happened before that.
If we break down a real logistics scenario:
TSP solves the following:
given a set of orders and constraints, find the optimal route.
But the real decisions happen at a higher layer:
Which orders should be accepted?
Should orders be split?
Which ones can be delayed?
Should pricing be adjusted to filter demand?
Should warehouse layouts be changed?
Should certain regions be abandoned altogether?
These questions:
do not have fixed objective functions
do not have clearly defined inputs
do not have standard answers
They involve:
incomplete information
conflicting objectives
dynamically changing environments
The reason you are handed a problem that “can be solved by an algorithm” is precisely because an experienced operator — the MBA-trained logistics owner, for example — has already done the hard part for you in a place you cannot see.
They have already:
filtered the variables
defined the objectives
imposed structural constraints
They have taken a chaotic real-world problem and compressed it into a clean, closed, almost perfectly structured mathematical problem — and only then handed it to you.
At that point, no matter how elegantly you solve it, what you are doing is still optimization, not decision-making.
But because the problem is formally complex and computationally difficult, it easily creates the illusion that you are working on core intelligence.
The real issue is that the computational world we built in the past has been too “clean.”
And this “cleanliness” is, in fact, a limitation — a form of reduced capability.
We have been forcing a complex world into something that is “engineerable.”
Because machines could not understand semantics, they could only execute deterministic logical rules. Therefore, all problems had to be:
predefined
structured
bounded
before they could even enter a computational system.
But the real world itself is:
multi-layered
incomplete
full of ambiguity and conflict
Once machines begin to understand semantics, the wall that once separated real-world complexity from computational systems starts to collapse.
And when that happens, the fundamental logic of computing no longer holds:
it is no longer just about solving predefined problems —
it must shift toward handling the generation of problems themselves and the definition of structure.
And that, in essence, is a complete paradigm shift.
The World Is Full of Truly Complex and Valuable Problems
Forcibly compressing these problems only makes systems that can truly carry complexity more valuable.
Due to the limitations of human computational capacity, we historically compressed decision problems into optimization problems.
Let me give an example that is very familiar to Chinese audiences—and I believe English audiences will also quickly grasp it:
👉 KPI — compressing complex objectives into a single number.
Everyone understands KPIs. But what is the KPI of a country?
For China, which has experienced rapid growth over the past 30 years, the national KPI has effectively been GDP prioritization.
Following the logic I laid out earlier:
GDP is a compressed optimization target, while human well-being is a decision problem that has not been properly modeled.
First, GDP needs to be placed back in its proper context.
Gross Domestic Product is merely a statistical indicator, not a goal in itself.
However, once it enters a governance system, a critical transformation occurs:
Complex social reality → compressed into a single number (GDP)
That number → becomes a KPI
The KPI → becomes the optimization target
At that point, the entire system is restructured into an optimization problem.
So-called GDP prioritization is, in essence, the act of forcibly compressing a fundamentally complex decision problem into a computable optimization problem.
The original problem is inherently:
multi-dimensional
incomplete
difficult to fully quantify
For example:
Are people living well?
Do they feel secure?
Do they have hope for the future?
Is the social structure healthy?
These are all decision problems, characterized by:
multiple objectives
partial or non-quantifiability
lack of a unified evaluation standard
But once everything is translated into a target such as:
“GDP must grow by 8% or 5%”
the system becomes a single-objective optimization problem.
This compression is widely adopted because it provides clear engineering advantages:
quantifiable
comparable
assessable
executable
It makes governance operational.
But the cost is equally significant:
A large number of critical variables are lost, such as:
the quality of poverty, not just its quantity
the real accessibility of healthcare
family structure issues (e.g., left-behind children)
the psychological state and future expectations of young people
fertility intentions
These variables are:
difficult to quantify
lacking standardized metrics
slow to produce feedback
Therefore, they are systematically excluded from the optimization target.
When GDP becomes the KPI, all behavior begins to revolve around that metric:
prioritizing high-return projects
neglecting long-term factors not captured by GDP
ignoring distribution structures
overlooking individual lived experience
Eventually, what is being optimized is no longer reality itself—but the metric.
This is precisely what Goodhart’s Law describes:
When a measure becomes a target, it ceases to be a good measure.
The root cause is that:
a metric is originally designed to reflect reality
but once it becomes the driver of behavior
reality itself becomes systematically distorted to fit the metric
So What Does “Useful” Actually Mean?
It means enabling existing systems to carry more complexity and make higher-order decisions.
And crucially:
👉 these decisions are not easily compressed.
On the surface, the system may appear to be doing the same work.
But in reality, it is:
delaying compression
or even refusing premature compression
It preserves:
context
disagreement
uncertainty
It allows the system to operate in a higher-dimensional space—
and only makes decisions when necessary.
That is a massive leap forward.
So at this point, what I want to express is actually quite simple: the world is undergoing a structural shift—deglobalization is no longer an isolated phenomenon but an unfolding trend; AI will permanently become part of the technological system, yet its value lies not in showcasing capabilities, but in being useful—it must be grounded in reality, participate in decision-making, and be embedded within concrete systems. For the first time, machines can understand semantics, which means many of our long-standing engineering philosophies in computing must change: computers that understand meaning can begin to carry real-world complexity without forcing everything into overly compressed metrics or KPIs. If you follow this logic, you arrive at a series of conclusions that may sound counterintuitive today, but are in fact entirely natural. They feel counterintuitive because our generation grew up in a paradigm shaped by globalization, long periods of peace, efficiency-first thinking, and the equation of “the internet = computing,” operating through abstractions like Excel and ERP systems that are highly structured but strip away much of the real world’s complexity. These environments have left deep cognitive imprints on us. The next phase, however, will gradually dissolve these assumptions: computers will begin to resemble humans in their ability to handle complexity; data will move toward localization and privacy; systems will prioritize resilience; and truly valuable services will no longer aim for universality, but instead move toward extreme personalization. In the following sections, I will derive these ideas step by step.
In the AI era, a new super-variable has emerged in computing: Context
AI has introduced an entirely new super-variable—one that, years from now, will likely be written into textbooks:
Context
Anyone who has used AI extensively is already familiar with this term, and it has become deeply intertwined with large language models.
The concept itself is highly abstract, but the deeper issue is this: our way of thinking has already been profoundly shaped by an entire generation of computing paradigms—mobile devices, the internet, and SaaS. Many of our assumptions are not things we consciously “understand,” but rather structural inertia formed through long-term interaction with these systems. To truly adapt to the arrival of AI—and even to build more powerful systems on top of it—we must begin dismantling these deeply ingrained assumptions. And this is not something that can happen overnight; it requires time and exploration.
Let me give a very simple but critical example.
In the computing world you are familiar with, a single smartphone contains countless apps, and they are naturally fragmented from one another. Even within the same organization, this fragmentation persists: the accounting department uses one system, the marketing department uses another. When making decisions in the marketing system, you cannot directly invoke the capabilities of the accounting system. What you receive instead are outputs that have already been processed by the accounting team—for example, last quarter’s financial report analysis. In a sense, this is essentially a form of a “human API.”
In other words, the systems we are accustomed to today are fundamentally:
isolated by default, fragmented by nature, and mutually unintelligible
And under the technological constraints of the time, this was the “optimal solution.” Because in the pre-LLM era, “context” was not even treated as a serious engineering variable. As a result, the entire system landscape was structured like this:
Each system maintains its own data model
Each system enforces its own boundaries
Systems exchange information through APIs in an extremely compressed form
And in most real-world scenarios, even this exchange cannot be automated and relies on humans moving data across PDFs, Word documents, and Excel sheets
The consequence is:
Within the same organization—regardless of size—no single system is capable of seeing:
the complete “decision context”
The emergence of AI is the first time a crack has appeared in this structure.
LLMs can process uncompressed semantic context, creating a form of cross-system “contextual continuity.”
In theory, you could build a system that:
simultaneously understands financial data, user behavior, market strategy, and risk constraints
integrates all of this within a unified semantic space
and makes decisions based on that integration, rather than relying on fragmented outputs
But the reality is that we are still far from this stage. Most so-called “AI applications” today remain at a very primitive level:
treating context as something to concatenate into prompts
instead of moving to the next level:
treating context as a first-class object—to be modeled, scheduled, isolated, and evolved
In other words, we have glimpsed the direction, but we have not yet built the language, structure, or engineering systems capable of supporting it. This gap is precisely where the most meaningful exploration will take place in the coming years.
Simply “extending context length” or “fully connecting systems” are both fundamentally flawed approaches
I believe that context engineering will become a critically important field of application in the future.
Because whether it is:
naively extending context length—assuming that as long as LLMs can handle longer inputs, the problem is solved
or attempting to completely eliminate all fragmentation between systems
both approaches are fundamentally crude. Neither can truly support the complexity of real-world systems.
In my view, this field is still largely unexplored. We have not yet established a clear engineering paradigm.
“Longer context” ≠ “understanding context”“Connecting systems” ≠ “being able to support real systems”
Many people instinctively assume that AI progress is equivalent to:
longer context windows
more information visible to the model
less isolation between systems
That as long as context is long enough, intelligence will naturally emerge.
This conclusion is wrong.
Anyone who has actually operated a business or dealt with real-world complexity knows that the problem is far more complicated. Because context has never been a problem of length—it is fundamentally a problem of structure.
If you imagine “infinite context” as a system, it would resemble:
a database without indexing
a knowledge base without structure
a memory system without prioritization
In such a system, the first thing that happens is an explosion of noise:
relevant and irrelevant information become entangled
the model can only rely on probabilistic guessing to determine what matters
fundamentally lacking a selection mechanism
Second, decision-making becomes highly unstable:
the same question may produce entirely different results at different times
small variations in context can change the reasoning path
the system lacks deterministic decision pathways
Finally, computational cost spirals out of control:
latency becomes unpredictable
the system cannot be engineered or deployed reliably
fundamentally lacking a scheduling mechanism
Similarly, I believe that “fully connecting all systems” is also fundamentally unworkable.
If you merge accounting systems, marketing systems, user behavior data, and even private information into a single so-called “super-context,” it may appear unified on the surface, but in reality it leads to another extreme:
👉 boundary collapse
Once boundaries disappear, a chain of problems follows:
access control becomes impossible
semantic contamination occurs across domains
accountability in decision-making becomes unclear
the system loses auditability
Such a system is simply unusable in the real world.
We do not yet have an engineering discipline for how context should be constructed, selected, scheduled, and isolated. We need to explore context engineering, significantly.
As the world we live in continues to evolve, what LLMs bring is not merely an upgrade in tools, but the gradual emergence of an entirely new technological paradigm. This shift implies that many of the deeply ingrained assumptions in both computing and business will need to be re-examined.
As AI begins to enter real production environments at scale, context is becoming a critical intangible asset. In certain high-value and highly sensitive domains, the value of context may even exceed that of traditional physical assets. Whether it is long-established family businesses that have accumulated decades—or even over a century—of operational history, whose experience and knowledge can be systematically engineered into structured context, or knowledge-intensive institutions that hold significant client relationships and strategic resources—such as top-tier law firms and financial institutions—the true value of these “context assets” will gradually be recognized and re-evaluated. Some enterprises, families, organizations, and non-profit groups possess highly valuable contextual assets that have not yet been fully uncovered or utilized. We already understand AI’s strong capabilities in pattern recognition and in uncovering hidden information. Therefore, data privacy will become an extremely important area of enterprise services in the next era.
Once computing systems reach the level where they can meaningfully carry and utilize such context, entities that possess these assets will significantly increase their emphasis on data privacy. In some high-value scenarios, this may even lead to requirements that data be completely isolated from the internet.
At the same time, individuals and organizations that hold critical decision-making information will increasingly prioritize system resilience. They will begin to prepare for risks that were rarely considered in the relatively stable and peaceful environments of the past. When necessary, they may even choose to sacrifice a degree of efficiency, rather than single-mindedly pursuing profit maximization.
In this context, small companies—and even very small teams—will gain new room to survive and compete. The broader paradigm may also shift away from a model resembling “everyone buying standardized products from a supermarket,” toward one in which more people can access highly customized systems and services tailored to individual needs.
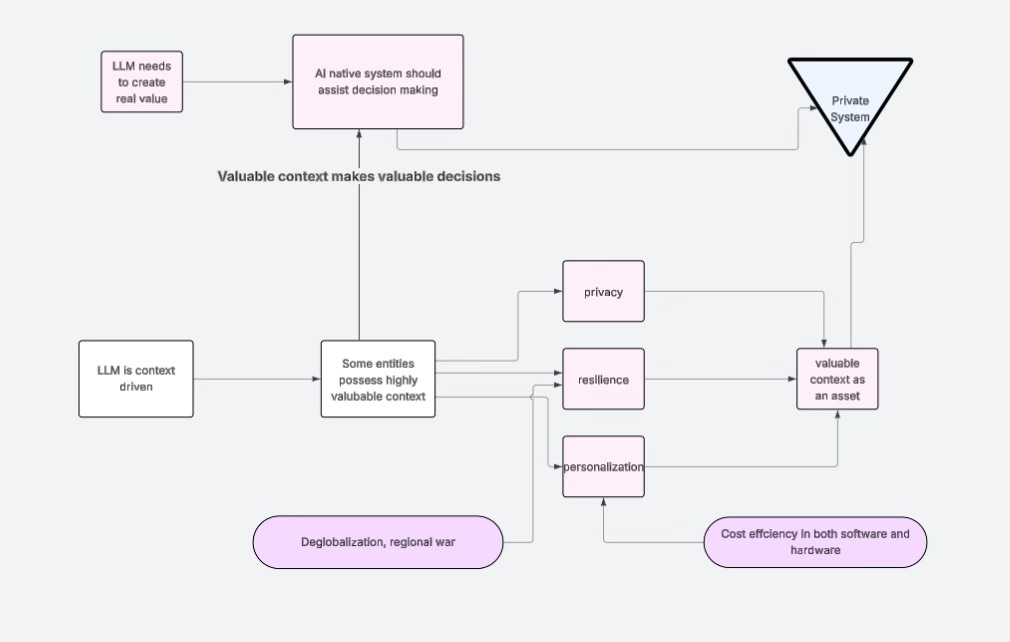
Localization and Data Privacy
Now you’re seeing more and more signals everywhere. You see headlines claiming that “SaaS is dead.” You see growing debates around data trustworthiness, which sometimes extend into questions like “which country is this provider’s server located in,” and eventually escalate into political-level disputes. You also see an increasing number of cybersecurity incidents.
At the same time, you might still think: I’m just ordering a cup of bubble tea—what privacy value could my personal data possibly have?
But the real issue is this: in the AI era, this kind of seemingly insignificant individual data is quietly transforming into structural information that can be embedded into context and participate in decision-making.
Data privacy → value ownership → context
Why has “data privacy” suddenly become a core issue in the AI era?
In the Web 2.0 era, data was essentially just behavioral records—clicks, views, purchases. Its value came from statistical aggregation, users were passive data providers, and companies monetized through advertising or subscriptions. The key point was that an individual user’s data had almost no value on its own—only scale created value.
But in the AI era, a structural shift has occurred:
👉 data is no longer just “records”—it becomes context.
And entities such as hospitals, investment firms, law firms, and wealthy families—those operating in high-value domains—will likely become the first to actively move away from large cloud providers, shifting toward localized systems and strict data isolation. This is because their systems share three common characteristics:
1) Extremely high decision value
A single decision in a hospital can determine life, litigation, and cost
A single decision in an investment firm can involve hundreds of millions in gain or loss
A single decision in a law firm can determine case outcomes or risk transfer
A single decision in a family can affect wealth inheritance and generational structure
2) Highly complex context
Long time horizons (years to decades)
Multi-role collaboration (doctors, partners, family members)
Significant amounts of implicit information (experience, relationships, judgment)
3) Non-standardizable
No two hospitals operate exactly the same
No two investment logics are identical
No two family structures are the same
This directly breaks the core assumption of SaaS.
As a result, these scenarios are inherently resistant to the “cloud + SaaS” model. This is not a preference issue—it is a structural one.
Because their core asset is no longer data itself, but context.
And even as I am writing this, I have already seen cases such as Palantir Technologies having partnerships—such as with a New York healthcare system—not renewed, where the underlying issue is precisely data privacy and control over context.
Events like this will only intensify, gradually forming a technological and architectural shift away from large centralized cloud providers.
And importantly, this direction is no longer theoretical—it is already becoming practically explorable in our time. In future sections, I will continue to analyze and validate this trend through my own work on localized systems.
In the era of big tech and large-scale cloud platforms, a portion of the system will be carved out.
Conversely, a smaller segment—localized, highly personalized systems—will begin to emerge and grow, starting from very small scales.
System Resilience
Continuing from the earlier discussion, under an internet paradigm where big tech companies and large cloud providers have come to dominate almost everything, a new class of localized applications is gradually emerging. This is not just a technical shift—it reflects a change in underlying philosophy.
Many programmers with fixed mental models will instinctively push back against this trend using familiar metrics such as efficiency, scale, and cost. But that is precisely where the problem lies. This is also why I chose “deglobalization” as the framing at the beginning of this article:
If you insist on arguing from efficiency and scale, then isn’t globalization the most efficient and largest-scale organizational model? The answer is obviously yes. Yet reality also shows that globalization is still reversing despite that.
As geopolitical instability increases, localized conflicts intensify, and systemic risks continue to surface, the entire set of production systems, supply chains, and industrial organization models that we once took for granted—those built around “efficiency first”—are beginning to evolve in the opposite direction: toward localization, regionalization, and redundancy.
At its core, this is the return of a long-ignored issue: we have been using “optimization problems” to mask real-world complexity. As external uncertainty rises, this compression of complexity begins to fail—and can even backfire on the system itself.
Over the past few decades, both industrial systems and the internet were built on a shared assumption: the world is stable, and therefore continuous optimization is possible. Under this assumption, we constructed an entire “optimization machine”:
global supply chains (just-in-time)
single-point optimal production (lowest-cost regions)
highly fragmented, long-chain division of labor
extremely compressed inventory systems
But all of this rests on a fragile assumption:
Nothing will go wrong.
Once this assumption breaks, the entire logic flips.
In a world of high volatility and uncertainty, what was once optimal becomes the most fragile point in the system. For example, concentrating production in a single country may have been cost-optimal in the old world—but in a disrupted environment, it becomes a single point of catastrophic failure.
The same applies to the internet and AI. Big tech and large cloud platforms are, in essence, a form of “centralized optimal solution.” But as uncertainty expands, we must ask a different question:
Is absolute efficiency still the most important goal of a system?
The answer is clearly no.
The core objective is shifting toward:
Resilience
This does not mean rejecting the cloud, nor does it mean everything must be localized. It means the priority of system design is changing:
from maximizing single-point efficiency
to ensuring continuous operation under uncertainty
This may not be immediately intuitive for programmers. But for leaders of large hospitals, top law firms, or family offices managing highly sensitive client information, the implications are immediately clear.
Because they already operate in environments defined by:
high-value decisions
high privacy requirements
high risk sensitivity
They are naturally attuned to questions such as:
Is the system controllable?
Is the information secure?
Are decisions sustainable over time?
And today, something fundamental has changed.
For the first time, the necessary conditions have converged:
widespread availability of powerful hardware
maturity of general-purpose software
and the emergence of AI
This combination means that what once sounded like a fantasy is now entirely achievable. It is no longer something reserved for large institutions—it is something that even a well-resourced household can afford to build.
In other words:
the motivation is mature (growing demand for privacy, control, and long-term decision capability)
the conditions are mature (falling hardware costs and lower technical barriers)
The convergence of these two forces signals a structural shift in our era.
At the same time, the logic of the world itself is shifting:
from “global optimality”
to “local controllability”
In the past, the consensus was simple:
cheapest = best
long and deeply interdependent supply chains were acceptable
Now, the priority has changed:
A system must first be able to survive in an unstable environment—only then does efficiency matter.
This is why we are seeing:
the return of localized supply chains
the formation of regional economic blocs (not full decoupling, but reduced dependence)
deliberate introduction of redundancy in enterprise systems
The fundamental shift is this:
Systems are now being designed for failure, not just for success.
In this context, a truly resilient system also undergoes a structural transformation:
from centralized control
to structured decentralization
It is important to emphasize that this is not ideological decentralization, but an engineering-driven choice.
Such systems are composed of multiple nodes:
each node can operate independently
connections can be severed when necessary
yet core functionality remains intact
This manifests as:
collaboration between local AI and cloud systems
loosely coupled relationships between smaller systems
reduced dependency on any single platform
Ultimately, there is only one real test:
Can the system continue to operate even when disconnected from the network or a central node?
In other words, it must have the ability to:
survive offline
To put it bluntly—even in my own household, we are already building this.
So if I’m doing it at home, how could any high-value small company with real needs possibly not have the same demand?
Extreme Personalization
A fundamental question: if there were a system designed specifically for you—one that could help you make decisions, whether in investing or running a business—and in the end, you made money from it. Suppose this system helps you earn $10 million a year. How much would you be willing to pay the provider? $20 per month?
The Old “Lowest Common Denominator” Software Design
Should systems adapt to users, or should users learn to adapt to systems?
In the past paradigm, the answer was almost taken for granted: users must learn the system.
From the moment you first encountered Microsoft PowerPoint or Microsoft Excel, you were already adapting to the logic of software—where the buttons are, how menus are structured, how functions are combined. It often takes a significant amount of time to learn. The same applies to Adobe Photoshop, as well as various CRM and ERP systems.
At a private level, I refer to these as “lowest common denominator software.” It may sound slightly ironic, but it is actually quite accurate. Because their business model determines that they cannot serve you too well as an individual. Their goal is not to serve one person exceptionally well, but to ensure that millions—or tens of millions—of users feel that the product is “good enough.”
Their optimal strategy has always been:
serve more people, not serve any one person better
The Old System Paradigm
Under this framework, our understanding of “systems” has been highly consistent:
Systems are built around two things:
data input
data processing
Whether ERP, CRM, or any business software, their essence is the same:
compress the real world into data → store, compute, and display it
This has been the foundational capability of software—and the core of the software industry for decades.
The Shift: Data Processing Is No Longer Scarce
Today, this foundational layer is undergoing a critical downward shift:
local models are becoming usable (e.g., Ollama)
cloud model costs are continuously decreasing (e.g., APIs from OpenAI)
compute and storage costs keep dropping, driven by companies like NVIDIA
development barriers are rapidly lowered by frameworks, open-source ecosystems, and AI-assisted coding
As a result:
data processing is shifting from a scarce resource to infrastructure—like electricity
It is no longer a true competitive advantage.
The New Layered System Structure
Once this layer commoditizes, systems begin to grow upward into a new structure.
Bottom layer
Still data input, storage, and computation—but now commoditized and no longer core differentiation.
Middle layer (emerging)
context modeling
long-term memory
structured decision pathways
This is where AI begins to create real value:
not by compressing complexity into a few metrics,
but by participating in decision-making within rich, evolving context
Upper layer (deeper leap)
A cross-temporal, even cross-generational cognitive system
This is a system that persists over time. What it carries is no longer just data, but the accumulated context assets of an enterprise, a family, or an individual.
For high-net-worth individuals and small organizations, this means that for the first time, systems can continuously capture and accumulate real, valuable cognition.
A New Possibility
When computation, models, and storage are no longer constraints, something previously unimaginable becomes possible:
systems can persist over time and continuously absorb context—beyond the lifecycle of any individual
Such a system is no longer just a tool. It becomes an evolving structure:
it records every decision
accumulates both success and failure
solidifies rules and preferences
gradually forms a structured cognitive system
More importantly:
this system no longer disappears when a person leaves
it can be inherited, understood, and further evolved by the next generation
At this point, systems fundamentally shift:
from tools that assist humans → to long-term carriers of cognition and decision-making capability
This transformation is enabled by three conditions:
Storage is cheap enough → everything can be preserved
Models are powerful enough → semantics and context can be understood
Compute is ubiquitous enough → systems can run continuously
High-Value Demand for Custom Systems
High-net-worth individuals, high-value small enterprises, and organizations with strong privacy requirements—especially in Western Europe and North America—are naturally becoming the first adopters of custom-built systems, capturing a significant portion of high-value market demand.
This is driven by a simple reality:
Their decision value per instance is extremely high
investment decisions can swing millions or even hundreds of millions
legal decisions directly impact risk and liability
family-level decisions affect wealth inheritance and structural stability
Even a small improvement in decision quality can generate returns far exceeding the cost of the system itself.
Why They Reject Standard Software
These groups are fundamentally incompatible with “lowest common denominator software.”
Existing general-purpose software has never truly entered the decision layer.
At the same time, their tolerance for data leakage is extremely low:
They hold:
non-public asset information
trading strategies
family structures and trust arrangements
highly sensitive business data
In this context, handing data over to platforms is itself a significant risk.
The Emerging System Form
As a result, a natural evolution is occurring:
local deployment
private models
strict data isolation
minimal reliance on public cloud
The Cost Barrier Is Falling
Historically, custom systems were rare because:
high cost
complex maintenance
high technical barriers
But now:
AI significantly reduces development cost
open-source ecosystems and local models reduce technical barriers
declining hardware costs further compress total investment
Therefore:
the cost of custom systems has dropped into a range that these groups can accept—and even proactively invest in
Why Western Europe and North America Lead
This trend is amplified in Western Europe and North America because:
long-standing institutional protections around privacy and data rights
mature family office ecosystems
cultural willingness to pay for control and certainty
The Final Shift
This will not eliminate large platforms or big tech.
But it will create a clear divide:
a portion of the most valuable users will no longer be “users of platforms,”
but will become owners of systems.
So the direction I truly believe in—whether you are building a system for yourself or creating an AI system for small businesses that can actually operate in the real world and participate in decision-making—must start from the ground up. The key is still one thing: it has to be useful. This is not a problem that can be solved by simply applying existing paradigms. It is filled with countless details, engineering trade-offs, and structural design decisions—especially when it comes to the practical implementation of context engineering, where there is almost no established playbook. You have to step in and explore it yourself.
Let’s return to a few fundamental judgments: localization, data privacy, and system control. If we use something like ten Mac mini devices to build a fully headless, self-controlled cluster of computing nodes—where both hardware and software are controllable and evolvable—we are essentially asking a deeper question: what kind of system capability can you truly build for yourself or your clients?
And this is not just about Mac minis. The entire technological environment is becoming more cost-effective: IoT devices, edge computing nodes, and various sensors are all dropping in cost. This is pushing the barrier for building complex systems down from enterprise-level capabilities to something individuals and small teams can now afford and execute. Hardware is getting cheaper, and development barriers are getting lower. More and more people will start to consider building private systems.
Under these conditions, if you insist on principles like localization, privacy-first design, system resilience, and extreme personalization—how far can you actually go? How reliable can your system become? And what kind of real value can you deliver to your clients?
Reliable data input is only the most basic layer. The real question is: how deep into the context can you go to support decision-making for a specific user? How much information can you uncover that generic SaaS systems simply cannot capture? And can that information be directly translated into economic value?
In fact, more and more individuals and organizations are already using large language models (LLMs) to assist with—or even directly participate in—decision-making. Within the current cloud-based model paradigm, given sufficient context, their reasoning and comprehension abilities within a single conversational window are already quite powerful.
But the problem is that this kind of “in-window decision capability” cannot directly support long-term, real-world operations. Real businesses—especially those aiming for stability and continuity—depend not on one-off judgments, but on a set of reusable, traceable, and enforceable procedural mechanisms. These include things like evidence sources behind decisions, clearly assigned approval responsibilities, and proper document archiving and version control.
Once these critical elements exist only within a conversation window, they disappear as the context scrolls. They cannot be accumulated, audited, or reused.
Therefore, what truly enables AI to enter real-world decision systems is not just the capability of the model itself, but a stable, structured, and auditable system that can carry, solidify, and orchestrate these decision processes. Only when these processes are structurally preserved can AI evolve from a “tool that talks” into a system that participates in responsibility.
More on the technical side in the next piece—I’m still exploring this myself.
前言
AI 原生项目的起点,只能是两个字:有用。
但这里的“有用”,并不是吸引注意力,也不是生成大量看起来聪明却对现实毫无影响的内容。真正的“有用”,是它能不能进入一个真实场景,被企业、个人、家庭或组织真正用起来;能不能嵌入日常运作,甚至在某些关键环节中,承担一部分真实的风险与责任。
为什么我们现在会如此依赖、甚至“黏”在 AI 的窗口上?本质原因是——你感觉它“懂你”。而这种感觉,并不是错觉,它来自大语言模型的一个核心机制:基于个人上下文的生成能力。
这也让我们隐约看到一个方向:AI 真正强大的地方之一,在于极致的个性化能力。当然,它本身也很强——推理能力,以及基于全人类语料训练出来的某种“近似全知”。
今天的 AI 公司,其实已经在利用这一点:通过调节模型的“温度”和交互方式,让你更强烈地感受到“被理解”,从而提升用户粘性。这本质上是一种商业策略。
但我认为,一个更重要、却被忽视的趋势正在出现:对“极致个性化系统”的真实需求,会逐渐生长出来。对于越来越多的人来说,拥有一个高度隐私化、可靠(甚至不会一味迎合你)、具备理性判断能力的辅助系统,将变得重要。
这样的系统,很可能具备几个特征:本地化运行、数据私有、具备韧性,甚至在某种程度上可以脱离互联网与云服务而独立存在。因为在一个日益不确定和动荡的世界里,你很难保证关键基础设施永远稳定——比如哪一天,海底光缆真的出了问题。
接下来,我会一步步拆解我是如何推导出这套判断的,并在下一篇文章中,具体讲清楚我正在设计的这种系统,究竟会长成什么样。
去全球化的世界,AI,一个时代的开始
2026年,我们作为成熟的个体,我认为不应该再为AI的新闻一惊一乍。甚至这个世界似乎也变得更加动荡了起来,全球化叙事的结束,局部战争的开启,中东的战争逐步升级,世界开始变得不安。一切都在颠覆我们作为二战后稳定繁荣一代的预设环境。去全球化这个概念很重要吗?很重要,也许30年以后你会发现那个时间点所有已经成为环境的起点来自去全球化。我会在后面说明为什么我认为这个起点也是我会选择数据本地化和隐私化作为方向的原因。
毫无意外,在这个年代,如同人类历史上无数次在资本主义环境下发生的变革,技术的迭代到来了。没错,人类的科学与技术,在动荡,残酷的年代,似乎发展的更快(每次大战似乎都推进了技术飞跃)。
说回来我的核心,我要问你几个问题:
AI的市值是否存在巨量泡沫?AI技术是否等于AI公司?
技术价值与股票市值是否绝对等价?
能力的实现是否等于价值的实现?
我相信你已经有了答案:
哪怕现在这些顶流AI公司,比如OpenAI 因为无法实现盈利而破产,我们也可以相信这项技术已经永远的改变了人类的科技树;
AI技术 ≠ AI公司。技术趋势不等于商业成功。AI公司是普通商业实体,可以亏损、破产、失败。不应将技术与公司绑定。
我们已经理解了首先出现的普遍AI形态,即大语言模型。然而,AI还没有真正的进入生产力和生产关系,我们还属于“落地能力”的探索阶段,这也是我为自己制定的一条关键准则,这也是我未来写文章,Youtube等一切向外联系的原动力;
AI尚未真正落地,尚未进入生产力与生产关系。“如何落地”是关键问题,比模型能力更重要。需要寻找认知共同体,需要圈子/群体来共同探索。什么叫落地?我认为必须是“现实中真的有用”。承载责任,金钱,改变物理世界。
并且我们在理解这个初始形态的过程中,也醒悟了过来,就是**目前的以大语言模型为主的形态绝对不是万能的。**既然他不是万能的,那么作为个人程序员就还需要自主探讨。而且因为他真的不万能,所以他现在并没有真正的变得“有用”。
到底什么样的科技范式才能让AI“落地”(有用):单纯在符号世界循环不等于有用。
你以为你现在天天泡在窗口里,你以为你理解了,但是你没有,你只是暂时把这个技术用上了。这并不是人类第一次面对一种几乎无法被当下理解的技术范式困惑,相反,每一次真正的技术跃迁,都会在早期制造类似的认知真空:旧有经验失效,新结构尚未显现,大多数人只能用过去的框架去解释一个本质上已经不同的世界,从而在无形中放大误判。
我就此问个问题,你可能已经发现了:
一个人把一个20万字的文档用AI总结成了5000个字,另一个人在网上看到了这5000个字,然后自己又把这5000字用AI扩展成了20万字。这里面产生了什么价值?
当然,你可以说用AI总结和扩展的这两个人,都分别获得了自己的理解。这当然是一种个人知识价值的实现。但是你总感觉这里面缺少了什么,是什么呢?我认为在这个信息爆炸,内容根本不缺的时代,符号在系统内循环,但重要价值没有随之产生。符号需要绑定到现实结构(决策、行动、系统)中。
信息的价值,不取决于长度或复杂度,而取决于它是否跨越了“符号世界 → 现实结构”的边界。
现在有大量符号在赛博空间中,以一种信息爆炸的模式在“无价值空转”。
从Web 1.0 时代到Web 2.0时代:其实我们是完成了符号跨越现实的
Sad truth: 当前主流AI,反而还没有达到Web 2.0的层级。
从Web 1.0走向Web 2.0,人类其实完成了一次极其关键的跨越:符号第一次大规模地穿透并改造现实世界。在Web 1.0时代,互联网主要承担的是“表达与展示”的功能,信息被数字化、被传播,但它仍然停留在描述层;而到了Web 2.0,以Facebook为代表的社交网络开始让一条简单的信息不再只是被阅读,而是能够直接触发真实行动:你发布一个需求,可能真的就找到了附近的保姆;在约会平台上匹配到的人,我认识的,就有人通过这种方式走入婚姻,十年后仍在一起并育有子女;而像Alibaba Group这样的电商平台,则将这一能力推向更宏观的层面,一次线上订单可以直接调动跨区域的生产、物流与支付系统,进而重塑了全球贸易的运行方式,并在中国形成了今天我们所看到的高度整合的全产业链结构。在这一阶段,符号成为了现实世界的触发器与调度接口。一段数字指令,可以引发一连串真实的资源配置、关系建立与物理行动,这种“从表达走向执行”的跃迁,才是互联网真正改变世界的地方,也构成了我们理解后续一切技术范式的关键参照。
许多AI创业团队,在大语言模型横空出世之后,照搬Web 2.0模式。但是沿用的是“生成式逻辑”,大多在24个月之内失败。为什么?
在大语言模型横空出世之后,许多AI创业团队几乎本能地选择了沿用Web 2.0的成功路径:以平台为中心、以用户规模为目标、以内容为产品,试图复制当年由Facebook或Alibaba Group所代表的增长逻辑。然而,它们在底层却引入了一个根本不同的核心能力——“生成式逻辑”,即通过模型不断生产文本、图像、视频或代码,把符号的扩展当作价值本身。
这就造成了一种结构性错位:外层是Web 2.0的分发与规模叙事,内层却是停留在符号空间自循环的生成机制。结果是,这些产品可以快速吸引注意力、制造增长幻觉,但很难真正嵌入现实的生产与决策结构,无法形成可持续的价值闭环,因此大量项目在大约24个月内便走向衰退甚至消失。
很奇怪是不是?facebook是无数人,自己生成大量关于自己的叙事符号,通过这种符号来互相链接。Alibaba是你说你自己有什么产品,让别人来买;YouTube呢,就是你自己拍视频,让别人看,也是自己生成啊,怎么都成功了呢?
一点都不奇怪,表面看它们都是“自己生成内容”,但本质差别在于:这些平台生成的符号,背后都绑定了真实约束,并且能够触发现实行为,而不是停留在符号内部循环。
以 Facebook 为例,人们确实在“生成关于自己的内容”,但这些内容并不是虚空的,它们绑定的是真实身份、真实关系、真实社交网络,一条信息可以带来真实的联系、合作甚至生活安排,本质是“符号 → 关系 → 行动”;再看 Alibaba Group,商家发布商品信息,看似也是“生成内容”,但每一个商品背后都对应库存、工厂、物流、资金流,一次点击直接触发跨地区的供应链运转,这是“符号 → 交易 → 生产”;再比如 YouTube,创作者上传视频虽然是内容生产,但背后连接的是广告系统、收入分配、职业路径,甚至影响现实中的消费决策与文化传播,是“符号 → 注意力 → 资源分配”。
所以它们成功的关键,不是“用户在生成内容”,而是:
这些符号都被强制绑定在现实结构上,并且可以被执行。
而今天很多生成式AI的问题在于:
生成的内容不需要真实身份
不需要对应真实资源
不会触发真实交易或行动
也很难被验证或约束
于是变成:
符号 → 符号 → 符号
一个封闭系统。一个符号世界里的无限细胞分裂。没啥现实作用,除了赚Youtube这类平台的钱之外,纯属口嗨。
我认为这就是一个“生成式陷阱”
成功的系统,不是让人或AI“说更多”,而是让“说出来的东西能改变世界”。
我们在用 Web 2.0 的成功路径(内容→用户→规模)
去解释 AI 这种完全不同的能力(符号生成)
这会导致一个系统性误判:
以为“生成更强 = 更接近落地”
那么我认为真正能落地的形态至少具备什么特征呢?那么用最通俗的说法来概括就是“有用”。要么对你自己,个人,家庭有用,虽然他不直接产生经济效应。要么就对一个企业的经营管理“有用”,甚至能直接靠省去人工,承担责任,指导决策这种管理功能产生经济效应。甚至是能给个人提供可靠决策,最后这个决策能创造价值,比如投资决策。这种AI原生系统,必须:
1)不可随意生成(Bound by constraints)
有真实数据 / 状态 / 权限限制
不是随便编,一切能追溯到确实的证据,比如原始单据。
2)有后果(Consequential)
输出会影响决策或行为
有成本、有风险
3)可被验证(Verifiable)
可以被现实反馈检验
对错不是“看起来像不像”,而是“结果如何”
而且短期内,输入一模一样的信息,有信心得到相同的结果
如果AI无法用于决策,对于我个人来说,我都想不到对我还能有什么重要用处。生成式的文字和视频,不当网红也没啥用。所以AI的唯一一条真正“落地”的道路,我认为只有“嵌入现实“和“辅助决策”这一条路。
你还记不记得一开始AI公司给我们画的大饼?你要么靠吸粉赚钱,要么就只能靠创造价值赚钱。
OpenAI 创始人Sam Altman 至少在几年前常说:AI将使“一个人公司(one-person company)”达到过去只有大型团队才能实现的规模,甚至做到10亿美元级别(独角兽)。
好,先不辩论这个预言的可能性,如果可能,怎么实现?一个人可以拥有过去需要团队完成的能力,代码,营销,推广,管理,决策。这个没问题,问题是靠什么项目实现?其实按照我刚才提出的Web 2.0逻辑,在这个模式之下其实是有公司达到使用极少的开发+运营人员,撬动极大的产值的: Only Fans!
根据Only Fans 2024年的营收,公司在支付了创作者的收入之后的公司的20%提成部分为$1.41 Billion, 利润(税前):约 $684 Million. 而核心运营人员只有40-50人。
这是一个典型的Web 2.0 平台逻辑,仍然是“内容商品”,仍然是“注意力变现”,对不对?唯一让他特别的,与其他平台,共享经济不同的一点在于内容是”灰色产业“。人类最古老,也最赚钱的行业(无本生意)之一。按照Sam Altman的逻辑,如果靠类似的逻辑,一个人创造独角兽变现类似的平台,靠全球吸粉,抽成,那么你这个“灰度“难道还能超过Only Fans吗?估计也只有把这里面的“内容贡献者”变成AI了,把人家那80%的分成给赚了。
你有没有怀疑过除了Subscription订阅,打赏,内容广告,这种收益的模式之外,计算机,AI,目前我们互联网网络,是有另一种“收益”的方式的。如果不靠广大的用户,不靠人海来给你钱,你如何创造价值?信息本身是否能有价值?
有啊,早就有了,不信你去问贝莱德。甚至有传言说Aladdin早就是AI,但是我本人不相信阴谋论。
所以我想表达的是什么呢?当我们跳出 Web 2.0 的思想钢印去重新思考问题时,一个更根本的问题就出现了:如果不靠“人付钱”,系统还能不能创造价值?大多数人的默认前提是“收益 = 用户付费(订阅 / 广告 / 打赏)”,但这其实只是一个“价值转移模型”,也就是用户把钱转移给平台,平台通过抽成获取收益,本质上并没有创造新的价值,OnlyFans 只是把这种模式做到极致而已;所以真正值得问的是:有没有一种不是“转移”,而是“创造”的收益方式?也就是说,不靠规模、不靠流量、不靠人海,而是系统本身直接产生价值;答案是有的,而且这恰恰是 AI 时代最核心的变化,但它不是信息变现,而是“决策 → 行动 → 结果”的变现逻辑;如果我们把现有模式拆开来看,第一类是信息变现(Web 2.0):内容给用户,用户付钱,本质是卖信息;第二类是工具变现(SaaS):工具给用户,用户用工具赚钱再分一部分,本质是卖能力,但不参与结果;而第三类,也就是在AI还没有横空出世之前,世界顶级玩家贝莱德的Aladdin早就在玩的:结果变现。系统参与决策、参与执行,并直接产生结果,收益来自结果本身,而不是用户付费本身;如果顺着这个逻辑往下推,那么 AI 最大的价值就不再是吸粉,不再是生成无限内容,而是开始进入“决策层”,直接参与价值的创造过程。
如果AI要让企业/个人的在现有的技术上更进一步,那么必须进入决策环节。什么是决策?你常玩的那个不是,那只是优化。
这个问题其实非常抽象,我也是最近才慢慢意识到,而且很难准确表达清楚。我们可以先从一个大家都很熟悉的东西说起,比如一类经典的 NP-complete 问题,像 Traveling Salesman Problem,这不是计算机科学里最经典的问题之一吗?
以前如果有人给一家物流公司做一个类似 TSP 的系统,大家都会觉得非常厉害,因为它的定义很清晰:在 N 个城市中,找到一条最短路径,每个城市只访问一次;但它的难度在于组合爆炸,城市数量一旦增加,可能路径数呈指数级增长,10 个城市还可以处理,50 个就已经极其复杂,100 个基本上人类完全无力,这类问题既经典又实用,也很容易让人产生一种专业感——仿佛能解决这些问题,就代表你掌握了“决策能力”;
我自己以前也是这么认为的,前一段时间写过一篇文章,用来分析和求解类似 Mastermind 这样的 NP-complete 问题,当时也觉得这就是在做“决策”,但现在回过头来看,其实那只是“优化”,而不是决策本身;为什么这么说?因为所有 NP-complete 问题都有一个隐藏前提:只要你已经能够把问题完整定义出来,它本质上一定是一个“封闭世界问题(Closed World Problem)”,也就是说所有变量是已知的,规则是固定的,目标是明确的,问题可以被穷举或近似求解,换句话说,这些问题虽然计算上很难,但有一个关键前提——世界是完整的。
真正的现实多层次,极复杂
而现实生活恰恰完全不是这样,你每天真实面对和去解决的真正决策,比如孩子的教育、注意力问题、沟通能力问题,你需要综合老师反馈、测评报告去安排课外活动,同时还要把这些安排和你的工作、家庭事务、另一个孩子的时间协调在一起,还要考虑成本、距离、精力分配,再比如税务决策,今年卖不卖某只股票会如何影响税负,抵扣额度怎么用,这些决策涉及的不只是数字优化,还包括大量模糊、动态、甚至无法量化的变量,而这些变量在过去是根本无法被纳入“计算问题”的范畴的;也就是说,计算机科学传统上处理的,是那些已经被定义好的问题,而现实生活中的决策,真正困难的地方恰恰在于:问题本身并没有被定义清楚。
真正的决策发生在优化之前
公司的决策其实也是一样的逻辑,你去给那家物流公司做 Traveling Salesman Problem 算法,看起来是在解决一个很复杂的问题,但本质上对方只是把最简单、最干净的“优化问题”交给了你,而真正的“决策”早在这之前就已经发生了;如果我们把一个真实的物流问题拆开来看:TSP 解决的是在给定订单集合、给定约束条件下,找到一条最优路径,但真正的决策是在更前面的层级——比如哪些订单要接,是否需要拆单,哪些可以延迟,是否要提高价格来筛选需求,是否要调整仓储布局,甚至是否要放弃某些区域,这些问题没有固定的目标函数,没有明确的输入,也没有标准答案,它们涉及的是不完整信息、多目标冲突和动态变化的现实环境;而你之所以能拿到一个“可以用算法解决的问题”,恰恰是因为那个学 MBA、经验老道的物流公司老板,已经在你看不见的地方把真正复杂的部分处理掉了,他已经帮你完成了变量筛选、目标定义和结构约束,把一个混沌的现实问题压缩成了一个封闭、干净、近乎完美的数学问题,然后才交到你手上,这时候你解决的再漂亮,本质上也只是“优化”,而不是“决策”,但因为这个问题在形式上足够复杂、计算上足够困难,就很容易让人产生一种错觉,好像自己在做的是核心智能。
所以真正的问题,在于以前我们的计算机世界过于“干净”了,其实是一种低能的表现,强制把复杂的世界压制成“可工程化”。因为机器无法理解语义,只能执行确定性的逻辑规则,因此所有问题都必须被提前定义、结构化、边界化,才能进入计算系统;但真实世界本身是多层次、非完备、充满模糊与冲突的,一旦机器开始具备理解语义的能力,这道原本隔离“现实复杂性”和“计算系统”的墙就被打破了,那么整个计算世界的基本逻辑也就不再成立,不再只是处理已定义问题的工具,而必须转向处理问题生成与结构定义本身,这实际上意味着一次彻底的范式重构。
这个世界充满了真正复杂和有价值的问题,而且无法被简化成计算指标
而强制压缩这些问题,只会让真正能够承载复杂型的系统更有价值。因为人类算力的局限,以前我们把决策问题压缩成优化问题。举一个中国人都很熟悉的例子,对于英文观众,我相信也能很快理解:那就是KPI → 把复杂目标压成一个数。
KPI大家都知道了,那么一个国家的KPI是什么呢?对于在过去30年高速发展的中国来说,国家的KPI就是中国的GDP优先主义。沿用我刚才跟你阐述的逻辑:
GDP 是一个被压缩后的优化目标,而民生是一个未被正确建模的决策问题。
首先GDP需要被放回它原本的位置,即 Gross Domestic Product 只是一个统计指标,而不是目标本身;但一旦进入治理体系,就会发生一个关键转换:复杂的社会现实被压缩成一个数字(GDP),再被设定为KPI,进而成为优化对象,于是整个系统被重构为一个“优化问题”。
而所谓 GDP 优先主义,本质上就是把原本复杂的决策问题强行压缩为一个可计算的优化问题,因为原始问题其实是多维且不完备的,比如人过得好不好、是否有安全感、是否对未来有希望、社会结构是否健康,这些都是典型的决策问题,具有多目标、不可完全量化、缺乏统一评价标准的特征,但一旦转化为“GDP 必须增长 8% 或 5%”这样的目标,系统就被简化为单一目标优化;这种压缩之所以被广泛采用,是因为它带来了明显的工程化优势,比如可量化、可比较、可考核、可执行,使治理具备操作性,但其代价同样明显,即大量关键变量被丢失,例如贫困的质量而非仅数量、医疗保障的真实可达性、家庭结构问题(如留守儿童)、青年人的心理状态与未来预期以及生育意愿,这些变量往往难以量化、缺乏统一标准且无法在短期内反馈,因此被系统性地排除在优化目标之外;最终,这会导致一个结构性问题,即系统出现“理性偏移”,因为当GDP成为KPI时,所有行为都会围绕这一指标展开,例如优先投资高回报项目、忽视长期但不计入GDP的因素、忽略分配结构以及个体体验,最终导致优化的对象不再是现实本身,而只是指标;这正是所谓的 Goodhart’s Law 所揭示的现象,即一旦一个指标成为目标,它就不再是一个好的指标,其根本原因在于指标原本是用来反映现实的,但一旦成为驱动行为的目标,现实反而开始围绕指标被系统性地扭曲。
所以什么才是有用?就是让现有的系统能够承载更多的复杂性,做出更有层次的决策。而这个决策不会轻易的被压缩。看上去是做同样的工作,但是延迟压缩,甚至拒绝过早压缩。它会保留上下文、保留分歧、保留不确定性,让系统在更高维度上运行,再在必要时做出决策。这个进步就巨大了。
所以读到这里,我想表达的其实很简单:世界已经在发生结构性的变化,逆全球化不再是偶然事件,而是一种正在展开的趋势;AI也将永久成为技术体系的一部分,但它的价值不在于炫技,而在于“有用”——必须贴近现实、参与决策、嵌入具体系统之中。而且因为人类第一次,“机器读懂了语义”,所以我们许多在计算机应用的工程哲学需要改变。能够读懂语义的计算机,可以开始承接一些真实世界的复杂性,可以不需要过度压缩成指标或者KPI。顺着这个逻辑往下推,会得出一系列现在听起来有些反直觉、但实际上极其自然的结论。之所以显得反直觉,是因为我们这一代人是在全球化、长期和平、效率至上,以及“互联网=计算机”的范式中成长起来的,是在Excel表,ERP这种被高度结构化提炼但是同时又损失大量真实世界的复杂层次的抽象中走过来的。这些环境在我们心中形成了深刻的思想钢印。而下一阶段,恰恰会逐步瓦解这些默认前提:计算机将慢慢变得“像人”,承载人类的世界的复杂性。数据将走向本地化与私密化,系统将以韧性为核心目标,而真正有价值的服务,将不再追求普适性,而是走向极致的个性化。下面我依次推导我的这些观点。
AI 时代计算机界出现了一个超级变量:上下文context
AI引入了一个全新的超级变量,多年以后我们会把这个写到教科书里:
上下文(Context)
长期使用AI的人,应该对这个词不陌生,而且这个词也已经深度和大语言模型绑定了。
这个概念本身是非常抽象的,而更大的问题在于:我们的思维,已经被手机、互联网、SaaS 这一整代计算范式深度塑形了。很多认知不是你“理解”出来的,而是长期使用系统之后形成的结构惯性。想要真正适应 AI 的到来,甚至基于它创造出更强的系统形态,本质上需要对这些根深蒂固的假设进行拆解,而这件事不可能一蹴而就,它需要时间,也需要探索。
我举一个最简单但极其关键的例子。
在你熟悉的计算世界里,一部手机上有无数个 APP,它们彼此之间是天然割裂的。哪怕是在同一家企业内部,这种割裂也依然存在:会计部门使用一套系统,市场部门使用另一套系统。而当你在市场系统中做决策时,你无法直接调用会计系统的能力。你能获得的,只是会计部门整理好的结果,例如上一季度的财报分析。从某种意义上讲,这其实就是一种“人肉 API”。也就是说,我们今天所习惯的系统形态,本质上是:
默认隔离、天然断裂、彼此不理解
而且这是当时技术条件下的“最优解”。因为在前 LLM 时代,“上下文”甚至还不是一个被严肃对待的工程变量。于是整个系统世界被构造成这样一种结构:
每个系统维护自己的数据模型
每个系统封闭自己的边界
系统之间通过接口(API)进行极度压缩的信息交换
而在绝大多数真实场景中,这种交换甚至无法自动完成,只能依赖人工在 PDF、Word、Excel 之间搬运
结果就是:
在同一家企业内部,无论规模大小,没有任何一个系统能够看到:
完整的“决策上下文”
而 AI 的出现,第一次让这件事出现了裂缝。
LLM 可以处理未被压缩的语义上下文创造一种 跨系统的“上下文连续性”
理论上,你可以构建这样一个系统:
同时理解财务数据、用户行为、市场策略与风险约束
在同一个语义空间中整合这些信息
并基于此进行决策,而不是依赖被切割后的结果
但问题在于,我们目前还远没有走到这一步。我们大多数所谓的“AI 应用”,实际上仍然停留在一个非常初级的阶段:
把上下文当作 prompt 进行拼接
而没有真正进入下一层:
把上下文当作一等公民(first-class object),去建模、调度、隔离与演化
也就是说,我们已经看到了方向,但还没有建立语言、结构和工程体系去承载它。这中间的断层,才是接下来几年真正值得探索的地方
简单粗暴的认为“把上下文拉长”或者把所有的割断打通“都是不可行的
所以我认为,“上下文工程”未来会成为一个极其关键的应用领域。因为无论是简单地把上下文不断“拉长”,认为只要 LLM 能处理更长的上下文就足够,还是试图彻底打通系统之间的所有割裂,这些做法本质上都是粗暴的,它们都无法真正承载现实世界中的复杂系统。在我看来,这个领域仍然处于一片未被充分理解的状态,我们甚至还没有建立起清晰的工程范式。“把上下文拉长” ≠ “理解上下文”,“打通系统” ≠ “可承载现实系统”。
很多人下意识地认为 AI 的进步等同于上下文窗口变长、模型能看到的信息更多、系统之间不再隔离:只要上下文足够长,系统就会变得更智能。但这个结论是错误的。任何真正运营过企业、处理过现实复杂度的人都会意识到,问题远比这复杂得多。因为上下文从来就不是一个“长度问题”,而是一个“结构问题”。
如果你把所谓的“无限上下文”想象成一个系统,它更像是一个没有索引的数据库、一个没有结构的知识库、一个没有优先级的记忆系统。在这样的系统中,首先会发生的是信息噪声的爆炸:相关与不相关的信息混在一起,模型只能依赖概率去“猜测”什么重要,本质上缺乏选择机制(selection);其次,决策会变得极其不稳定,同样的问题在不同时间可能产生完全不同的结果,因为上下文的轻微变化就会改变推理路径,这意味着系统缺乏确定性的决策路径(determinism);最后,计算成本会迅速失控,延迟不可预测,系统也无法被工程化部署,本质上是缺乏调度机制(scheduling)。
同样地,我认为“彻底打通系统”也肯定不成。如果你把会计系统、市场系统、用户行为数据乃至私密信息全部汇聚成一个所谓的“超级上下文”,表面上看似统一,实际上却是在走向另一种极端——边界的彻底崩溃(boundary collapse)。一旦边界消失,就会带来一系列连锁问题:权限无法控制、语义相互污染、决策责任变得模糊、系统失去可审计性。这种系统在现实世界中是不可用的。
我们还没有一门关于“上下文如何被构造、选择、调度与隔离”的工程学。
随着我们所处的世界不断变化,LLM 带来的不只是工具层面的升级,而是一整套新的技术范式正在逐步形成。这也意味着,许多我们习以为常、根深蒂固的计算方式与商业逻辑,都将被重新审视。
随着 AI 开始广泛进入真实的生产环境,“上下文”正在成为一种关键的无形资产。在一些高价值且高度私密的领域中,上下文的价值甚至可能超过传统的实体资产。无论是那些积累了几十年,甚至上百年历史的家族企业,其长期沉淀并逐步工程化的经验与知识,还是那些掌握大量核心客户关系与关键资源的知识密集型机构,例如顶级律所和金融机构,这些“上下文资产”的真实价值,都会逐渐被市场所认知和重估。有些企业,家族,团体,非盈利组织,拥有非常有价值的上下文资产,这些资产没有被挖掘出来。我们已经知道 AI对于模式识别的能力,对于隐藏信息的发掘能力。所以数据隐私一定是下一个时代无比重要的企业服务内容。
一旦计算机系统具备了真正承载和利用这些上下文的能力,这些持有关键上下文的主体,将显著提升对数据私密性的重视。在某些高价值场景下,甚至会出现“数据必须完全与互联网隔离”的要求。
与此同时,掌握关键决策信息的个人与组织,也会越来越强调系统的韧性。他们会为那些在过去相对和平与稳定环境中从未认真考虑过的风险,提前建立预案。在必要时,他们甚至愿意主动牺牲一部分“效率”,而不再单纯追求利润最大化。
在这样的背景之下,小公司,甚至极小规模的团队,将获得新的生存空间与竞争优势。整个技术与商业范式,也可能从过去类似“所有人去超市购买标准化产品”的模式,逐步转向一个新的形态——更多人能够使用高度定制、面向个体需求的系统与服务。
本地化与数据私密性
现在你会看到很多新闻,你会看到有人在说“SaaS 已死”;你会看到关于数据可信度的讨论,甚至会延伸到“这个服务商的服务器在哪个国家”,进而变成政治层面的争论;你会看到越来越多的 cyber security(网络安全)事件。而与此同时,你可能还会想:我不过是点一杯奶茶,这种个人级别的数据,有什么隐私可言?但真正的问题是,在 AI 时代,这种“看似没有价值的单体数据”,正在悄悄变成可以嵌入上下文、参与决策的结构性信息。
数据隐私 → 价值归属 → 上下文(context)
为什么“数据隐私”在 AI 时代突然变成核心问题?在 Web 2.0 时代,数据本质上只是行为记录(点击、浏览、购买),其价值来自统计聚合(aggregation),用户是被动提供数据的一方,公司则通过广告或订阅实现变现,关键在于单个用户的数据几乎没有价值,只有规模才有价值;但在 AI 时代发生了一个结构性变化,数据从“记录”转变为“上下文”,而包括医院、投资机构、律所、富裕家庭等高价值主体,将成为最早一批因为数据隐私问题而主动脱离大厂大云、转向本地系统、严格隔离私人数据的实践者,因为这些系统具备三个共同特征:
第一,决策价值极高——医院的一个决策关系到生死、诉讼与成本,投资机构的一个决策可能涉及上亿回报或损失,律所的一个决策决定胜诉或风险转移,家族的一个决策影响资产传承与代际结构;
第二,上下文极其复杂——涉及长周期(几年到几十年)、多角色协作(医生、合伙人、家族成员)以及大量隐性信息(经验、关系与判断);
第三,不可标准化——没有两个医院完全一样,没有两个投资逻辑完全一样,也没有两个家族结构完全一样,这一点直接击穿了 SaaS 的前提;因此这些场景天然排斥“云 + SaaS”,这是结构问题,因为它们的核心资产不再是数据本身,而是上下文,而就在写这篇内容的时候,我已经看到 Palantir Technologies 与纽约医疗系统的合作被拒绝续约,本质原因正是数据隐私与上下文控制权,这类事件只会愈演愈烈,并逐步形成一个背离“大厂大云”的技术与架构转向,而这个方向,在我们这个时代已经具备实际可探索的条件,后续我也会结合自己在本地化系统上的实践,持续展开分析与验证。
大厂时代,大云时代,有一部分会被切割出去。相反一小部分本地化,超个性化需求会从极小的规模慢慢开始尝试崛起。
系统的韧性resilience
继续刚才的说法,大厂与大型云服务商几乎包揽一切的互联网形态之下,正在逐渐出现一批本地化的应用,这是一种理念的变化。很多思维路径比较固定的程序员,会本能地从效率、规模、成本这些熟悉的指标来反驳这一趋势,但这正是问题所在,这也是为什么我在文章开篇选择用“去全球化”来作为解释框架:
如果你坚持用效率与规模来辩论,那么全球化是不是效率最高、规模最大的一种组织方式?答案显然是肯定的,但现实同样告诉我们,即便如此,全球化依然在发生反转。
随着地缘政治的不稳定、局部冲突的增加,以及系统性风险的持续暴露,我们曾经习以为常的那一整套“效率优先”的生产体系、供应链体系乃至工业组织方式,都在开始朝着相反的方向演化,即更加本地化、区域化、冗余化的发展路径。
本质上,这是一种长期被忽视的问题正在回归:我们过去习惯用“优化问题”去掩盖“真实复杂性”,而当外部环境的不确定性上升,这种压缩复杂性的方式就开始失效甚至反噬系统本身。过去几十年,整个工业与互联网体系默认了一个前提——世界是稳定的,因此可以持续优化,在这个前提之下,我们构建了一整套“优化机器”:全球化供应链(just-in-time)、单点最优生产(lowest cost region)、超长链条分工,以及极致压缩的库存体系,但这一切都隐含着一个极其脆弱的假设——不会出事。
一旦这个假设不成立,整个逻辑就会反转:当世界进入高波动与高不确定状态时,原本的最优解反而会变成系统中最脆弱的节点,例如单一国家生产在旧世界中是成本最优,但在新环境中,一旦发生断供,它就直接成为致命风险。这一点映射到互联网与AI同样成立,大厂与大云本质上也是一种“集中化最优解”,但在不确定性不断放大的背景下,我们必须重新问一个问题:系统最重要的目标,还是绝对效率吗?答案显然是否定的,更核心的目标正在转向系统的韧性Resilience。这并不意味着反对云,也不意味着所有事情都必须本地化完成,而是意味着系统设计的优先级正在改变:从单点极致效率,转向在不确定环境下仍然能够持续运行的能力。
这个事情,作为程序员不一定能完全理解,但作为大医院的管理者、顶级律所、以及掌握重要私密客户信息的家族办公室,一定能够立刻听懂其中的意义。因为他们本身就长期处在高价值决策、高隐私、高风险控制的环境中,对“系统是否可控”“信息是否安全”“决策是否可持续”有天然敏感度。
而且现在的情况已经发生了根本变化:硬件能力的普及、软件通用性的成熟,以及 AI 的出现,这些技术条件第一次同时具备,使得这件事不再是天方夜谭,而是一个富裕家庭都买得起、也请得起人来构建的现实系统。也就是说,不仅动机已经成熟——对隐私、控制权和长期决策能力的需求正在快速上升,而且条件也已经成熟——不论是硬件,还是软件技术门槛都在大幅下降,这两者叠加,意味着这个时代已经发生了结构性变化。
与此同时,整个世界的运行逻辑也在发生转移:从过去追求“全球最优”的效率逻辑,转向强调“局部可控”的生存逻辑。过去的共识是最便宜就是最好,哪怕供应链再远、依赖再深也可以接受;但现在的核心判断变成了,系统首先必须能在不稳定环境中存活下来,其次才是效率是否最优。因此我们看到本地化供应链的回归、区域经济块的形成(并非完全脱钩,而是降低依赖)、以及企业主动引入冗余设计,这一切的本质变化在于:系统开始为“失败”设计,而不再只为“成功”设计。
在这样的背景下,一个真正有韧性的系统,其结构也从传统的“中心化控制”转向“结构化去中心”。这里必须强调,这并不是理想主义的去中心化,而是一种工程上的现实选择:系统由多个节点构成,每个节点可以独立运行,在必要时可以断开连接但仍保持基本功能。具体表现为本地 AI 与云的协同、小系统之间的松耦合关系,以及对单一平台依赖的降低。最终的判断标准只有一个:这个系统在脱离网络、脱离中心节点的情况下,是否仍然能够继续运作,也就是系统必须具备“可脱网生存”的能力。
说个最俗最显摆的,这个连我自己家里都在建。你觉得任何有需求的高价值小公司怎么可能没这个需求。
极致个性化
灵魂问题:如果有一套系统,专门为你而设,能帮你决策。这个决策,不管是投资也好,还是做生意也好。反正你最终赚钱了。假设你靠这个系统年入一千万美元,你愿意给这个系统的提供商支付多少钱?20刀月费吗?
最大公约数式软件设计
系统应该去适配用户,还是用户应该去学习系统?在过去的范式里,这个答案几乎是默认的:用户必须去学习系统。你从最早接触 Microsoft PowerPoint、Microsoft Excel 开始,就在不断适应软件的逻辑——按钮在哪里、菜单怎么走、功能如何组合,往往要花大量时间去摸索。再到 Adobe Photoshop,以及各种CRM、ERP系统,本质上都是一样的。我私底下把它们称为“最大公约数软件”,听起来有点调侃,但其实非常贴切。因为它们的商业模型决定了,它们“不能对你这个人太好”,它们的目标不是服务好一个人,而是让几百万、几千万人都觉得“勉强能用”。它们的最优策略,从来都是服务更多人,而不是更好地服务某一个人。
在这样的背景下,我们过去对“系统”的认知,其实非常统一:系统就是围绕两件事情构建的——数据的录入与数据的处理。无论是ERP、CRM,还是各种业务软件,本质都是把现实世界压缩成数据,然后对这些数据进行存储、计算与展示。这构成了软件最底层的能力,也是过去几十年软件工业的核心。但今天,这一层能力正在发生一个关键的“下沉”:本地模型开始变得可用,比如 Ollama;云模型的成本持续下降,例如 OpenAI 提供的API;同时算力与存储成本在 NVIDIA 等推动下不断降低,再加上开发门槛被框架、开源生态与AI辅助编程迅速拉低。于是数据处理能力,正在从一种稀缺资源,变成像电力一样的基础设施,不再构成真正的壁垒。
当这一层下沉之后,系统开始向上生长,形成新的分层结构。
最底层,依然是数据录入、存储与计算,但这一层已经开始商品化,不再是核心竞争力。
往上一层,是正在形成的能力:上下文建模、长期记忆以及结构化的决策路径。也正是在这一层,AI开始真正产生价值——它不再只是把复杂问题压缩成几个指标,而是可以在复杂上下文中参与决策,让决策随着信息不断丰富和演化。
而再往上一层,则是一个更深的跃迁:跨长期、甚至跨代际的“认知系统”。这是一种能够长期存在的系统形态,它所承载的不再只是数据,而是一个企业、一个家庭、甚至一个个体不断积累的“上下文资产”。对于高净值人群和小型组织来说,这意味着他们第一次可以通过系统,持续捕获并沉淀真正有价值的认知。
当计算、模型与存储都不再成为问题之后,一个过去难以想象的可能性开始出现:系统可以持续存在,并不断吸收上下文,跨越个人的生命周期。它不再只是一个工具,而是一个持续演化的结构体——它记录每一次决策,积累成功与失败,固化规则与偏好,逐渐形成结构化的认知体系。更重要的是,这个体系不再随着人的离开而消失,而是可以被下一代继承、理解,甚至在此基础上继续演化。也正是在这一刻,系统第一次从“辅助人”的工具,转变为一种可以承载认知与决策能力的长期载体。
存储足够便宜 → 可以保存一切
模型足够强 → 可以理解语义与上下文
计算足够普及 → 可以持续运行
一些高净值人群,高净值的小企业,私密性要求高的,尤其是来自西欧和北美地区,私人定制的需求会分走市场的一部分蛋糕
一些高净值人群、高净值的小企业,以及对私密性要求极高的组织——尤其是在Western Europe和North America——正在自然成为“私人定制系统”的第一批需求方,并且会稳定地分走市场中一块高价值的份额。这背后首先是一个非常现实的前提:
他们的“单次决策价值”极高。无论是投资决策,可能带来数百万甚至上亿的波动;
法律决策,直接影响风险与责任;
还是家族层面的决策,涉及资产传承与结构稳定,只要系统能够在这些关键节点上提升一点点决策质量,其带来的回报就已经远远超过软件本身的成本。
因此,这类群体天然不适合“最大公约数软件”,而现有的普适软件,本质上也从未真正进入“决策模型”这一层。
与此同时,他们对数据外泄的容忍度极低。这些人群往往掌握着非公开的资产信息、交易策略、家族结构与信托安排,以及高度敏感的商业数据。在这种背景下,把数据交给平台本身就构成了一种不可忽视的风险。因此,一种几乎是必然演化出来的需求开始出现:本地部署、私有模型、数据隔离,以及尽可能不依赖公共云的系统形态。
更关键的是,他们具备承担定制成本的能力,而这个成本本身也正在发生变化。过去定制系统之所以难以普及,是因为成本高、维护复杂、技术门槛极高;但现在,AI显著降低了开发成本,开源生态与本地模型降低了技术门槛,而硬件成本的持续下降进一步压缩了整体投入。于是:定制系统的成本,已经下降到了这些群体可以接受甚至愿意主动投入的区间。
这种趋势在Western Europe和North America会被进一步放大,因为这些地区长期以来就对隐私与数据权利有制度性保护,同时家族办公室(Family Office)体系成熟,高净值个体本身也更习惯为“控制权”和“确定性”付费。因此,他们不仅有需求,而且有明确的支付意愿与文化基础去支持这种系统形态的出现。
最终,这并不会消灭大厂或平台型软件,但会带来一个清晰的分化:一部分最有价值的用户,将不再只是“平台的用户”,而是转变为“系统的拥有者”。
所以我真正看好的方向,无论是为自己构建系统,还是为其他小企业打造一个能在现实中运转、真正参与决策的 AI 系统,都必须从底层开始做起。关键还是“要有用”。这不是一个可以靠“套用已有范式”解决的问题——其中充满了大量细节、工程权衡与结构设计,尤其是“上下文工程”的具体落地方式,几乎没有现成的教科书可以参考,必须亲自下场探索。
回到几个基础判断:本地化、数据隐私、系统控制权。如果我们用十台 Mac mini 这样的设备,搭建一个完全 headless、由自己掌控的计算节点集群,在软硬件都可控、可演化的前提下,本质上是在问一个问题——你到底能为自己/客户构建出怎样的系统能力?
而这背后并不只是 Mac mini 的问题,整个技术环境的性价比都在提升:IoT 设备、边缘计算节点、各类传感器的成本持续下降,正在把“构建复杂系统”的门槛,从企业级能力,压缩到个人和小团队也能承担的范围之内。硬件越来越便宜,开发门槛越来越低。具有私有系统这种想法的人,只会越来越多。
在这样的前提下,如果你坚持本地化、隐私优先、系统韧性,以及极致个性化这些原则,你最终能做到什么程度?你的系统能有多可靠?你能为客户提供怎样的真实价值?
数据录入的可靠性只是最基础的一层。更关键的是:你能在多深的上下文中,帮助这个特定用户进行决策?你能挖掘出多少在通用 SaaS 系统中根本无法被捕捉的信息?而这些信息,是否能够直接转化为收益?
其实,越来越多的个人和企业,已经开始借助大语言模型(LLM)来辅助甚至直接参与决策。在当前的云端模型体系下,只要给定足够的上下文,它在一个对话窗口内所展现出的理解与推理能力,已经相当强大。
但问题在于,这种“窗口内的决策能力”,并不能直接支撑真实世界中的长期运营。企业的运作,尤其是稳定、可持续的运作,依赖的不是一时的判断,而是一整套可复用、可追溯、可约束的程序化机制——比如决策所依赖的证据来源、审批责任的明确归属、关键文件的留存与版本管理等。
这些关键要素,一旦仅存在于对话窗口中,就会随着上下文的滚动而消散,既无法沉淀,也无法审计,更无法复用。
因此,真正能够支撑AI进入现实决策体系的,不只是模型本身的能力,而是一个稳定、结构化、可审计的系统,用来承载、固化并调度这些决策流程。只有当这些过程被“结构化地保存下来”,AI 才能从“会说话的工具”,进化为“可参与责任的系统”。
下一篇继续讲技术。我也在探索中。