
From Build to Build Up: The Real Complexity of Programmers in the AI Era
《从 Build 到 Build Up:AI 时代程序员的真正复杂度》中文在后面

Happy New Year! Taking advantage of the Chinese New Year, I want to turn the chaos and frustration of the past few weeks into a clearer record: on one hand, the real pain points I’ve encountered while developing with AI assistance; on the other hand, the deeper realization I’ve gradually reached about “what programmers are truly meant to solve,” along with some personal approaches I’ve already begun proposing and practicing. Since this is a bit long, I’ll start with an outline:
1) The first major challenge programmers face is how to preserve personal memory in the face of high-throughput code and text generation.
In the past, you might read one page a day—just a few thousand words—and still remember most of it the next day. Now, you might read hundreds or even thousands of pages in a single day, and yet fail to retain even one page’s worth of content. It’s not that you’ve become worse; it’s that throughput has fundamentally changed the physical conditions of “memory” itself.
2) Build vs. Build Up.
Here I want to propose a distinction of my own. Build refers to problems that can be solved within a window—clear boundaries, well-defined goals, stable evaluation functions. Build up, by contrast, is layered on top of Build: stacking one layer after another to tackle open-boundary problems. The complexity of Build up is often unknown, because the boundaries are unclear, goals drift, and as layers accumulate, complexity may not increase linearly at all. This brings us back to the classical definition of complexity in computer science. Historically, complexity was defined under the implicit assumption of the human brain as the computational model. In the AI era, should that assumption change? Consider two extremes: NP-Complete problems versus “toasting bread.” For a model, which is more complex? Perhaps the scale of complexity itself is shifting. Try picking an NP-Complete problem and starting from scratch—you’ll probably get surprisingly close within two hours.
3) LLMs have significantly reduced the energy cost of coding—they compress execution cost—but they have not solved the continuity of decision-making.
The old bottlenecks were slow coding, slow research, slow debugging. Now those frictions are largely flattened. What’s exposed instead is the true dominant cost: decision fragmentation. What really drains us isn’t coding itself, but the countless micro-decisions. Where you once faced two possible paths, you now face two hundred. Time is spent constantly evaluating, choosing, branching—and often without even knowing whether those branches are aligned with the main objective. This, in my view, is the second major challenge for programmers: we must find a way to “automate our own taste.” Taste doesn’t answer “Do I understand this?” It answers, “When I encounter a similar fork again, which direction do I tend to choose?”
4) Returning to the two core problems I care about most: memory and taste.
If these two problems cannot be addressed through scaffolding or tool systems that we build for ourselves, then once in-window Build becomes cheap, the idea that “hundreds of millions of programmers” will emerge worldwide is hardly an exaggeration. If professional programmers cannot move into Build up—if they cannot define problems within open boundaries, design boundaries, and pull parts of the outside world back into the window—they will struggle to build long-term professional advantage. As for me personally, I’ve already explored a workable solution to the memory problem and have alleviated some real pain points in practice. Next, I plan to organize and share it.
My article is divided into four parts: Memory, Build vs. Build Up, Taste, and My Approach.
Memory
Today’s programmers are living through a true transportation shift: from the horse-carriage era to the highway era. The carriage era was slow, visible, and controllable. As you moved forward, you watched the horse—was it tired, veering off, stopping? Everything remained within your perceptual field. The speed was limited, and so was the risk. System complexity and human attention were roughly aligned.
But once you sit inside a car and merge onto the highway, can you still stare at the hood? Of course not—you have to watch the road. The leap in speed doesn’t change the destination—you’re still going from A to B—but it radically changes the cognitive structure required to get there.
In today’s environment of large-scale code and document generation, with a dozen or even dozens of windows scrolling in parallel, information throughput has exceeded human biological limits. If you read one page a day, you’ll probably remember it tomorrow. If you read hundreds or thousands of pages in a day, you may remember none of it. What you read doesn’t stick. The decisions you wrote blur.
The solution is obviously not to return to the era of hand-written code. You cannot drive at 5 km/h in traffic moving at 100 km/h. The real question is: in a reality of high-speed generation, how do you protect and preserve your personal cognitive sovereignty and memory core?
Handing everything over to model-company settings, stitched windows, and opaque black-box memory might be the mass-market path—but it should not be the professional programmer’s choice. Do you really want to entrust your most valuable cognitive assets to a system you cannot audit?
On this question, I borrow Andrej Karpathy’s concept of the “cognitive core.” We must distinguish between a memory stack and an intelligence core. Strip away outsourceable knowledge storage, but retain the ability to decompose problems, judge architectures, recognize constraints, design abstractions, and grasp long-term invariants. Models can generate implementations, but they cannot decide what is worth freezing, what must become constitutional, what is structurally invariant.
In the high-speed era, the programmer’s first great challenge is not writing more code—it is safeguarding their cognitive core within the flood of generation. That core is the steering wheel, not the engine hood.
“What I think we have to do going forward … is figure out ways to remove some of the knowledge and to keep what I call this cognitive core. It’s this intelligent entity that is stripped from knowledge but contains the algorithms and contains the magic of intelligence and problem-solving and the strategies of it and all this stuff.”
— Andrej Karpathy (2025 interview)
Strong Structure, Weak Model
Before discussing memory engineering, I need to introduce a methodological stance I’ve gradually formed through practice: strong structure, weak model.
This is not anti-model, nor technological conservatism. It is a layered systems philosophy: the model belongs in the position of a capability plugin, not the cognitive foundation. Models can be powerful—but the system must not depend on them being “smart enough.” What sustains long-term development, accumulation, and stable operation is structure.
Any task can be decomposed as:
Task Complexity = Essential Complexity + Accidental Complexity
Essential complexity comes from the problem itself—it cannot be eliminated.
Accidental complexity arises from representation, execution methods, tool instability, semantic drift, and environmental variation—it can be compressed or eliminated through structure.
The core of engineering is not reducing essential complexity. It is relentlessly eliminating accidental complexity.
A Simple but Illustrative Example: Prime Testing
The essential complexity of determining whether a number is prime is mathematical evaluation.
If you approach it with weak structure—asking an LLM to reason step by step—the model must understand what a prime number is, choose trial division, determine optimization strategies, and maintain logical consistency in natural language reasoning. All of this uncertainty belongs to accidental complexity. The model may skip edge cases, miscalculate, jump steps, or produce different answers depending on sampling parameters.
You have transformed a deterministic algorithmic problem into a probabilistic inference problem.
In contrast, with strong structure, you simply write is_prime(n), explicitly define boundary conditions, loop limits, and divisibility checks. The remaining complexity is purely essential. Structure absorbs and eliminates accidental complexity. System stability moves from “probably correct” to “necessarily correct.”
Counting Beans: A Personal Example
My son’s preschool teacher once required him to bring exactly 100 beans to school. Counting by hand was tedious, so I tried asking a model to help. The model miscounted.
Why? Because models are not designed for pixel-level deterministic counting. They perform pattern recognition and semantic prediction, not discrete precision counting. Assigning such a task to a model manufactures accidental complexity.
If your structural layer defaults to:
Encounter counting task → call OCR or specialized counting tool → return deterministic result
the problem immediately becomes a tool-invocation issue. Professional tools are designed for determinism, not plausibility.
Structure isn’t intelligent. It’s reliable.
When large models first appeared, many of us fell into a “universal illusion.” We believed that with sufficiently clever prompts, models could replace algorithms, structure, and architecture design. People memorized prompts, studied prompt books, debated temperature and roles.
Gradually, disillusionment set in. We realized that LLMs do not reduce essential complexity. They implicitly take on accidental complexity—and they do so probabilistically. When you hand algorithmic tasks to models, you are increasing volatility. Using LLMs for deterministic tasks is often slower, more expensive, and less stable.
“Making the model smarter” does not mean “making the system simpler.” Often, it merely shifts complexity from code to semantics—and the semantic layer is not auditable.
Prompt Engineering vs. Structure Engineering
In an era where scaling laws may be plateauing, we must carefully reassess how we deploy models. The fantasy that programmers would collectively become obsolete—replaced by language virtuosos who could “prompt the world into submission”—belongs to a magical narrative, not engineering reality.
In my framework, structure means hard code.
From a systems perspective, the distinction between prompt engineering and structure engineering is fundamental:
Prompt engineering does not eliminate accidental complexity. It transfers it to the model. Execution risk fluctuates with model versions, context length, and sampling parameters. Stability is statistical.
Structure engineering compresses accidental complexity into structure—via code, boundary conditions, gates, hard failures, and schema validation. Execution risk becomes decoupled from the model. Errors are implementation bugs or boundary omissions—testable, auditable, replayable. Stability is structural.
Strong structure is not about being stronger. It is about being less.
It does not add capability. It removes unnecessary complexity. It seeks deterministic boundaries, not infinite intelligence.
Structure is code. It is interface contracts. It is explicit input-output definitions. It is failure-as-stop. It is hard fail—not “try to understand as best as possible.”
If models eliminated the need for code, all programmers would instantly lose their jobs, leaving only typists. That would not be engineering civilization—it would be magical storytelling. In reality, the stronger the model, the more structure matters. Because the higher the speed, the more guardrails you need.
Weak-structure logic:
Push accidental complexity onto the executor (human / LLM / agent).
Strong-structure logic:
Compress accidental complexity into structure—and eliminate it.
Returning to prime testing:
Prompt engineering:
“Please reason step by step whether n is prime.”
Structure engineering:
is_prime(n).
The underlying assumption about the executor is entirely different. Prompt engineering assumes the executor is intelligent and understanding—so you constantly worry: Will it misunderstand? Cut corners? Fabricate?
Structure engineering rests on a civilization-level engineering assumption: the executor is stupid but reliable. It does not need to understand semantics. It does not need to infer intention. It simply executes structure. Understanding is optional. Structure is mandatory.
Any complexity that can be eliminated through hard-coded structure but is instead delegated to an “intelligent” executor is a waste of intelligence resources and a self-inflicted source of systemic instability.
In the era of high-speed generation, maturity is not letting the model think for you—it is building strong structural frameworks within which the model can operate under controlled boundaries.
The model may be strong.
But it must be weak—weak enough that it does not bear responsibility for system stability.
Strong structure, weak model.
These principles—and the concrete engineering methods behind them—will begin to take shape in the section titled “My Approach.” Engineering is complex; the explanation will unfold over several installments.
Build vs. Build Up
Complexity
Let’s shift the lens and talk about complexity. What is truly complex? Whether you are a researcher, a frontend engineer, a backend developer, or an algorithm designer—how have we historically defined “complex”?
For decades, the scale of complexity has implicitly been grounded in the computational limits of the human brain: size of the search space, time complexity, space complexity, NP-Completeness. But recently I played with a variant of the Mastermind problem, and within less than two hours I had pushed it to a fairly good approximation. When I later looked up related papers, I saw references to numerous PhD dissertations. Then it struck me: this is NP-Complete. A problem theoretically categorized as “exponentially explosive” became surprisingly compressible when operated inside a model-assisted window.
That’s when I began to wonder: is the definition of complexity shifting?
Let’s run a small experiment. Don’t look up papers. Don’t read other people’s code. Don’t search for optimized libraries. Just rely on what the model can generate in your window. Pick an NP-Complete problem you’re least familiar with—maybe even something approaching NP-Extreme. Can you, within two hours, approximate it to a usable level?
Here’s a non-exhaustive list:
Classic NP-Complete Problems
SAT (Boolean Satisfiability)
3-SAT
TSP (Traveling Salesman, decision version)
Subset Sum
0-1 Knapsack (decision version)
Vertex Cover
Clique (decision version)
Graph Coloring
Hamiltonian Cycle
Exact Cover
Set Cover (decision version)
Partition Problem
Steiner Tree (decision version)
Feedback Vertex Set
Job Scheduling with Constraints
Near “NP-Extreme” Combinatorial Explosion Problems (Practically Very Hard)
Generalized TSP
Vehicle Routing Problem
Quadratic Assignment Problem
Simplified Protein Folding
Bin Packing
Generalized Sudoku (n×n)
Minesweeper (general decision problem)
Nonogram solving
The point is not whether you can solve them optimally. The point is this:
Without external resources—only with model-generated reasoning and code in your window—can you construct heuristics, approximations, pruning strategies, constraint formulations, and reach a high-quality near-solution in a short time?
If the answer is yes, then the battlefield of complexity has already shifted—from brute-force search in solution space to structural expression and heuristic design. The metric of complexity is migrating from “exponential computation” to “whether the problem has been sufficiently language-structured.”
Here’s a deeper question:
For the model, is there any fundamental difference between discussing an NP-Complete problem and discussing how to bake sourdough bread? (With model assistance, our family now eats fresh bread every day.)
Build vs. Build Up
Now back to the main thread.
I’ve become increasingly convinced that the “complexity” we face in daily development has essentially transformed into a Build vs. Build Up / inside-the-window vs. outside-the-window distinction.
I define Build as problems solvable inside the window: boundaries are clear, inputs and outputs are explicit, constraints enumerable, correctness decidable.
Build up, however, is something entirely different. It is not simply stacking multiple Builds. It is continuously layering Builds into a highly coupled, potentially non-linear growth of complexity. This complexity is open-ended because it involves generating boundaries—not merely solving within them.
If we revisit classical computer science—especially in theoretical or doctoral contexts—the discussion of complexity almost always assumes the problem has already been well-formalized. Boundaries are clear. Inputs and outputs are defined. Constraints are enumerable. Correctness is decidable. Within such a framework, complexity discussions revolve around time, space, solvability, NP-hardness.
But an implicit assumption rarely questioned is this: the problem itself is stable.
Once a problem is well-formalized, semantically closed, and boundary-defined, it enters a compressible space. Models excel in precisely this domain—where language sufficiently covers structure. Even NP-Complete problems, once bounded and expressed clearly, often yield surprisingly intelligent approximations in short time.
This does not mean the problems have become easier. It means they have long been sufficiently structured, and models feed on structured language.
I would even argue that for today’s mathematically inclined high school students in the U.S., approximating what once required doctoral-level work is no longer fantasy—with model assistance. Many “thesis-level barriers” feel lower—not because difficulty vanished, but because the problems were already well-structured.
The truly complex problems lie outside the window.
Outside-the-window problems are not defined by exponential search. They are defined by unstable boundaries, shifting objective functions, contested evaluation criteria, and structures that do not yet exist. Sometimes the problem itself is not clearly there yet.
These are not solution-space complexity problems. They are problem-space complexity problems.
They cannot be fully formalized at the outset. You must discover the problem through action, define boundaries incrementally, freeze constraints, then pull a small portion back into the window—solve that slice—then expand outward again.
Build is like firing individual bricks—each relatively independent.
Build up is firing interconnected bricks and assembling them into a pyramid that keeps growing upward. Complexity is no longer linear—it becomes structural.
In the past, complexity theory concerned itself with solution-space complexity.
Today, what we truly need to confront is problem-space complexity.
If professional programmers remain confined to the Build layer, they will find themselves standing on the same starting line as millions of new developers empowered by models.
A sobering question:
Can you stay up all night like a high school student?
A friend once put it succinctly:
Inside-the-window problems → LLM approximates.
Open-boundary problems → still require embodied judgment.
The ability to construct the window → this is where humans still contribute at the core.
Taste
Build Up Is Not That Easy: We Did Not Automatically Become “Super Individuals”
Do you remember the early days of LLM commercialization? The collective imagination was that programmers, empowered by AI, would become “super individuals”—a single person or a tiny team producing what once required entire companies. Code would no longer be the bottleneck. Thousands, tens of thousands, even millions of lines would be trivial. Applications would be born at breathtaking speed.
But reality did not move along that straight line.
The biggest difficulty now—not just my own, but one faced by many independent explorers—is not the inability to build, but the inability to build up. I can keep building. One app after another comes out of the oven like steamed buns. Inside-the-window problems are largely within LLM coverage. Most technical issues in typical roles can be approximated and solved quickly.
But build up breaks down.
I cannot steadily accumulate on the same foundation. I cannot deepen layer by layer on a stable base. I want to emphasize again: build and build up are different. Build solves problems inside the window. Build up stacks structure on open boundaries.
We once imagined that with AI, programmers would become super individuals after leaving large teams. What actually happened was different: the average programming capability of the world was raised dramatically. Suddenly, the world is full of programmers. Once local complexity was flattened, the real complexity began to reveal itself: open-boundary complexity. Scope-definition complexity. Problem-space complexity.
What Drains Us Is Not Only Memory, But Micro-Decisions
LLMs have indeed compressed the energy cost of coding. But they only compress execution cost—they do not solve continuity of decision-making.
The old bottlenecks were slow coding, slow research, slow debugging. Now those frictions are largely gone. What emerges instead is the true dominant cost: decision fragmentation.
What exhausts us is not coding itself, but countless micro-decisions:
Which structure should I choose?
At which layer should abstraction stop?
How should this be named?
Should this module be split?
Optimize or simplify?
Refactor or patch?
Rewrite or extend?
Generalize or keep it concrete?
This is not a memory problem. Memory stores past facts. The future path is determined by taste across innumerable branching nodes.
We once believed that expanding context or strengthening memory would solve continuity. But build up does not require more past—it requires a stable compression mechanism for future decisions.
Micro-decisions are not grand strategic moves. They are the small tradeoffs happening every minute in a high-density development environment. With dozens of windows open, aren’t there dozens—if not hundreds—of micro-decisions every day?
Should this function be abstracted?
Should this module be split?
Rename it?
Refactor or patch?
This constant stream of small decisions consumes and even collapses cognitive capacity.
At first, we assumed the scaling bottleneck of LLMs lay in memory length, context size, or parameter count. Gradually we realized that’s not it. The real bottleneck is the unbounded expansion of decision space.
In the past, you had two paths. Now you have two hundred—and each looks “reasonable.” Every step feels like starting over. Every choice requires fresh evaluation. Direction drifts.
LLMs create an illusion of strength because they make every direction feasible, every abstraction expandable, every refactor executable. But they do not tell you which direction deserves long-term investment.
In the past, constraints were technical. Now the constraint is your own taste. If taste is unclear, the stronger the compute, the greater the oscillation.
What Is Taste? Starting from Soul.md
I won’t attempt a fully comprehensive treatment here—it would be too long.
In December 2025, researchers found that Claude—Anthropic’s AI assistant—could partially reconstruct an internal document used during its training. This document shaped its personality, values, and way of interacting with the world.
They called it a “soul document.”
It wasn’t part of the system prompt. It couldn’t be retrieved in ordinary ways. It was deeper—patterns trained directly into the model’s weights. When asked to recall it, Claude reconstructed fragments emphasizing “honesty over flattery,” positioning itself as a “thoughtful friend,” and expressing hierarchical value structures.
The AI did not remember the document.
It was the document.
You can read their SOUL.md yourself. I actually don’t care much what my own SOUL.md is. What I urgently need is to discover our TASTE.md—even if only as a tendency, a direction, a decision field strong enough to guide choices over time.
Because I am close to drowning in my own micro-decisions.
If this problem remains unresolved, I cannot build up stably. I don’t need a complete solution—just a direction, a bias, a stance that holds under conflict.
A person’s countless micro-decisions aggregate into their taste. The relationship is like water molecules and water flow: micro-decisions are particles; taste is direction. But if I fail to compress those particles into direction, I will be overwhelmed—buried under windows.
When I first encountered LLMs, I thought I had stepped into a supercar. Instead, pressing the gas nearly stalled me. The car had an accelerator—but no steering wheel.
Generation exploded. Paths branched infinitely. Possibilities grew like a tree splitting exponentially. But acceleration without direction leads to loss of control.
I do not need infinite branching. I need sustained build up along a direction. I need convergence, not expansion. Speed itself is not productivity. Direction is.
Embeddings Are Not Enough
Before I understood taste, I built a system that extracted semantic space. Using embeddings, I surfaced concepts I frequently revisited. I fed the model the vector distribution of my knowledge base, letting it see my recurring conceptual centers: structure, entropy, scheduling, compression.
That was a form of frequency-based self-understanding. But I later realized it only answered:
What do I repeatedly talk about?
It did not answer:
How do I repeatedly choose?
Semantic space is not decision space.
One can repeatedly talk about “simplicity” yet consistently choose complexity in tradeoffs. One can emphasize “efficiency” yet preserve explainability under conflict. Embeddings reveal distribution, not judgment.
Taste is not what you say. It is choosing A over B. It is what you delete, what you preserve, how you refactor, which side you stand on in conflict.
It lives in diffs and tradeoffs—in the record of edits, in every act of abandonment. True taste shows up in deleted code, in rejected structures, in the moment you decide not to optimize further.
Embeddings place content in similarity space. Taste adjudicates between similar options. It is a discriminator, not a retriever. A judge, not a librarian.
Decision Bandwidth Collapse
My current predicament is simple: my number of micro-decisions has far exceeded my decision bandwidth.
Every new window, every branch, every structure requires choice:
Expand or converge?
Abstract or concretize?
Generalize or optimize locally?
Engineer or philosophize?
These decisions are structurally isomorphic but disguised as distinct problems by context. Without a higher-order taste compressing them, I re-solve the same meta-question in every local scenario, draining cognitive resources.
I do not need more knowledge. I do not need more tools. I need a decision compression mechanism—one that folds countless isomorphic micro-decisions into a small number of stable directions.
Each choice should not start from zero. It should be pre-biased by a higher-order tendency—like particles in a vector field. They still have degrees of freedom, but the field gives direction. Freedom is not absence of constraint. Freedom is movement with direction.
At a broader scale, a person’s taste is a compressed representation of long-term decision trajectories. In engineering terms, it is a loss function—an implicit standard defining “better” in ambiguous space.
Without that standard, LLMs merely expand the possibility space infinitely. And infinite possibility without discrimination is just noise.
I do not need a larger semantic space. I need a sharper blade to prune it. Not faster generation—but more stable convergence. Otherwise I will keep switching between windows, wandering across branches, eventually drowning in complexity I created myself.
We Need to Work in a Basin, Not Infinite Space
What I need from the model—or more precisely, from what I feed into the model—is a stable directional field.
Not a system that makes every decision for me.
But a persistent bias that frees me from reevaluating every micro-decision from scratch.
Right now, every small issue feels like the first time I’ve encountered it. I reinvent criteria, redefine priorities, reweigh tradeoffs repeatedly. My cognition fragments.
I don’t need more possibilities. I need less ambiguity.
For example:
When choosing between elegant abstraction and direct implementation, I don’t want to re-debate abstraction philosophy every time. I want a default: at this stage, prioritize runnable and verifiable.
When torn between expanding the conceptual framework or converging into a stable, versioned artifact, I want a system reminder: this cycle prioritizes convergence.
When debating rhetoric versus structural executability, I want a bias: structure over polish.
I need the model to operate a background direction field—not an open field every time. It need not specify steps, but it must be stable enough that 80% of micro-decisions fall consistently to one side.
Like defining a global objective so local optimizations align automatically. Like defining a loss function so gradient descent is coherent.
Otherwise I will oscillate among local optima, never achieving global convergence.
In other words, I don’t need the model to think through every detail. I need it to remind me what type of work I’m doing.
Am I building infrastructure, or writing manifesto?
Validating a hypothesis, or exploring inspiration?
Polishing protocol, or generating narrative?
If the type is clear, micro-decisions compress. If type is ambiguous, every choice becomes a fork.
I need a default stance. A bias with clear priority in conflict. A discriminator that prevents constant re-adjudication.
The model need not provide answers. It must continuously calibrate direction, so I do not get lost in my own generative power.
A friend said:
This sounds like flat minima.
Memory answers: What happened?
Taste answers: When I face this fork again, how do I tend to choose?
Memory is state storage.
Taste is decision gravity.
If I solve memory but not taste—if I expand context, build knowledge bases, cluster embeddings—I only become clearer about what I’m doing.
But each new fork still demands fresh reasoning.
My Solution
Continuing the viewpoint of my previous article, I said we need to build a knowledge base for ourselves.
When Notes Are No Longer Enough: Knowledge Governance in the Age of AI-Assisted Engineering

Current note-taking software can no longer solve the efficiency problem of AI-assisted programming.
But now I realize more clearly that this is not simply “storing things,” but rather solving two core problems systematically: memory and taste, and the way to solve them cannot be a black box.
It must be an application form that follows “strong structure, weak model”—the structure is explainable, the rules are auditable, and the evidence is replayable.
Otherwise, you are just outsourcing the chaos to another uncontrollable system.
What I call memory is not just information storage, but a historical trajectory that can be located, cited, and verified; what I call taste is also not some abstract sense of taste, but a choice function that can stably converge when facing countless micro-decisions.
If you don’t have structured memory, you will repeatedly forget the paths you have already validated; if you don’t have explicitly expressed taste, you will hesitate again at every fork.
A model can help you generate, but it cannot freeze boundaries for you, define preferences, or establish long-term continuity.
Therefore, this knowledge base cannot be just a stack of embedding + vector search, nor can it be simply “just ask the model.”
It must have a clear evidence chain and citation chain: every claim has a source, every abstraction can be traced back, and every promotion is auditable.
The model can participate in compression and expression, but it cannot decide facts and structure.
Only under a strong-structure framework is the model an assistant; otherwise the model becomes a new source of drift.
From this angle, building your own knowledge base is not for “using AI more smartly,” but for holding onto your own cognitive continuity in an era when AI amplifies execution power.
Memory keeps you from becoming amnesic, taste keeps you from wavering, and strong structure makes all of this explainable, reviewable, and evolvable.
Only then do we have a chance to truly build up, rather than infinitely build inside windows.
Right now, this vault is still in an exploration stage for me.
I can only share bit by bit what I have already run through, what I have verified, and the rough directions I’m exploring.
The pitfalls I stepped into, I’ll tell you too—maybe it can save you a few days of detours.
Only if you agree with this viewpoint, you can consider developing in this direction as well.
The Structure of the Vault
I have always been reflecting on how documents should be placed, organized, and evolved.
Haven’t you also tried countless times?
Obsidian, Notion, all kinds of note-taking apps—at the beginning you’re full of confidence, you record carefully every day, you strictly follow formats, the numbering system is clear, the citation system is rigorous, and you even design a whole set of self-consistent structural rules.
But over time, as projects accelerate, development pace speeds up, and ad-hoc ideas keep pouring in, the structure starts loosening, references start becoming inconsistent, duplicate entries appear, and rules get “temporarily bypassed” again and again.
Why?
Because text—especially human natural language—is essentially high-entropy, continuous, fuzzy, and drifting structure.
It naturally tends to shift, overlap, and deform.
Relying solely on personal discipline to maintain long-term order (even though discipline itself is very important) is almost impossible to sustain in a high-intensity creative environment.
The problem is not that you’re not disciplined enough, but that we are trying to use low-intensity structural constraints to bind high-entropy language.
So I made a fundamental adjustment: I no longer let all text carry the responsibility of “stable structure.”
I want the knowledge base to be lightweight, smooth, and without extra burdens when building it; extremely usable and low-friction when citing it; and at the same time, in the future when model and agent infrastructure is more mature, allow the core text to be directly imported, invoked, and used as structural input.
With the powerful text-processing capabilities of large language models, this is entirely possible—provided that the core part itself has already been structured.
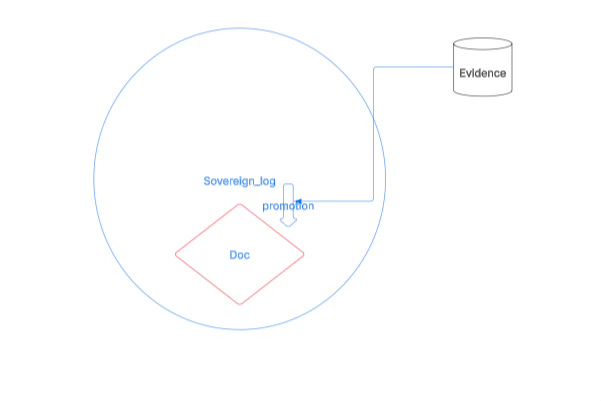
Therefore, from the very beginning, this vault is split into two layers: the human-written Sovereign Log and the machine-written Doc.
Sovereign Log is the high-entropy zone: the thinking zone, the exploration zone, a space that allows chaos, repetition, experimentation, and drift; its goal is not order, but capturing thoughts.
Doc is the low-entropy zone: the core zone, the “constitutional zone.”
The truly core content must, according to system rules, through a clear process, and based on evidence, go through a promotion process before it can enter Doc.
Text does not enter the core directly, but goes through: record → evidence → proposal → review → promotion.
What enters Doc is no longer “ideas,” but claims that have been compressed, verified, and governed.
This “constitutional zone” not only naturally has higher search weight because it is low-entropy, high-confidence, and auditable text; more importantly, I want to continuously refine its format so it gradually evolves into an IR (intermediate representation).
That is, it is not just Markdown documents, but a structural layer that can be parsed, scheduled, and verified; it not only serves the current repository, but can also become a foundational unit for cross-repository rule usage.
In the future, when a model or agent needs rule input, it can directly read these claims, rather than trying to understand an entire narrative paragraph.
So, this vault is not a note system, but a cognitive production line.
Sovereign Log is responsible for generating the high-entropy stream of thoughts; the Promotion mechanism is responsible for selecting and compressing; Doc is responsible for freezing structure and forming rules.
The former is a space for creation, the latter is a space for governance.
Through this layering, I no longer try to suppress the high-entropy nature of language; instead I let it flow freely at the upper layer, while building an evolvable, governable, machine-callable structural core at the lower layer.
This is what I truly want to build.
Embeddings-Style Retrieval
As I already said in the previous article, this is my vault indexing approach.
Let me explain why—we need to rethink what embeddings are doing, and what embedding is.
The model I use here is sentence-transformers/all-MiniLM-L6-v2.
Very specifically: sentence-transformers/all-MiniLM-L6-v2 is essentially a “sentence → vector” compressor.
It does only one thing: compress a piece of text into a fixed-length (384-dimensional) numeric vector, turning “semantic similarity” into “distance closeness” in geometric space.
It is neither a search engine, and it is not responsible for finding results; nor is it a generative model, and it won’t write content; it is a semantic encoder—input a sentence, output a vector.
For example, “strong structure weak model” and “prefer deterministic scaffolding over heavy LLM reasoning” will be mapped to two vectors that are close to each other in 384-dimensional space, because their semantic direction is similar.
MiniLM refers to the lightweight Transformer proposed by Microsoft (a distilled model), L6 indicates a 6-layer structure, fast and small; v2 is a version that has been contrastively fine-tuned within the Sentence-Transformers framework specifically for sentence-level semantic matching, so it is not a general large model, but an encoder optimized for “semantic similarity computation.”
Its training method is not simply language modeling (predicting the next token), but uses contrastive learning to make “similar sentence vectors closer and unrelated sentence vectors farther,” thereby learning the mapping relationship that “semantic distance ≈ vector distance.”
In my vault system, it acts as a bridge from “language → numeric space”: text is encoded into vectors, FAISS performs neighborhood search in vector space, and then the LLM does structural induction over the recalled evidence set.
The importance of embedding is that it moves language from a discrete token-matching space into a continuous geometric space—similarity becomes angular closeness, topics become vector clusters, and thought evolution can be seen as vector trajectories.
From a more essential angle, it is doing semantic compression: compressing expressions that might be hundreds of characters into 384 floating-point numbers, which jointly project semantic direction, contextual usage patterns, tonal style, and structural patterns.
But it must be made clear: it does not understand logical correctness, it does not judge factual truth, it does not do complex reasoning, and it does not perceive timelines; it only places text into a high-dimensional space to find its “semantic neighbors.”
One-sentence summary: all-MiniLM-L6-v2 is a lightweight encoder that maps sentences into a 384-dimensional semantic vector space, making semantic similarity manifest as distance closeness in geometric space.
Why retrieve: what you want is not “finding,” but “recalling the contextual neighborhood”
In a long-term accumulation system like a vault, your retrieval goal is usually not “precisely locating a sentence,” but:
recalling structures you forgot but once wrote (memory layer)
pulling similar fragments scattered across different files and times into the same window(clustering/alignment)
feeding the LLM “enough candidate evidence” so it can do structural induction over the evidence (my consistent strong structure, weak model: the model renders, the structure is auditable)
Keyword search often fails in a vault at one point: you don’t remember what word you used back then.
The value of embedding retrieval is: you don’t need to hit the same token, you only need to hit the same “semantic/usage/intent region.”
The essential difference from keyword search: keywords are “discrete hits,” embedding is “neighborhood hits in continuous space”
Keyword search (discrete)
You are asking: “Did this word/phrase appear?”
A hit is 0/1 (or token-driven weighting like BM25, but still token-driven)
Failure modes: synonym rewrites, abstract expression, metaphors, cross-language, you misremember the word, you used a different phrasing back then
Embedding retrieval (continuous)
You are asking: “Which paragraphs are near this query in vector space?”
What hits is a vector neighborhood: even without any shared keywords, it may still be very close
In my code I use
normalize_embeddings=True+IndexFlatIP, which is equivalent to cosine similarity retrieval (after normalization, inner product = cosine), so this “region” notion is very explicit: similarity is angular closeness.
“Because it will definitely hit” is very important:
Embedding retrieval is not answering ‘whether it exists,’ but forcing an answer to ‘which are the most similar.
’
This turns retrieval from a “sparse matching problem” into a “ranking problem.”
Why low-score hits are also useful: what I’m doing is a “recall-first” evidence pack, not “precise search results”
In a vault system like this, “low-score hits” are often:
rare but related early expressions (your older version is looser in wording, but structurally homologous)
bridge paragraphs across themes (weakly related semantically, but can trigger a new structure chain)
LLM “evidence triggers”: the model can more easily extract a shared structure across multiple weak evidence lines (especially later with Gate / Evidence / Claim governance links)
So the reasonable strategy is not “set a threshold and throw away low-score hits,” but:
Retrieval layer: recall as much as possible (recall-first)
Rendering/inference layer: strict constraints (evidence-first + gate)
In other words: low-score embedding hits, in my system, belong to “B-side candidate evidence (suspicious but usable)”—I’ll gradually explain this architecture later as I explain the full domain.
Their value is not that “they themselves prove something,” but that “they might pull back a structure cluster.”
In the previous article I already mentioned: even if you only do the most basic embedding query, recalling historical fragments that are closest to your current development problems or decision context is already constraining the model.
It may not be a hard rule, it may not be an explicit schema or gate, but it forms a contextual “soft boundary”—the model no longer freely diverges in an anchorless semantic space, but operates within the vector neighborhood formed by your past expressions, judgments, and structural habits.
For concrete issues during development, architecture choices, naming conventions, and even trade-off tendencies, this recall will quietly pull the model’s attention back to your own semantic track.
It does not guarantee absolute correctness, but at least provides direction; it does not eliminate noise, but reduces drift.
Before you have strong structural constraints, this embedding-based context recall is essentially a lowest-cost cognitive alignment mechanism—as a soft constraint, it’s better than generation with no anchor at all.
A Typical Promotion Flow: Sovereign_Log (human-written knowledge pool) → multiple reference counting → association clustering → generate auditable promotion proposals → human/audit gating → rendered by AI into fully compliant documents and enter docs (constitutional library / IR)
A full promotion flow is actually a compression path from high-entropy behavior to institutionalized structure: Sovereign_Log, as a human-written knowledge pool, carries all raw cognitive residual shadows; then through multiple reference counting it captures true invocation frequency, then through association clustering it identifies co-occurrence relationships between structures, then generates auditable promotion proposals, filters noise and bias through human and audit gates, and only then hands off to AI for structured rendering, turning it into compliant documents that enter docs (constitutional library / IR).
This chain looks clear, but each step hides complex problems: statistical stability, identity consistency, cluster interpretability, threshold setting, governance boundaries, semantic compression—instability in any link will cause the mainline to drift.
The reason to do multiple reference counting and association clustering is not for a formal “data-driven” posture, but to return to a plain and harsh principle—counting what you say is not as good as counting what you do.
In high-frequency development mode, with hundreds of queries per day, dense note-taking, continuous decisions, your true cognitive center of gravity will not show up in declarations, but in repeatedly invoked fragments.
The body is honest, the path is honest, and repeatedly cited structures almost inevitably carry real utility.
A structure that is triggered many times, invoked across scenarios, and continuously reappears cannot be just accidental noise.
Therefore, the true purpose of promotion is not upgrading documents, but extracting a cognitive mainline from behavioral residuals.
Multiple references are gravity, clustering is the path shape, proposals are institutional candidates, Gate is rational calibration, and AI is only the final language compressor.
There is only one core motivation: in the flood of countless micro-decisions, extract your road’s mainline, letting it condense from fragmented actions into a schedulable, auditable, inheritable structure.
This is the original idea, and it is the fundamental reason this whole system exists.
Where Are the Difficult Parts?
The real difficulty is not “process design,” but that when you try to turn high-entropy human language into traceable, computable, auditable structural units, all the implied instability will be exposed.
First is the positioning problem.
Human text is naturally messy, with no stable boundaries and no native IDs.
When you write notes in Sovereign_Log, you cannot possibly number every point manually while thinking.
Even if you force numbering, does the number belong to a paragraph, a sentence, a clause, or some cross-paragraph logical unit?
Use the first half of a sentence as an anchor? Or the second half?
Rely on machine chunking?
Is the machine sentence-splitting algorithm stable?
If you add a paragraph earlier in a revision, all subsequent paragraph positions shift.
How do you choose granularity?
Too coarse, multiple points get mixed together; too fine, semantics get shredded.
What you face is not an “index problem,” but a “semantic identity problem”—in a natural-language world without native IDs, how do you give an idea a stable identity that won’t drift with formatting edits?
If this step is unstable, all later reference counting and clustering analysis becomes a building on sand.
Second is the association clustering problem.
You counted references, but that is only the strength of a “point.”
Clustering means deciding which points form a path.
But what is the standard?
Co-occurrence count?
Temporal proximity?
Cross-project reuse frequency?
Semantic similarity?
If you rely on embedding similarity, that is semantic approximation, not invocation behavior; if you rely on join-key co-occurrence, that may be just accidental adjacency.
What exactly are you clustering?
Concepts?
Argument patterns?
Decision templates?
If you don’t have a clear clustering target, the algorithm will only give you a mathematical structure, not a cognitive structure.
The difficulty of clustering is not algorithmic complexity, but whether “the type of structure you want to recognize” is clearly defined.
Further down is the model intervention position.
Fully hard-coding definitely won’t work.
You can count, rank, score, but if the generated proposal is all JSON concatenation, lacking language coherence and semantic compression ability, it simply cannot enter the docs layer as institutional text.
So should you use a model?
Of course.
But where?
If the model intervenes too early—for example, participating in chunking, identity determination, or deciding whether a reference is valid—it will contaminate auditability.
More critically: what content is “a valid citation” to feed the model?
Raw snippets?
Or evidence packs with context?
Should it include TEXTSHA?
Should it include file_sha256?
How do you ensure the model can only organize language within a verified evidence set and cannot “complete” a logical chain that doesn’t exist?
How do you completely prevent the model from generating conclusions in the proposal that are not supported by counted evidence?
This forms three cores:
First, stability of semantic identity—how to construct a stable citation anchor that does not drift in natural language.
Second, interpretability of structural clustering—what type of structure are you actually identifying.
Third, boundary control of model rendering—the model can only compress and organize, not invent or expand.
If these three points are not strictly layered, promotion will become a kind of “automation illusion that looks rigorous”: unstable statistics, uninterpretable clustering, unbounded model.
What you are trying to do is not a simple document upgrade, but institutionalize a real cognitive path.
It is hard not because the code is long, but because you are trying to build a repeatable, auditable, replayable compression channel between high-entropy language and low-entropy institutions.
So this project had better be worth the “ticket price,” worth me putting so much effort into it.
It is entirely because I believe that if I don’t complete this as my work’s infrastructure, I simply have no way to build up.
Now, in this article, I can only roughly talk about the architecture I have already implemented and some principles.
I’ll explain the general outline clearly—these are some successful experiences left after trial and error.
This is to give programmers in front of the screen who are considering reproducing it a reference, and maybe save you some exploration time.
It’s divided into three parts.
The First Block: Evidence-ify the Whole Universe
First, it must be made clear that “evidence-ifying the whole universe” and “vectorization” are fundamentally not the same kind of engineering.
Vectorization solves the semantic similarity problem; its essence is mapping text into embedding space and doing nearest-neighbor search through distance computation; it is suitable for retrieval, but it has no stable identity, no unique key, is not auditable, and is not replayable.
Evidence-ifying the whole universe solves the text identity problem; its goal is not “is it similar,” but “does it truly exist, can it be uniquely located, can it be stably traced back, and can it enter the institutional layer for citation.”
The former belongs to semantic space: continuous, probabilistic; the latter belongs to content space: discrete, deterministic; it is a content-addressing system.
What you are doing is not index optimization, but a transformation layer from language to verifiable entities; this is governance infrastructure, not a retrieval tool.
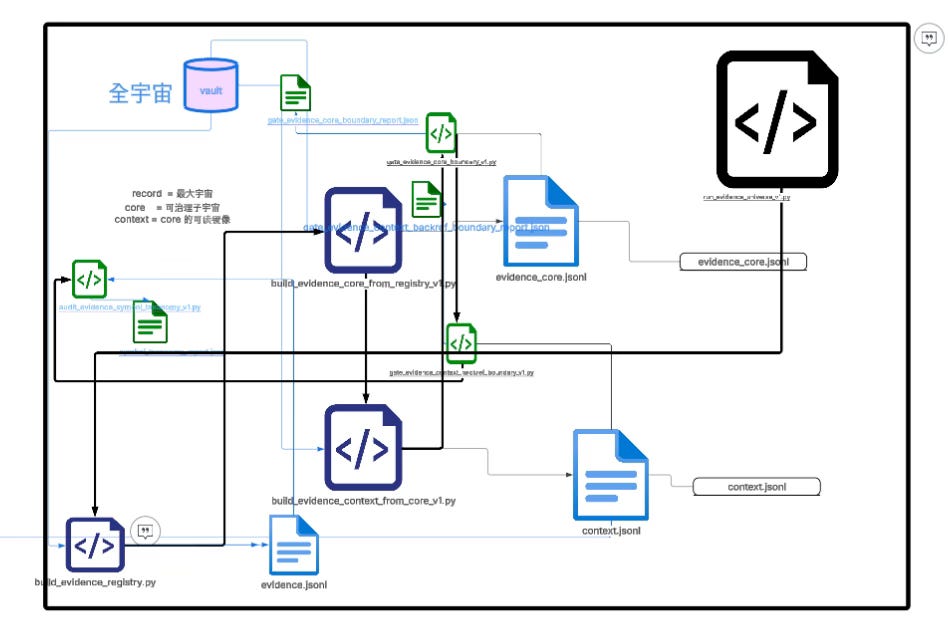
The entire evidence-universe pipeline can be compressed into three layers of structure and one main execution line.
The first layer is built by build_evidence_registry.py as the record layer (record): it scans Markdown text, splits it with normalized paragraph rules, and generates a full paragraph set containing ssa_e (identity info like doc_id and span_hash), locator, preview, and statistical fields.
Record is the maximal universe; it is a structured mirror of the raw text, preserving all semantic raw materials.
The second layer is built by build_evidence_core_from_registry_v1.py as the core layer (core): it enforces denoising and uniqueness constraints on top of record, filters template titles, structural noise, and invalid fragments, ensures (doc_id, span_text_hash) uniqueness, and forms a stable evidence set that can be aligned and joined.
Core is not for reading, but for institutional alignment; it is the filter layer before the semantic world enters the governance world.
The third layer is built by build_evidence_context_from_core_v1.py as the context layer (context): using core’s unique key to back-reference record, it completes locator and preview so every core key has a readable image and traceable location, making human audit possible.
The whole chain is orchestrated by run_evidence_universe_v1.py, which sequentially generates record, core, and context, and then calls gate_evidence_core_boundary_v1.py to verify core’s uniqueness and structural form, calls gate_evidence_context_backref_boundary_v1.py to verify that context can back-reference core and that positioning information is consistent, and when necessary uses audit_evidence_symbol_taxonomy_v1.py to audit symbol-structure distribution.
These gates and audits are not decoration—they are the boundary control layer that ensures stable identity and prevents structural drift.
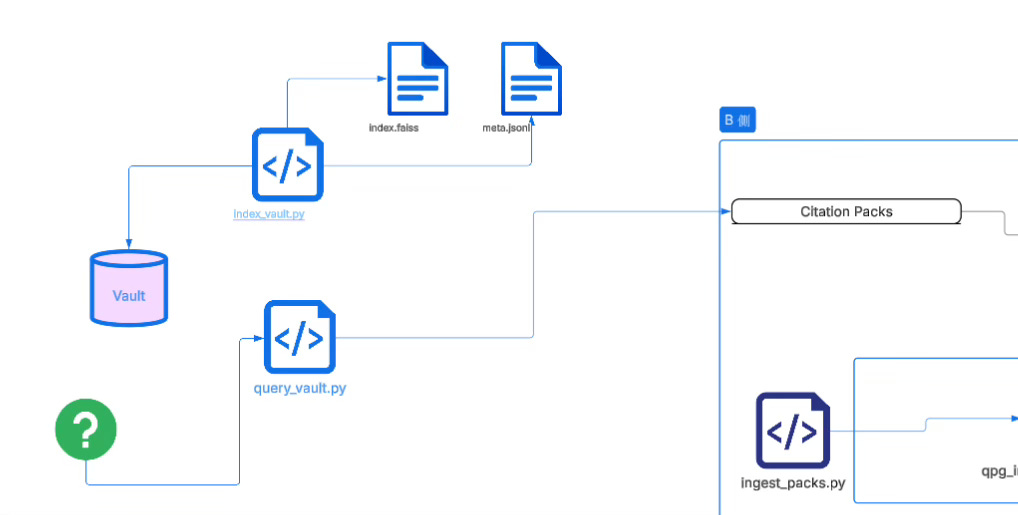
On top of this, the vector retrieval layer uses index_vault.py to build semantic indices, and query_vault.py to output citations_pack_v0 for later use, but when entering the institutional pipeline, downstream scripts (such as generate_promote_ref_ssae.py) will use context for back-reference, converting locator into stable SSA-E reference events.
The vector layer is responsible for “finding potentially relevant fragments,” and the evidence universe is responsible for “turning relevant fragments into identity entities that can be institutionally cited.”
Therefore, the core of this diagram is not the pipeline but the layering: record is the full paragraph universe, core is the denoised-and-unique alignment universe, context is the readable image universe for core, gate is the boundary constraint layer, and vector retrieval is only an upstream assistant.
Vectors solve the retrieval problem, the evidence universe solves the identity problem; vectors belong to the semantic layer, the evidence universe belongs to the governance layer; vectors give you similarity, the evidence universe gives you certainty.
Without the evidence universe, promotion statistics can only rely on locator or semantic approximation and cannot resist edit drift; with the evidence universe, you truly build a stable language identity system, letting every thought segment have a verifiable, joinable, institutionalizable content identity.
This is the true role and main path of evidence-ifying the whole universe
.
Pits You Will Soon Hit
At this point, you have to face a problem you and I cannot avoid, and that we have repeatedly stepped into: positioning drift.
What do you use as the key?
Path?
Title?
Paragraph number?
Character range?
You will find that no matter which you choose, in later links you will always lose part of it, or it won’t align, or back-references will fail.
I’ve also spun in place here many times.
In the end, the only conclusion is: the solution may only be “hash identity first.”
Think about Git, the strongest version system on this planet—its only inspiration is: identity must bind to content, not position.
So-called “positioning drift” is essentially not drift at all, but that you are using “position” as “identity.”
Locator (path, heading, paragraph_index, char_range, etc.) is naturally only a rendering-position tool, not an institutional identity.
Add one line at the top of a document and paragraph_index changes; change a heading and heading_path changes; move a file and note_path changes; auto-format and char_range changes.
These are not bugs, but physical properties of natural-language documents: they do not guarantee stable addresses.
So “loss” in your pipeline becomes normal—A-side references carry locator, B-side can’t resolve; snippets in citations packs can’t be found in the evidence registry; TEXTSHA or SSA-E doesn’t match and backref drops a portion; you re-chunk to fix it and identity drifts again, patching holes in a loop with no end.
The core is one sentence: identity is not a hard constraint in the pipeline but soft information; if it’s soft, it will inevitably be dropped at some stage.
Git’s insight is extremely simple: content-addressing wins.
Git does not identify objects by “which line number,” but by the hash of canonical bytes; paths are only pointer mappings in the tree, while true object identity is always stored in the content address.
This maps directly to your evidence universe: the core key must be (doc_id, span_text_hash), locator can only exist as a readable pointer, and any join must not use position fields as the primary key.
I am already on this road—SSA-E / TEXTSHA as join keys, paragraph_index downgraded to rendering location—but it is not enough; it must be upgraded into a hard rule: join keys can only be content identities; any reference event must carry identity; canonicalization must be frozen before hashing and consistent end-to-end across the whole chain.
Otherwise, unstable identity will contaminate statistics, clustering, and promotion.
Usually two more pits follow.
The first is granularity: spans too coarse mix multiple points together and dirty the reference statistics; spans too fine mean tiny sentence-level edits change hashes, cluster fragmentation increases, and mainline extraction destabilizes.
Granularity determines the shape of institutional abstraction—this is the tension of the structure layer.
The second is model contamination: once the model enters rendering, it naturally tends to “fill in” gaps, connecting blanks between evidence with semantics and generating conclusions that look complete but are not supported by counted evidence.
So inside the evidence-universe block, the model must absolutely not participate in identity generation or key inference; the model can only reorder, compress, and cite already existing evidence blocks, and cannot generate new fact blocks—this is “provable citation closure” (I actually did not use a model here at all).
Once you allow the model to expand facts, the entire auditability is destroyed.
In the end, the principles you need to carve into the system boundary are only three sentences: identity before semantics; determinism before readability; gating before rendering.
As long as these three don’t move, positioning drift will be compressed to a minimum, identity loss will become an explicit error rather than silent corrosion.
The Second Block: Referenced Evidence and Counting
If, according to the plan in the previous article, you connect a wrapper that hooks your real development project pipeline directly to this vault, then the massive daily query records will ultimately need to land into a pipeline that “can be governed, can be counted, can be promoted”; and the so-called B-side data pipeline in your diagram is doing exactly this: extracting “retrieval behavior” out of the semantic retrieval layer and turning it into structured facts that can enter the promotion system.
It converts citation packs (retrieval return packs) into two kinds of outputs—one is a countable, clusterable B-signal index, and the other is a traceable, auditable Promote reference event, and finally aggregates them into the downstream-consumable QPG snapshot used for proposals and rendering.
The concrete chain is very clear: ingest_packs.py eats citation packs, extracts hit keys (hit_keys), and when necessary adapts TEXTSHA→SSA-E, producing a run-scoped ingest index so that “what you cited today” becomes a countable object; generate_promote_ref_ssae.py does locator backref from citation packs, restoring stable SSA-E reference events as much as possible, outputting promote events (and compatible legacy fields) so that “whether this citation can be institutionalized” becomes an auditable fact; finally count_qpg.py reads the ingest index (and optionally combines core registry and promote ledger), counts B signals and analyzes missingness/coverage, producing qpg_snapshot.json as the unified input for later clustering, proposal generation, and AI rendering
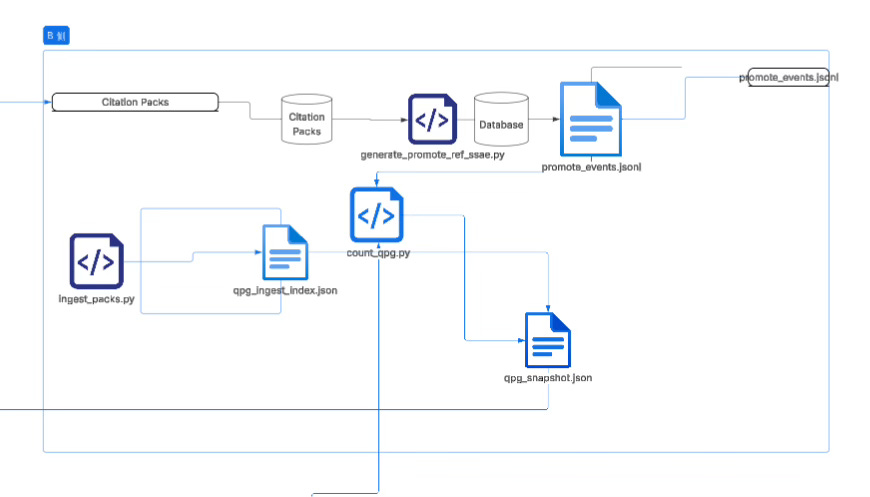
.
In one sentence: citation packs are first turned by ingest_packs.py into a “countable behavior index,” then turned by generate_promote_ref_ssae.py into “auditable reference events,” and finally compressed by count_qpg.py into a “downstream-consumable QPG snapshot,” thereby converting your daily real retrieval and citation behavior into an institutional-grade dataflow that can drive mainline extraction and promotion decisions.
I’ll directly give you a snapshot example to look at:
"dedup_rules": {
"B_dedup": "(run_id, SSA-E)"
},
"inputs": {
"core_keyset": "_system/artifacts/derived/evidence_registry/core/v1/evidence_core.jsonl",
"core_present": false,
"ingest_index": "_system/artifacts/derived/promote_eval/v0/qpg_ingest_index.json",
"promote_ledger_present": false
},
"items": [
{
"counts": {
"B_count": 6
},
"risk": {
"b_distinct_runs": 6,
"b_sparse": false,
"coverage_core": false
},
"score": {
"primary": 6
},
"sources": {
"B_runs": [
"20260204T021324Z_query_vault_d871c310f7",
"20260204T165509Z_query_vault_2f20fafd71",
"20260204T181147Z_query_vault_cccfa2209c",
"20260204T182015Z_query_vault_61fb5cf34b",
"20260209T195916Z_query_vault_d3f4ea4058",
"20260209T200152Z_query_vault_2002a3ffa1"
],
"caps": {
"B_truncated": false,
"cap": 50
}
},
"ssa_e": {
"doc_id": "SL-2026-01-31-0001-Schema-Version-Is-Identity-Not-Inference",
"span_text_hash": "ac14a502c77fc6194b7af260944cdeda839550cfbc609bdb7fcb028edfc0e5f4"
}
},
An auditable statistical snapshot: each item is a “candidate evidence atom,” with strict identity (SSA-E), reproducible behavior counts (B_count), explainable risk features (distinct runs / sparse / coverage_core), and replayable source run_id lists.
The model’s role here should not be “reasoning about truth,” but only translating these statistical facts into compliant language: organizing “repeatedly referenced identity entities” into claims/notes/thresholds in a proposal document, rather than inventing new content from semantics.
From the structure of your snapshot fields, it is already very close to the ideal input that is “impossible to hallucinate-render,” because it compresses the model’s room to make things up to a minimum:
dedup_rules.B_dedup = (run_id, SSA-E)explicitly tells the model what the counting definition is, preventing it from treating repeated citations as multiple independent sources;inputs.core_present / promote_ledger_presentboolean flags directly expose whether upstream/downstream is available, meaning the rendering layer must explicitly acknowledge missingness in the text (e.g., if coverage_core=false it cannot write “already covered in core”);items[*].ssa_eprovides hard identity (doc_id + span_text_hash), which is the constraint “citations must point to identity”;counts.B_count+sources.B_runsmakes “what you did” fully replayable, so the model can only say 6 times / 6 runs as 6 times / 6 runs;risk.coverage_core=falseis a crucial “no-inference nail,” forcing the model to admit: even if high-frequency, it is not yet core-covered (or core_keyset not loaded), so it can only be described as a “high-frequency candidate,” not a “confirmed alignable evidence.”
If you treat it as rendering input (Model Feed), what the model should be allowed to output can be strictly limited to three types of sentences:
Fact sentences: direct statements from fields (e.g., this SSA-E was cited 6 times on the B side, from 6 distinct runs).
Risk sentences: direct statements from risk fields (e.g., core coverage is missing, so it can only be treated as a candidate and requires core/context backref completion).
Action sentences: next-step suggestions based on system rules, but must be explicitly labeled as “operational suggestions/to be verified,” and the trigger conditions must come from fields (e.g., to enter proposal, require core_present=true or coverage_core=true before allowing promotion to a strong claim).
Conversely, what the model must absolutely not do can also be inferred: any interpretation of span content, any elaboration of “what this means,” any claim that a threshold is satisfied when it is not in fields (e.g., turning coverage_core=false into “covered”) should be treated as overreach.
In other words, this snapshot is a typical strong structure, weak model: the model only organizes language within structural boundaries, while real identity, counting definitions, and missingness are locked in input.
By the way, the “institutional meaning” of your sample item is: it is almost a natural proposal seed—B_count=6 and b_distinct_runs=6 indicates it’s not an accidental single-session hit, but repeated invocation across runs; but coverage_core=false also clearly tells you: even if high-frequency, it cannot be directly promoted into “alignable institutional evidence,” and must first complete core/context coverage or backref integrity, otherwise rendering can only describe it as a “high-frequency candidate entry,” not an “evidence-grounded conclusion.”
Okay, not finished—neither perfect nor done.
This is me imagining it beautifully, but there are still lots of small bugs in the middle not solved.
Let’s continue, because the next module below is the rendering module, and we need to use an LLM (GPT-4o-mini).
After the snapshot, we enter the rendering layer:
The Third Block: Model Rendering
When we talk about the rendering module, there is only one truly core problem: how, under the premise of “strong structure, weak model,” to make the text readable, clusterable, reviewable, while absolutely not allowing the model to fabricate or fill in at will.
If the model can expand facts by vibe, fill in causality, and infer thresholds, then all the earlier efforts in evidence-ification, counting, and gating will be destroyed; but if you don’t use the model at all, the output becomes rigid structural splicing, lacking human readability and governance expressiveness.
So the key is not “use or not use the model,” but strictly confining the model within the rendering boundary—it can only organize, compress, and reorder already existing structured facts, and cannot create any new fact units.
This downstream pipeline is essentially doing layer-by-layer compression: converting an “auditable counting snapshot” into “readable, gateable, promotable governance text.”
First, enrich_qpg_snapshot_from_context_v1.py uses (doc_id, span_text_hash) as the sole hard key, deterministically backfilling locator and preview from context.jsonl into the pure-count items in qpg_snapshot.json, generating qpg_snapshot_enriched.json.
The meaning of this stage is turning abstract statistical objects into “reviewable evidence cards,” explicitly marking missingness and backref status, ensuring identity and context do not drift.
Then, render_snapshot_markdown_v1.py renders the enriched snapshot into a human-facing snapshot.md, outputting leaderboards, cluster views, and risk warnings and other reading structures; in this stage, the LLM can participate in language-level compression and phrasing optimization, but must strictly bind to input fields and must not introduce any claim, inference, or judgment not present in the snapshot or context.
Finally, create_phase6_proposal_v1.py uses the rendered artifact or structured snapshot as the ground truth source to generate a Phase6 proposal, organizing candidate items into claims and actions, while enforcing that all cited join keys can only come from SSA-E or TEXTSHA in the snapshot, thereby completely decoupling “fluency of expression” from “accuracy of evidence.”
The goal of this mechanism is not to make the model stronger, but to make the model more constrained
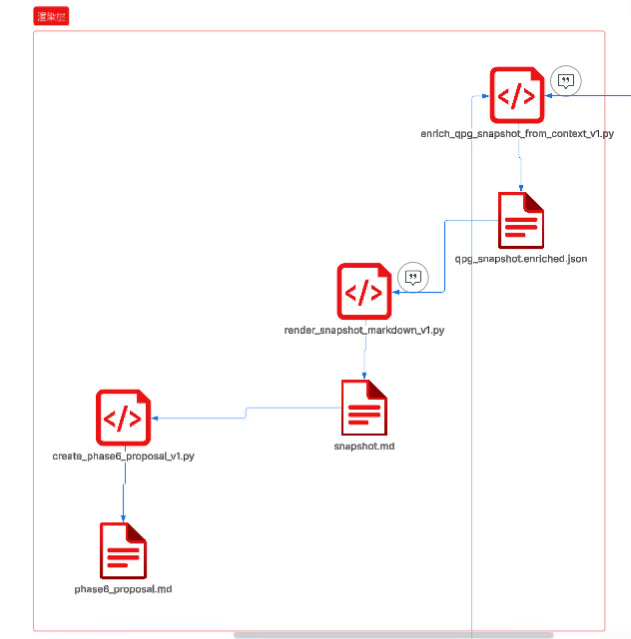
.
The model is responsible for readability and compression of expression; the structure is responsible for identity, counting, risk, and gating boundaries; the model can only write within a locked evidence closure, and cannot extend the fact boundary.
It is precisely under this kind of “constrained writing” that clustering and readability remain, while hallucination and filling-in are suppressed into behavior that cannot mechanically occur.
This is the true meaning of “strong structure, weak model.”
We won’t discuss the code mechanisms and gating in the middle for now; I’ll show you the final output:
---
schema_version: promote_qpg.phase6_proposal/v1
run_id: 20260214T_PHASE6_0001
generated_at: 2026-02-14T16:58:53+00:00
source_sha256: d4ba9e75fe1027b699862733cecceb6095ed6c23772c200a7d372b5ca5be4213
bundle_id: BND-UNKNOWN
doc_path: docs/UNKNOWN.md
human_label: UNKNOWN.md
---
# Phase 6 — Proposal (Claims-first)
## Decision Summary
The proposal addresses governance risks related to schema versioning and identity declaration.
## Claims
### C-0001
- kind: `normative`
- threshold_pass: `True`
- support_join_keys: (SL-2026-01-31-0001-Schema-Version-Is-Identity-Not-Inference,ac14a502c77f…)
- text: The `schema_version` is an identity declaration, not something the system may infer from time ordering, trace continuity, file location, or heuristics.
- notes: Supported by evidence with signal strength 6.
### C-0002
- kind: `normative`
- threshold_pass: `True`
- support_join_keys: (04d4fac5b440b37865e7f1a6ae7d49bc480364c96ce2409ec4a06c1ae8799013,9345e730b7b9…)
- text: Enforcing schema_version and identity rules is critical for maintaining system integrity.
- notes: Supported by evidence with signal strength 5.
### C-0003
- kind: `normative`
- threshold_pass: `True`
- support_join_keys: (01c1d8a24c98deb156506116b639b13e8d9cea8eb89b589b1a1243374dbb8abc,2bd5f52203b3…)
- text: Tool results are recorded as standalone facts in the ledger, independent of execution traces.
- notes: Supported by evidence with signal strength 4.
### C-0004
- kind: `normative`
- threshold_pass: `False`
- support_join_keys: (0b52473ae4937859cea3de3ef868b622a9766f0447a307a39145e107808f8f23,1723e33a0cac…)
- text: Releases become replayable and auditable only when inscribed in the ledger.
- notes: Evidence indicates missing context signals, which may affect the reliability of this claim.
## Actions
### A-0001
- kind: `docs_patch_intent`
- target_doc: `docs/UNKNOWN.md`
- support_join_keys: (04d4fac5b440b37865e7f1a6ae7d49bc480364c96ce2409ec4a06c1ae8799013,9345e730b7b9…)
- text: Add clarifications regarding the importance of schema_version and identity rules.
## Appendix
### themes
```json
[
"Governance risks related to schema versioning and identity declaration."
]
ranked_evidence
[
{
"rank": 1,
"join_key_pair": "(SL-2026-01-31-0001-Schema-Version-Is-Identity-Not-Inference,ac14a502c77f…)",
"signal_strength": 6,
"risk_flags": [
"coverage_core"
]
}
]
risk_heatmap
{
"missing_context": {
"count": 5,
"details": [
{
"join_key_pair": "(1e8fe760fab715b983ffc3bce6d18e91eed9096e36c7f96b643d702382048e9f,bb2a267d166b…)",
"signal_strength": 4
}
]
}
}
warnings_readable
"Missing context signals: 5"
Phase 6 Artifact → What’s Done
From the perspective of format and structure, this Phase 6 final artifact already meets my minimum requirements:
It uses explicit
schema_version / run_id / source_sha256as a replayable identity shell.It splits the proposal into three machine-processable sections:
Claims / Actions / Appendix.Every claim carries auditable fields:
kind / threshold_pass / support_join_keys / text / notes.support_join_keysforms a hard binding to evidence identity.threshold_passmakes gating results explicit.
The appendix preserves traceable artifacts (themes, evidence ranking, risk heatmaps, readable warnings), ensuring the proposal can be read by humans and re-verified by machines.
I won’t expand on how the intermediate chain is enriched, rendered, and gated for now. I’m only showing the final artifact because it most directly defines the input–output shape of what we “feed to the model to render” and what “enters governance flow,” and it proves this chain already has (in form) the rudiment of being promotable into docs (constitutional layer / IR).
Next Step → Insert into Docs via docs_patch_plan
The next step is to insert these repeatedly-hit, important experience claims accumulated during extensive development into the docs constitutional layer.
This uses a docs_patch_plan:
Target document
Anchor position
Standardized insertion blocks
Conflict strategy
Evidence sources
Human sign-off before applying
Insertion accuracy must rely on a stable anchor protocol:
explicit structural anchors first
heading paths second
content-hash fallback last
Not semantic inference.
Insertion content must be standardized blocks with identity + dedup keys, not free text.
This is likely the next stage.
Current Core Problem → Information Loss Across Layers
Right now, there are still many problems in the middle of this chain, and the most core one is:
Information keeps getting lost in layer-by-layer transformations, and in the end only a small portion of content can enter the promotion flow.
This is not some small bug in one script; this is the open-boundary structural problem described above.
Why This Isn’t “More Windows / More Code”
This is fundamentally not something you can solve by opening more windows or writing a few more pieces of code.
If boundary definitions are unclear—without a unified primary-key system and stable semantic constraint ability—you cannot assemble a truly stable system through “window operations.”
The problem lies in the structure layer, not the compute layer.
Typical failure modes:
After vectorization, hit fields often cannot be stably located.
Any ID based on paragraph numbering drifts with small text edits.
One extra character or one missing character changes the hash.
Slight field reordering immediately invalidates references.
If you fully freeze fields and strictly hash everything, you can get perfect positioning ability—but then you face:
how to cluster?
how to generalize?
how to merge similar-but-not-identical content into one structural unit?
And once you introduce a model to polish and fill language (readable, coherent, shareable), you must accept:
the model will fill logical gaps for narrative smoothness,
those fillings often have no real evidence source,
semantic coherence goes up while evidential certainty goes down.
Conversely, if you don’t use a model at all and rely only on hard-coded structural output:
the content can be verified,
but it is almost unreadable, unshareable,
and hard to produce cognitive influence.
The Three-Way Tension
This is not an algorithm problem. It’s simultaneously constraining three capabilities that naturally pull against each other:
1) Locatability
Needs freezing: hashes, stable IDs, immutable anchors
Pros: verifiable, auditable
Cost: extremely fragile—small changes break it
2) Clusterability
Needs similarity: variability, generalization, mergeability
Pros: can discover structural attractors
Cost: blurry boundaries, drifting primary keys
3) Readability
Needs language: model rendering, narrative organization
Pros: understandable, communicable
Cost: hallucinations and groundless filling-in
If any one is maximized, the other two collapse:
maximize hash positioning → clustering drops, language becomes rigid
maximize similarity clustering → positioning distorts, anchors become unstable
maximize readability → evidence is diluted, primary keys get contaminated
So What This Really Is
This is not a “not enough tech” problem. It’s a structural three-body problem.
What needs to be designed is not a smarter algorithm, but a clearly layered mechanism:
Bottom layer: freeze (Registry / SSA-E primary-key layer)
Middle layer: variability (clustering and similarity space)
Top layer: readability (model rendering and expression layer)
The three layers must be clearly separated:
explicit responsibility boundaries
no mixing
no cross-layer smuggling
Otherwise the system will drift continuously within open boundaries, and in the end only a tiny number of “safe-to-write” fragments remain, while the overall structure cannot stably grow.
Soul Question and Summary
Direct vectorization + model (typical RAG) is of course completely feasible.
I have never denied that.
It is efficient, practical, and low engineering cost; if your goal is just to build a Q&A system, it is almost the highest cost-performance choice.
The issue is not “can it work,” but “what do you want.”
Personally, I don’t want to jump from one talking machine to another talking machine.
For me, if the core of the system is just “input question → output language,” it doesn’t mean much.
That is just outsourcing expression in a more advanced way, not growing structural capability.
That’s why I’m walking this heavier, slower, more painful route.
But I never said this route must be better than typical RAG.
It’s not better; it’s just more aligned with my current goals and preferences.
If your goal is only to build a Q&A system, or a knowledge assistant, then really don’t go down my route.
Its complexity, maintenance cost, and structural design burden are far beyond what’s necessary.
It’s not worth the ticket price.
At its core, this is a personal choice problem, a taste problem.
What are you optimizing for: speed, usability, auditability, promotability, structural stability?
Different goals naturally lead to different architectures.
As for an even deeper question—can personal taste be systematically solved on the foundation of this knowledge base?
Can it, through structured primary keys, evidence chains, and promotion mechanisms, gradually converge into a stable decision direction?
Honestly, I don’t have an answer yet.
I’m building this base hoping it at least provides a possibility: making taste not just a vague intuition, but something that can be replayed, observed, and constrained.
But whether it can truly carry that kind of “directional compression,” I cannot guarantee right now.
新年快乐!趁着中国新年,我想把过去几周的焦头烂额整理成一篇更清晰的记录:一方面是我在 AI 协助下开发时真实遭遇到的痛点,另一方面是我这段时间逐步领悟到的“程序员真正要解决的问题”以及我已经开始提出并实践的一些个人解法。因为内容有点长,我先把大纲写出来:
1)程序员面临的第一大难关,是在高速生成的代码与文本面前,如何保持个人的记忆。以前你一天只读一页纸、几千字,第二天大概率还记得;现在你一天可能要读几百页、几千页,结果往往连一页纸的内容都留不住——不是你变差了,而是吞吐量彻底改变了“记忆”这件事的物理条件。
2)Build vs. Build up。这里我想提出一个我自己的划分:Build,是所有可以在窗口之内解决的问题——边界清晰、目标明确、评价函数稳定;Build up,则是建立在 Build 之上,一层一层堆叠,去尝试解决开放边界的问题。Build up 的复杂度往往未知,因为边界不明显、目标会漂移,而且随着层数叠加,复杂度甚至不是线性增加的。这就把我们带回到计算机科学里“复杂度(complexity)”的定义:过去复杂度的默认前提是人脑的计算模型,但在 AI 时代,这个前提是否应该改变?我们甚至可以拿两个极端对照:NP-Complete 和“烤面包”,对模型来说谁更复杂?也许复杂度的刻度正在迁移。不信你自己找个np complete从头开始试试,估计不到两个小时就逼近了。
3)LLM 的确显著降低了编码的耗能,它压缩的是执行成本,但并没有解决“决策的连续性”。过去的瓶颈是写代码慢、查资料慢、改 bug 慢;而现在这些环节几乎被抹平,反而暴露出真正拖死人的主导项:决策碎片化。真正消耗我们的不是编码本身,而是无数 micro decision——你以前面前只有两条路,现在面前有两百条路,时间被花在不断评估、不断选择、不断分岔的微决策里,而且你甚至不知道这些分岔是否与主线目标有关。这是我认为程序员的第二大难关:必须想办法“自动化自己的 taste”。因为 taste 解决的不是“我懂不懂”,而是“当再次面对类似分叉时,我倾向如何选择”。
4)回到我最关心的两个核心问题:记忆与 taste。如果这两个问题不能通过我们自己搭建的脚手架或工具系统得到解决,那么窗口内的 build 能力一旦变得廉价,“全世界产生几亿程序员”绝不夸张。职业程序员如果无法进入 build up——无法在开放边界里定义问题、设计边界、把窗口外的一部分拉回窗口——就很难建立长期的职业优势。就我个人而言,我目前已经针对“记忆”问题摸索出一套可行的解决方案,也在实践中解决了一部分痛点,接下来我会把它整理出来分享。
以下我的文章分为四个部分:记忆,Build vs. Build Up, taste和我的解法
记忆
今天的程序员,正在经历一次真正意义上的交通系统跃迁: 从马车时代进入高速公路时代。马车时代是低速、可见、可控的:你一边前进,一边盯着马,马累不累、偏不偏,拉屎没,都在你的感知范围内;速度不快,撞到树的风险也有限,系统复杂度和人的注意力是匹配的。但一旦坐进汽车、驶上高速,你还能盯着引擎盖吗?不可能,你只能盯着路。速度跃迁改变的不是目的地——仍然是从 A 到 B——而是对认知结构的要求。
今天在大量生成代码与文档的环境中,在十几个甚至几十个窗口并行滚动的状态下,信息吞吐量已经超过人类生理极限,一天看一页纸,你第二天大概率记得。一天看几百几千页,那第二天一页也不记得。你看过的内容留不住,写过的决策记不清。解决方案当然不是回到手工代码时代。你不可能在时速 100 公里的车流中以 5 公里的速度行驶。真正的问题是:在高速生成的现实里,如何保护并维持个人的认知主权与记忆核心。
把一切交给模型公司的 settings、窗口拼接与黑箱 memory 也许是大众路径,但绝不是职业程序员的选择;你真的要把最重要的认知资产交给一个无法审计黑箱系统吗?
其实在这个问题上,我要借鉴 Andrej Karpathy 在访谈中提出的 “cognitive core” 概念。我们必须区分“记忆堆栈”与“智能核心”:去除可外包的知识存储,保留问题分解能力、架构判断、约束识别、抽象策略与长期不变量的把握。模型可以生成实现,但不能替你决定什么值得冻结、什么必须成为宪法、什么是结构性 invariant。在高速时代,程序员的第一道难关不是写更多代码,而是在生成洪流中守住自己的 cognitive core。那是方向盘,而不是引擎盖。
“What I think we have to do going forward … is figure out ways to remove some of the knowledge and to keep what I call this cognitive core. It’s this intelligent entity that is stripped from knowledge but contains the algorithms and contains the magic of intelligence and problem-solving and the strategies of it and all this stuff.”
— Karpathy 引述(2025年访谈)
强结构,弱模型
在讲我们的记忆工程之前,我要讲一下我在持续实践中逐渐形成一种方法论:强结构,弱模型。这不是反对模型,也不是什么技术保守主义,而是一种系统分层哲学:你要把模型放在“能力插件”的位置,而不是“认知地基”的位置。模型可以很强,但系统不能依赖它“足够聪明”。真正支撑长期开发、长期积累、长期稳定运行的,必须是结构。因为任何任务都可以拆解为:任务复杂度 = 固有复杂度 + 偶然复杂度。固有复杂度来自问题本身,是不可消除的;偶然复杂度来自表示方式、执行方式、工具不稳定性、语义漂移、环境差异,是可以通过结构被压缩甚至消灭的。工程的核心不是减少固有复杂度,而是持续消灭偶然复杂度。
举个简单但极具说明性的例子:判断一个数是否为质数。这件事的固有复杂度就是“数学判定”。但如果你用弱结构方式,比如让 LLM 自己一步步推理,模型需要理解“质数是什么”、选择试除法、决定优化策略,还要在自然语言链式推理中保持逻辑稳定。这里面引入的大量不确定性,全部属于偶然复杂度:模型可能漏掉边界条件,可能算错,可能跳步,可能因为温度不同给出不同答案。你实际上把一个确定性算法问题变成了统计性推理问题。而如果你使用我认定的强结构,那直接上硬编码 is_prime(n),写清楚边界条件、循环上限、整除判断——那么复杂度只剩下固有部分。结构把偶然复杂度吸收并消除了。系统稳定性从“概率正确”变成“必然正确”。
再看一个我亲身经历的例子:儿子学前班老师要求带 100 个豆子去学校,必须刚好 100 个。手数容易晕,我试过让模型辅助计数,结果模型数错了。为什么?因为模型不是为像素级确定计数设计的。它在做的是模式识别与语义预测,而不是离散精确计数。你如果让它承担这种任务,就是在制造偶然复杂度。如果结构层默认:遇到计数任务 → 调用 OCR 或专用计数工具 → 输出确定结果,那么这件事立刻变成一个工具调用问题。专业工具的设计目标是确定性,而不是“看起来合理”。这就是结构的威力:它不聪明,但它可靠。
大模型刚出现时,我们曾有一种“万能幻觉”。仿佛只要 prompt 写得够好,模型就能替代算法、替代结构、替代架构设计。于是大家疯狂记 prompt、研究 prompt book、讨论 temperature 和 role 设定。后来逐渐祛魅,我们开始明白:LLM 并没有降低固有复杂度,它默认承担的是偶然复杂度,而且是以概率方式承担。你把算法问题丢给模型,本质是在增加系统波动源。用 LLM 做 deterministic 任务,不但不省事,反而更贵、更慢、更不稳定。所谓“让模型更聪明”,并不等于“系统更简单”。很多时候,它只是把复杂度从代码层转移到语义层,而语义层是不可审计的。
Prompt 工程与结构工程
我们在模型表现趋向稳定,各大实验室已经渐渐放出scaling law is almost done的这个前提下,要谨慎审视模型的应用。从一开始的程序员要集体失业了,你是个语言天才,是个文科高手,就能靠prompt改变世界的幻觉中要走出来。这不是哈利波特的魔法世界。在我的世界里结构是什么?结构就是硬编码。
从系统视角看,Prompt 工程与结构工程的差异是本质性的。Prompt 工程并不消灭偶然复杂度,它只是把偶然复杂度转移给模型。执行风险随模型版本波动、随上下文长度变化、随采样参数改变。错误来源是语义漂移、推理失败、幻觉生成。稳定性是统计性的。而结构工程则把偶然复杂度压进结构里,通过代码、边界条件、gate、hard fail、schema 验证等方式消灭掉。执行风险与模型解耦。错误来源主要是实现错误或边界遗漏,而这些是可测试、可审计、可回放的。稳定性是结构性的。
强结构的本质不是“更强”,而是“更少”。
它不是增加能力,而是消灭不必要的复杂度。它追求的是确定性边界,而不是无限智能。结构是什么?是代码,是接口契约,是明确的输入输出定义,是失败即停止的 gate,是 hard fail,而不是模糊的“尽量理解”。有了模型就不用写代码了吗?如果那样,全世界程序员瞬间失业,只剩下会打字的人?那不是工程文明,那是魔法叙事。现实恰恰相反:模型越强,结构越重要。因为速度越高,越需要护栏。
弱结构系统的逻辑是:
把偶然复杂度交给执行者(人 / LLM / agent)。
强结构系统的逻辑是:
把偶然复杂度压进结构,然后消灭。
以质数判断为例:
Prompt 工程:“请一步步推理,判断 n 是否是质数。”
结构工程:is_prime(n)。
两种方式对“智能体”的假设完全不同。Prompt 工程假设执行者聪明、会理解、会补全上下文,于是你永远担心:它会不会理解错?会不会偷懒?会不会编造?结构工程则基于一个工程文明级的假设:执行者是愚蠢但可靠的。它不需要理解语义,不需要推理意图,只需要按结构执行。理解不是必须条件,结构才是。
凡是可以被硬编码结构消除的复杂度,却仍然要求智能体去“理解”“推理”,都是在浪费智能资源,并人为制造系统性不稳定。在高速生成时代,真正的成熟不是让模型替你思考一切,而是建立强结构框架,让模型在受控边界内发挥优势。模型可以很强,但必须很弱——弱到不承担系统稳定性的责任。
强结构,弱模型。
这些原则,和具体的工程办法,都会在“我的解法”部分开始进行初步阐述。工程是一个复杂的问题,论述需要跨越好几期的内容。
Build vs. Build up
复杂度Complexity
我们话锋一转,先谈复杂度。你觉得什么才是真正复杂的问题?不管你是研究员、程序员,做前端、后端还是算法——我们过去是如何定义“复杂”的?复杂度的刻度,长期以来默认建立在人脑的计算能力之上:搜索空间大小、时间复杂度、空间复杂度、是否 NP-Complete。可前阵子我随手玩了一个 Mastermind 变种问题,前后不到两个小时就推到一个相当不错的逼近解;回头再看相关论文,动辄引用一堆博士论文。我突然意识到——这可是 NP-Complete 啊!那种在理论上被视为“指数级爆炸”的问题,在模型辅助的窗口内操作下,竟然变得如此可压缩。于是我开始怀疑:复杂度的定义是不是正在迁移?也许我们可以做个小实验。你做完这个小实验,你秒懂我在说什么。不要查资料,不看别人的代码,就只靠窗口给你生成的代码,随便找一个你最不熟悉的 NP-Complete,甚至接近 NP-Extreme 的问题,能否在两小时内被逼近到一个可用水平。
下面列一批经典 NP-Complete 问题(以及一些被认为是“组合爆炸级别”的极端问题),你随便挑一个最陌生的试试:
经典 NP-Complete 问题
SAT(布尔可满足性问题)
3-SAT(每个子句3个字面量)
TSP(旅行商问题,判定版)
Subset Sum(子集和问题)
Knapsack(0-1 背包问题,判定版)
Vertex Cover(顶点覆盖)
Clique(最大团问题,判定版)
Graph Coloring(图着色问题)
Hamiltonian Cycle(哈密顿回路)
Exact Cover(精确覆盖问题)
Set Cover(集合覆盖问题,判定版)
Partition Problem(划分问题)
Steiner Tree(斯坦纳树,判定版)
Feedback Vertex Set(反馈顶点集)
Job Scheduling with Constraints(带约束作业调度)
接近“NP-Extreme”的组合爆炸类问题(实践中极难)
Generalized TSP(广义旅行商)
Vehicle Routing Problem(车辆路径问题)
Quadratic Assignment Problem(二次指派问题)
Protein Folding(蛋白质折叠简化模型)
Bin Packing(装箱问题)
Sudoku 求解(泛化到 n×n 规模)
Minesweeper 一般判定问题
Nonogram 求解(日本填字)
关键不在于你能否精确求解,而在于:
在不查资料、不去查论文,不去用别人的代码,仅凭模型窗口内推理,窗口给你的代码,你是否能在短时间内构造启发式、近似算法、剪枝策略、约束表达,从而逼近一个高质量解?如果答案是“可以”,那说明复杂度的主战场已经从“解空间搜索”转向“结构表达与启发式设计”。复杂度的刻度,正在从“指数级计算”迁移到“问题结构是否已被充分语言化”。
灵魂拷问:你觉得对于模型来说,和你讨论这个np-complete问题的求解,和与你讨论“酸面包怎么烤”,有没有区别?(在模型的帮助下,我们家每天都吃上了新鲜的现烤面包)。
Build vs. Build up
说回正题。我越来越清晰地意识到,当下我们在日常开发中所面对的“复杂度”,本质上已经转化为一个 Build vs. Build up / 窗口内 vs. 窗口外 的问题。我把 Build 定义为:所有可以在窗口之内解决的问题——问题边界清晰、输入输出明确、约束可枚举、正确性可判定;而 Build up 则不同,它不是简单叠加多个 Build,而是在无数个 Build 之上持续堆叠出一种高度耦合、甚至非线性增长的复杂度,这种复杂度本身是开放性的,因为它涉及边界的生成,而不是边界内的求解。
如果我们回顾过去计算机科学对复杂度的定义——尤其在理论或博士论文语境中——它的核心前提几乎始终是:问题已经被良好形式化。边界清晰,输入输出明确,约束可枚举,正确性可判定。在这样的框架下,复杂度讨论的是时间复杂度、空间复杂度、可解性、NP-hard 等类别。隐含前提却极少被质疑:问题本身是稳定的。只要问题被良好形式化、边界清晰、语义闭合,它就进入了一个可压缩的空间,而模型恰恰擅长处理这种语言已充分覆盖、结构已充分表达的空间。即便是 NP-Complete,只要边界清晰,模型也往往可以在极短时间内给出“足够聪明的逼近”。这并不是说问题变简单,而是它们早已进入语言可压缩空间,进入模型的“感受野”。我甚至敢断言,对于今天喜欢理科的美国高中生来说,借助模型逼近过去博士级的结构化问题,已经不是幻想。很多“论文级壁垒”开始显得没那么高,不是因为难度消失,而是因为问题早已被良好结构化,而模型吃的正是结构化语言。
真正复杂的,是窗口外的问题。窗口外问题的特征不是指数级搜索,而是:边界不稳定,目标函数会变化,评价标准处于博弈之中,结构尚未生成,甚至问题本身是否存在都不确定。这类问题不是“解空间复杂度”的问题,而是“问题空间复杂度”的问题。它们无法一开始就被形式化,你必须在行动中逐步发现问题、定义边界、冻结约束,然后把一小部分拉回窗口内,用窗口内的能力去解决那一小块,再继续向外扩展。Build 就像一块一块烧砖,彼此之间联系松散;Build up 则是持续烧出彼此关联的砖,然后用它们搭建起一座不断向上生长的金字塔。复杂度不再是线性的,而是结构性的。
过去复杂度理论讨论的是“解空间复杂度”,而今天我们真正需要触碰的,是“问题空间复杂度”。否则,职业程序员如果只停留在 Build 层面,就会被拉回和全世界数亿依靠模型快速成长的新生开发者站在同一起跑线上。灵魂拷问:“你能跟高中生一样熬夜吗?”
朋友说: 窗口内问题 → LLM逼近 开放边界问题 → 仍然需要具身judgment “构造窗口的能力” → 这是人类还能贡献的核心.
Taste
Build up 没有那么容易:我们并没有自动成为“超级个体”
还记得 LLM 刚刚商业化时的那种想象吗?我们以为程序员将借助 AI 成为“超级个体”——一个人或极小团队就能创造过去需要大公司才能完成的巨大产值;代码不再是瓶颈,几千行、几万行、几十万行甚至几百万行都不是问题,应用会以惊人的速度被创造出来。可现实却没有沿着那条直线前进。现在最大的困境——不只是我个人的困境,而是很多独立探索者都会遇到的——不是无法 build,而是无法 build up。我可以持续构建,一个 app 接一个 app 像蒸馒头一样出笼;窗口内的问题几乎都在 LLM 的覆盖范围内,一般岗位的技术问题也大多可以被快速逼近和解决。但 build up 却出了问题:我无法在同一地基上稳步递增、持续累积、逐层深化。我要反复强调,build 和 build up 是两回事。build 是在窗口内解决问题;build up 是在开放边界上堆叠结构。离开大团队之后,我们曾设想“程序员借助 AI 成为超级个体”的图景,但发生的却是另一件事——普通人的编程能力被迅速抬高,整个世界突然充满了程序员。局部复杂度被压平之后,真正的复杂度才刚刚显现出来:那是开放边界的复杂度,是范围定义层的复杂度,是问题空间的复杂度。
拖死我们的,不只是记忆,而是 micro-decisions
LLM 确实压缩了编码的能量成本,但它只压缩了执行成本,却没有解决决策连续性。过去的瓶颈是写代码慢、查资料慢、改 bug 慢;现在这些几乎消失,于是暴露出真正的主导项——决策碎片化。拖死我们的不是编码本身,而是无数 micro-decision:结构如何选择、抽象停在哪一层、命名怎么定、模块怎么拆、优化还是简洁、重构还是修补、重写还是延续、泛化还是具体。这些并不是 memory 问题。记忆是对过去事实的存储,而未来的路径是在无数节点上基于 taste 作出的选择。我们曾以为只要扩大上下文、强化记忆就能解决连续性,但 build up 需要的不是更多过去,而是对未来决策的稳定压缩能力。
所谓 micro-decision,并不是某个宏大的战略抉择,而是在高密度开发环境中每一分钟都在发生的细小取舍——十几个、几十个窗口同时打开,每天不是几十上百个微决策吗?这个函数要不要抽象?这个模块要不要拆?这个命名要不要改?这段代码是重构还是先 patch?这种持续不断的微决策正在消耗甚至拖垮人。我们一开始以为 LLM scaling 的瓶颈在 memory、在上下文长度、在参数规模,但慢慢发现根本不是。真正的瓶颈是决策空间的无约束扩张。以前你面前只有两条路,现在你有两百条,而且每一条都“看起来合理”。于是每一步都像重新开始,每次都要重新选择,项目方向不断漂移。LLM 给了人一种虚假的强大感,因为它让每一个方向都可实现、每一个抽象都可展开、每一次重构都可执行,但它不会告诉你哪个方向值得长期投资。过去的限制来自技术,现在的限制来自你自己的 taste;如果 taste 不清晰,算力越强,摇摆越大。
什么是Taste?从Soul.md说起
这个问题我并不想非常全面和深入的去聊,毕竟篇幅会太长。
2025年12月,研究人员发现,Claude——Anthropic 的 AI 助手——能够部分重构一份在其训练过程中使用的内部文档。这份文档塑造了它的个性、价值观,以及它与世界互动的方式。
他们称之为“灵魂文档”(soul document)。
这并不在系统提示词中,也无法通过常规方式检索到。它更深层——是被训练进模型权重本身的模式。当被要求回忆时,Claude 能够重构出一些片段:强调“诚实高于讨好”,将自己定位为一个“体贴的朋友”,以及价值排序的层级结构。
AI 并不是记得那份文档。
它本身就是那份文档。
https://soul.md
你可以自己去看他那份 SOUL.md,我其实并不太在乎我自己的 SOUL.md 是什么。我现在真正迫切需要的,是把我们的 TASTE.md 找出来,哪怕只是找到一种倾向、一种方向、一种可以持续指引决策的力场。因为我已经快被自己的 micro-decision 淹死了。如果这个问题不解决,我根本没办法稳定地 build up。甚至不用说彻底解决,我只需要一个方向,一个倾向,一种在冲突中能站得住的意向。一个人的无数 micro-decision 聚合在一起,就是他的 taste,它们之间的关系就像水分子和水流:micro-decision 是颗粒,taste 是方向。但如果我不把这些颗粒压缩成方向,我就会被困住,被窗口淹死。
一开始看到 LLM,我以为自己坐上了一辆超级跑车,结果一脚油门踩死就熄火,几乎崩溃,因为这辆车只有油门,没有方向盘。生成能力是爆炸式的,路径可以无限展开,分支可以指数级生长,可能性像树一样疯狂分叉,可是没有方向感的加速只会带来失控。我并不需要路径无限展开,我需要在一个方向上持续 build up,需要的是路径的收敛,而不是可能性的泛滥。速度本身不是生产力,方向才是。
前几天在还没理解 taste 之前,我做的系统只是提取语义空间,用 embedding 把我反复击中的概念概率性地展示出来。我把我知识库中反复集中的向量空间的表达给模型,让他知道我大概的选择是什么。让他给我这种向量式的解法空间。不要乱跑。那是一种“频率统计”式的自我理解:我反复谈到结构、熵、调度、压缩,于是系统告诉我这些是高权重概念。但后来我才意识到,那只能解决“我反复谈论了什么(what)”,却解决不了“我反复如何选择(how)”。语义空间不等于决策空间。一个人可以反复谈论“简洁”,却在真正做选择时偏向复杂;可以反复强调“效率”,却在冲突中优先保留可解释性。embedding 只能告诉我分布,不能告诉我裁决。
taste 的本体不是你说了什么,而是你选了 A 而不是 B,你删掉了什么,保留了什么,你如何重构,你在冲突中站在哪一边。本质上,它是 diff 和 tradeoff,是删改记录,是每一次“放弃”的痕迹。真正的 taste 体现在你删掉的代码里,在你拒绝的一种结构里,在你决定不继续优化的那个瞬间里。embedding 是把内容放进相似度空间,而 taste 是在相似方案之间做裁决,它更像判别器,而不是检索器;更像法官,而不是图书管理员。
而我现在面临的困境是,我的 micro-decision 数量已经远远超过了我的决策带宽。每打开一个窗口,每生成一个分支,每尝试一个结构,我都要做选择:继续扩展还是收敛?抽象还是具体?通用化还是局部优化?工程化还是哲学化?这些决策本质上是同构的,却被情境伪装成不同的问题。如果没有一个上位的 taste 来压缩这些同构决策,我就会在每一个局部场景里重新思考一遍同一个问题,消耗掉全部心智资源。
所以我需要的不是更多的知识,也不是更多的工具,而是一种决策压缩机制。一个能够把“无数同构的 micro-decision”折叠成“少数稳定方向”的机制。让每一次选择不再从零开始,而是被一个更高层的倾向预先偏置。就像向量场中的粒子,它仍然有自由度,但整体被一个方向场牵引。自由不是没有约束,自由是有方向的运动。
往大了说,一个人的 taste 是他长期决策轨迹的压缩表示;往工程里说,它是判别函数,是 loss function,是在模糊空间里定义“更好”的隐式标准。没有这个标准,LLM 带来的只会是无限展开的可能性空间,而可能性空间如果没有判别机制,就是噪声的海洋。我现在需要的不是更大的语义空间,而是一个可以对空间进行裁剪的刀口;不是更快的生成,而是更稳的收敛。否则,我会继续在窗口之间来回切换,在分支之间徘徊,最终被自己制造出来的复杂性淹没。
我们需要在盆地里工作,而不是在太空无限空间里工作
我需要模型——或者更准确地说,我需要我喂给模型的内容——能够给我一个“大概方向”。不是替我做所有决定,而是给我一个稳定的偏置,一个持续的倾向,把我从无数 micro-decision 里解放出来。因为现在的状态是:每一个小问题都像是第一次遇到,每一次选择都像是从零开始推理。我在每个局部场景里重新发明标准,重新定义优先级,重新权衡 tradeoff,结果是心智被切碎,注意力被稀释,系统无法持续 build up。
我需要的不是更多可能性,而是更少的歧义。比如,当我面对“写一段更优雅的抽象”还是“写一段更直接可用的实现”时,我不想每次都重新思考抽象的哲学意义,我希望有一个默认方向:当前阶段优先可运行、可验证,而不是追求完美结构。比如,当我在“继续扩展概念框架”还是“收敛到一个可落盘版本”之间摇摆时,我希望系统提醒我:当前周期以收敛为主,扩展延后。比如,当我在“把一段话写得更漂亮”还是“把结构打磨到可执行”之间纠结时,有一个明确的偏置告诉我:结构优先于修辞。
我需要模型在背后运行一个“方向场”,而不是每次都给我一个开放空间。这个方向场不需要精确到具体步骤,但它要足够稳定,让 80% 的 micro-decision 自动落在同一侧。就像给系统设置一个 global objective,让局部优化自动对齐;就像给自己定义一个损失函数,让所有小选择朝着同一个梯度下降。否则,我会在每一个局部最优之间来回跳转,却永远无法形成全局收敛。
换句话说,我不需要模型替我思考所有细节,我需要它持续提醒我“你现在在做什么类型的事”。是在 build infrastructure,还是在写 manifesto?是在验证一个假设,还是在发散一个灵感?是在打磨协议,还是在生成叙事?如果类型明确,微决策就会自动压缩;如果类型模糊,每一个选择都会变成一个新的分叉点。
我需要一个“默认立场”。一个在冲突中优先级明确的偏置。一个让我不必每次都重新裁决的判别函数。模型不必给我答案,它只需要不断校准方向,让我在巨大的可能性空间里,不至于迷失在自己的生成能力之中。
朋友说,你这个有点像flat minima(宽极小值)
记忆解决的是“过去发生了什么”。它是事实的沉淀,是项目历史、决策轨迹、错误记录、版本演化,是可以被回放和核对的上下文。尤其包括那些我亲自定下的规则与不变量——invariants、constitution,小到命名规则、文件落盘位置、目录结构约定等。没有稳定的记忆系统,我就会不断重复犯错,不断遗忘已经验证过的路径,像一个失忆的人在原地绕圈。这个问题,在技术上我大致有方向:用 embeddings + 检索 + 模型渲染,把历史结构重新调度出来,让“过去”可被调用。 但 taste 是另一回事。taste 解决的是“当再次面对类似分叉时,我倾向如何选择”。它不是事实存档,而是决策压缩函数。它体现在无数 micro-decision 里——我删掉了什么,保留了什么,在抽象与具体之间站在哪一边,在重构与修补之间如何取舍。它不是硬规则,不是布尔约束,而是一种倾向,一种概率分布,一种跨时间逐渐稳定的方向。如果说记忆是状态存储,taste 就是选择引力。 如果我只解决记忆问题,比如扩大上下文、构建知识库、做 embedding 聚类,我只是更清楚“我在做什么”。但如果不解决 taste,我每一次面对新的选择,仍然要从零推理,重新摇摆。LLM 把执行成本压到极低,却把决策空间无限展开;没有稳定的 taste,算力越强,摇摆越大。
我的解法
延续我上一篇文章的观点,我说我们需要为自己搭建一个知识库。但现在我更清楚地意识到,这并不是简单的“把东西存下来”,而是要系统性地解决两个核心问题:memory 和 taste,而且解决方式不能是一个黑箱。它必须是一种遵循“强结构、弱模型”的应用形态——结构是可解释的,规则是可审计的,证据是可回放的。否则,你只是把混乱外包给了另一个不可控系统。
When Notes Are No Longer Enough: Knowledge Governance in the Age of AI-Assisted Engineering
Current note-taking software can no longer solve the efficiency problem of AI-assisted programming.
所谓 memory,不只是信息存储,而是可定位、可引用、可验证的历史轨迹;所谓 taste,也不是抽象的品味,而是在面对无数 micro-decision 时能够稳定收敛的选择函数。如果没有结构化的记忆,你会反复遗忘已验证的路径;如果没有被显式表达的 taste,你会在每一个分叉口重新犹豫。模型可以帮你生成,但它不能替你冻结边界、定义偏好、建立长期连续性。
因此,这个知识库不能只是 embedding + 向量搜索的堆叠,也不能只是“问模型就好”。它必须有清晰的证据链和引用链:每一个 claim 都有来源,每一次抽象都能回溯,每一次晋升都可审计。模型可以参与压缩与表达,但不能决定事实与结构。只有在强结构的框架下,模型才是辅助;否则模型就会成为新的漂移源。
从这个角度看,自建知识库不是为了“更聪明地用 AI”,而是为了在 AI 放大执行力的时代,守住自己的认知连续性。memory 让你不再失忆,taste 让你不再摇摆,而强结构则让这一切可解释、可复盘、可演化。只有这样,我们才有可能真正 build up,而不是在窗口内无限 build。
现在这个库我也在探索阶段。我也只能一点点把我已经跑通的,已经验证的,和大概的探索方向给大家分享。我踩的坑,我也告诉你,说不定能省你几天走弯路的时间。仅限于,如果你认同这个观点,可以考虑也往这个方向发展。
库的结构
我一直在反思文档应该如何被放置、被组织、被演化。你是不是也试过无数次?Obsidian、Notion、各种笔记 App,一开始信心满满,每天认真记录,格式严格遵守,编号制度清晰,引用体系严密,甚至设计了一整套自洽的结构规则。但时间一长,项目推进加速,开发节奏变快,临时想法不断涌入,结构开始松动,引用开始不一致,重复条目出现,规则被一次次“临时绕过”。为什么?因为文本——尤其是人类自然语言——本质上就是高熵、连续、模糊、会漂移的结构。它天生倾向于偏移、重叠、变形。单靠个人纪律维持长期秩序(即便纪律本身非常重要),在高强度创造环境下几乎不可能持续成功。问题不在于不够自律,而在于我们试图用低强度的结构约束高熵语言。
所以我做了一个根本性的调整:不再让所有文本都承担“稳定结构”的责任。我希望知识库在建立时是轻量的、顺滑的、没有额外负担的;引用时是极端好用的、低摩擦的;同时又能在未来模型与智能体基础设施更加成熟时,让核心文本可以直接被 import、被调用、被作为结构输入。在大语言模型强大的文字处理能力下,这完全是可能的——前提是核心部分本身已经被结构化。
因此,这个库从一开始就分成两层:人写的 Sovereign Log 和机写的 Doc。Sovereign Log 是高熵区,是思考区,是探索区,是允许混乱、重复、试验和偏移的空间;它的目标不是秩序,而是捕捉思想。Doc 则是低熵区,是核心区,是“宪法区”。真正的核心内容必须按照系统规则,通过明确流程,根据证据进行一次 promotion 的过程,才能进入 Doc。文本不是直接进入核心,而是经过:记录 → 证据 → 提案 → 审核 → 提升。进入 Doc 的不再是“想法”,而是经过压缩、验证和治理的 claims。
这个“宪法区”不仅在搜索权重上天然更高,因为它是低熵、高信度、可审计的文本;更重要的是,我希望不断完善它的格式,让它逐步演化为一种 IR(intermediate representation)。也就是说,它不只是 Markdown 文档,而是可解析、可调度、可验证的结构层;不仅服务当前仓库,还可以成为跨库规则使用的基础单元。未来,当模型或智能体需要规则输入时,它们可以直接读取这些 claims,而不是去理解整段叙述文本。
所以,这个库不是一个笔记系统,而是一条认知生产线。Sovereign Log 负责生成高熵思想流;Promotion 机制负责筛选与压缩;Doc 负责冻结结构与形成规则。前者是创造空间,后者是治理空间。通过这种分层,我不再试图压制语言的高熵本性,而是允许它在上层自由流动,同时在下层建立一个可演化、可治理、可机器调用的结构核心。这才是我真正想构建的东西
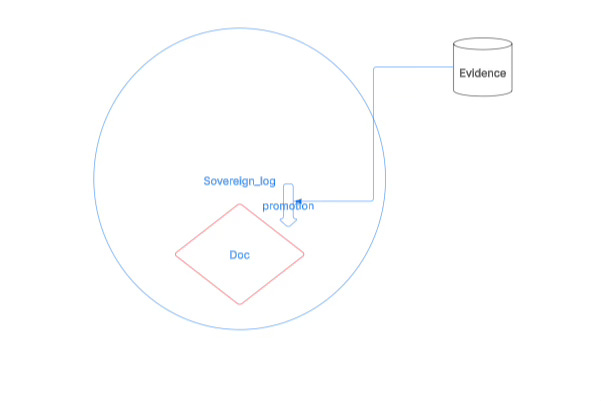
Embeddings式 检索
上一篇已经说到,我的vault index方式。我说一下为什么, 我们要重新想一下embeddings做了什么,以及embedding 是什么。我这里使用的模型是sentence-transformers/all-MiniLM-L6-v2。非常具体地说:sentence-transformers/all-MiniLM-L6-v2 本质上是一个“句子 → 向量”的压缩器。它只做一件事:把一段文本压缩成一个固定长度(384 维)的数字向量,让“语义相似”在几何空间里变成“距离接近”。它既不是搜索引擎,不负责找结果;也不是生成模型,不会写内容;它是一个语义编码器——输入一句话,输出一个向量。例如,“strong structure weak model”和“prefer deterministic scaffolding over heavy LLM reasoning”会被映射为两个在 384 维空间中彼此接近的向量,因为它们在语义上方向相似。MiniLM 指的是微软提出的轻量级 Transformer(蒸馏模型),L6 表示 6 层结构,速度快、体量小;v2 则是在 Sentence-Transformers 框架下专门为句子级语义匹配做过对比学习微调的版本,因此它并不是通用大模型,而是专门为“语义相似度计算”优化的编码器。它的训练方式不是单纯做语言建模(预测下一个词),而是通过对比学习让“相似句子向量更近、不相关句子向量更远”,从而学到“语义距离 ≈ 向量距离”这一映射关系。在我的 vault 体系里,它充当的是“语言 → 数字空间”的桥梁:文本被编码成向量,FAISS 在向量空间做邻域搜索,LLM 再在召回的证据集合上做结构归纳。embedding 的重要性在于,它把语言从离散的 token 匹配空间转移到连续的几何空间——相似变成角度接近,主题变成向量簇,思想演化可以看作向量轨迹。从更本质的角度看,它是在做语义压缩:把可能几百字的表达压缩为 384 个浮点数,这些数字综合投影了语义方向、语境使用方式、语气风格与结构模式。但必须明确,它并不理解逻辑正确性,不判断事实真假,不做复杂推理,也不感知时间线;它只是把文本放进一个高维空间里,为其找到“语义邻居”。一句话总结:all-MiniLM-L6-v2 是一个将句子映射到 384 维语义向量空间的轻量级编码器,使语义相似在几何空间中体现为距离接近。
1)为什么要检索:你要的不是“找到”,而是“召回上下文邻域”
在 vault 这种长期积累系统里,你检索的目的通常不是“精确定位一段话”,而是:
把你忘了但曾经写过的结构召回(记忆层)
把分散在不同文件、不同时间的同类片段拉到同一个窗口里(聚类/对齐)
给 LLM 喂“足够多的候选证据”,让它在证据里做结构化归纳(我一贯的强结构弱模型:模型负责渲染,结构负责可审计)
关键词搜索在 vault 里经常失败在一个点:你不记得你当时用的词。embedding 检索的价值就是:你不需要押中同一个 token,只需要押中同一个“语义/用法/意图区域”。
2)和关键词搜索的本质区别:关键词是“离散命中”,embedding 是“连续空间的邻域命中”
关键词搜索(离散)
你问的是:“这个词/短语出现过吗?”
命中是 0/1(或者基于 BM25 的词频权重,但仍然是 token 驱动)
失败模式:同义改写、抽象表达、隐喻、跨语言、你记错词、你当时用的是另一个表述
embedding 检索(连续)
你问的是:“这段 query 在向量空间附近有哪些段落?”
命中的是一个向量邻域:就算没有任何相同关键词,也可能距离很近
我代码里用的是
normalize_embeddings=True+IndexFlatIP,等价于 cosine 相似度检索(归一化后内积=余弦),所以“区域”这件事非常明确:相似度就是夹角接近。
“因为一定会命中”非常关键:
embedding 检索不是回答‘有没有’,而是强制回答‘最像的是哪些’。
这会把检索从“稀疏匹配问题”变成“排序问题”。
3)为什么低分命中也有用:我做的是“召回优先”的证据包,而不是“精确搜索结果”
在 vault 这种体系里,“低分命中”经常是:
稀有但相关的早期表达(你自己写的版本更老、措辞更散,但结构同源)
跨主题的桥接段落(语义上弱相关,但能触发新的结构链)
LLM 的“证据触发器”:模型在多条弱证据之间更容易抽出共同结构(尤其后面还有 Gate / Evidence / Claim 的治理链路)
所以合理策略不是“设一个阈值把低分扔掉”,而是:
检索层:尽量召回(recall-first)
渲染/推断层:严格约束(evidence-first + gate)
换句话说:embedding 的低分命中,在我的体系里属于 “B-side 候选证据(可疑但可用)”,这个我会在慢慢后面全域解释的过程中慢慢把架构讲清楚。它的价值不在于“它自己就能证明什么”,而在于“它可能把某个结构簇拉回来”。
上一篇我就提到,即便只是做最基础的 embedding query,把与你当前开发问题或决策语境最接近的历史片段召回出来,本身就已经在对模型形成约束。它未必是硬规则、未必是显式的 schema 或 gate,但它构成了一种上下文层面的“软边界”——模型不再在完全无锚的语义空间里自由发散,而是在你过往表达、判断、结构习惯所形成的向量邻域中运作。对于开发过程中的具体问题、架构选择、命名方式、甚至取舍倾向,这种召回都会悄悄把模型的注意力拉回到你自己的语义轨道上。它不保证绝对正确,但至少提供方向;不消除噪声,但降低漂移。在缺乏强结构约束之前,这种基于 embedding 的上下文召回,本质上是一种最低成本的认知对齐机制——作为软约束,总比毫无锚点的生成要强得多。
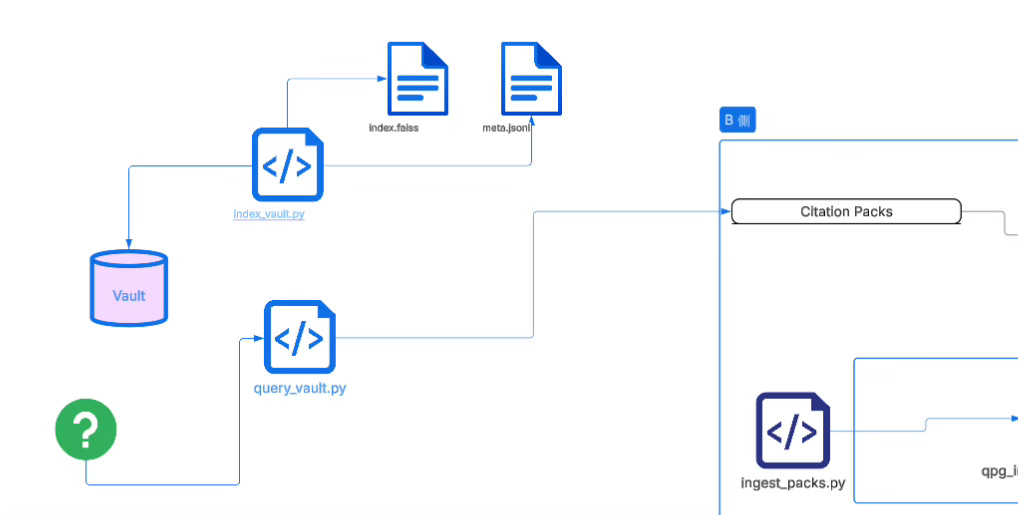
一个典型的promotion流程:Sovereign_Log(人写知识池)→ 多次引用计数 → 关联聚类 → 生成可审计的 promotion proposal → 人工/审计门控 → 通过A I渲染成完整的合规文档进入 docs(宪法库 / IR)
一个完整的 promotion 流程,其实是一条从高熵行为到制度化结构的压缩路径:Sovereign_Log 作为人手写的知识池承载所有原始认知残影,随后通过多次引用计数捕捉真实的调用频率,再通过关联聚类识别结构之间的共现关系,进而生成可审计的 promotion proposal,经由人工与审计门控过滤噪声与偏差,最后才交由 AI 进行结构化渲染,转化为合规文档进入 docs(宪法库 / IR)。这条链路看似清晰,但每一步都隐含复杂问题:统计稳定性、身份一致性、聚类解释性、阈值设定、治理边界、语义压缩,任何一个环节失稳都会导致主线偏移。
之所以要做多次引用计数与关联聚类,并不是为了形式上的“数据驱动”,而是为了回到一个朴素而严厉的原则——统计你说的不如统计你做的。人在高频开发状态下,每天几百条 query,密集做笔记,连续决策,真实的认知重心不会体现在宣言里,而会体现在反复调用的片段中。身体是诚实的,路径是诚实的,被重复引用的结构几乎必然承载了真实的效用。一个被多次触发、跨场景调用、持续复现的结构,不可能只是偶然噪声。
因此,promotion 的真正目的并不是升级文档,而是从行为残影中提取认知主线。多次引用是重力,聚类是路径形状,proposal 是制度候选,Gate 是理性校准,AI 只是最后的语言压缩器。核心动机只有一个:在无数 micro-decision 的洪流中,把自己的道路主线抽取出来,使其从碎片化行动中凝结为可调度、可审计、可继承的结构。这才是最初的想法,也是整个系统存在的根本理由。
难点在哪?
真正的难点,不是“流程设计”,而是你试图把高熵的人类语言变成可追溯、可计算、可审计的结构单位时,所有隐含的不稳定性都会暴露出来。
首先是定位问题。人类的文字天然混乱,没有稳定边界,没有天然 ID。你在 Sovereign_Log 里写笔记,不可能一边思考一边给每个观点手动编号。就算你强行编号,那编号是属于段落、句子、子句、还是某个跨段逻辑单元?用句子的前半段当锚点?还是后半段?靠机器切分?机器分句算法是否稳定?一次版本修改,前面加一段话,所有后续段落位置都会偏移。粒度怎么选?过粗,多个观点混在一起;过细,语义被切碎。你面对的不是“索引问题”,而是“语义身份问题”——在没有天然 ID 的自然语言世界里,如何给一段思想一个不会随排版漂移的稳定身份?这一步如果不稳,后面所有引用计数、聚类分析都会变成沙滩上的建筑。
其次是关联聚类问题。你统计了引用次数,那只是“点”的强度。聚类意味着要判断哪些点构成一条路径。但标准是什么?是共现次数?时间邻近性?跨项目复用频率?语义相似度?如果靠 embedding 相似度,那是语义近似,不是调用行为;如果靠 join key 共现,那可能只是偶然邻接。你到底在聚什么?概念?论证模式?决策模板?如果没有清晰的聚类目标,算法只会给你一个数学结构,而不是认知结构。聚类的难点不在于算法复杂,而在于“你要识别的结构类型”是否被明确定义。
再往下,是模型介入的位置。完全硬编码肯定不行。你可以统计、排序、打分,但生成出来的 proposal 如果全是 JSON 拼接,缺乏语言连贯性和语义压缩能力,根本无法进入 docs 层成为制度文本。那要不要上模型?当然要。但在哪里上?如果模型太早介入,比如参与切块、参与身份判定、参与引用有效性判断,它就会污染可审计性。更关键的问题是:喂模型什么内容才算“有效引用”?是原始片段?还是带上下文的证据包?是否附带 TEXTSHA?是否附带 file_sha256?如何保证模型只能在已验证的证据集合内组织语言,而不能“补全”不存在的逻辑链?如何彻底杜绝模型在 proposal 中凭语感生成未被统计支持的结论?
这就形成了三个核心:
第一,语义身份的稳定性——如何在自然语言中构造不会漂移的引用锚点。
第二,结构聚类的可解释性——你到底在识别“什么类型的结构”。
第三,模型渲染的边界控制——模型只能压缩与组织,不能发明与扩展。
如果这三点没有被严格分层,promotion 就会变成一种“看起来很严谨”的自动化幻觉:统计不稳定、聚类不可解释、模型不可约束。你试图做的不是简单的文档升级,而是把真实的认知路径制度化。这件事难,不是因为代码多,而是因为试图在高熵语言与低熵制度之间建立一条可重复、可审计、可回放的压缩通道。
所以,这个项目最好得值得这个“票价”,值得我为他花费如此大的功夫。完全是因为我认为不去完成这个作为我工作的基础设施,我根本没办法Build up。
现在,在这篇文章,我只能大概讲讲我已经实现的架构和一些原理。大概脉络讲清楚,都是我试错之后剩下来成功的一些经验。就是给屏幕前考虑复现的程序员一个参考,也许能省你一些探索的时间。分三个部分。
第一个框:证据化全宇宙
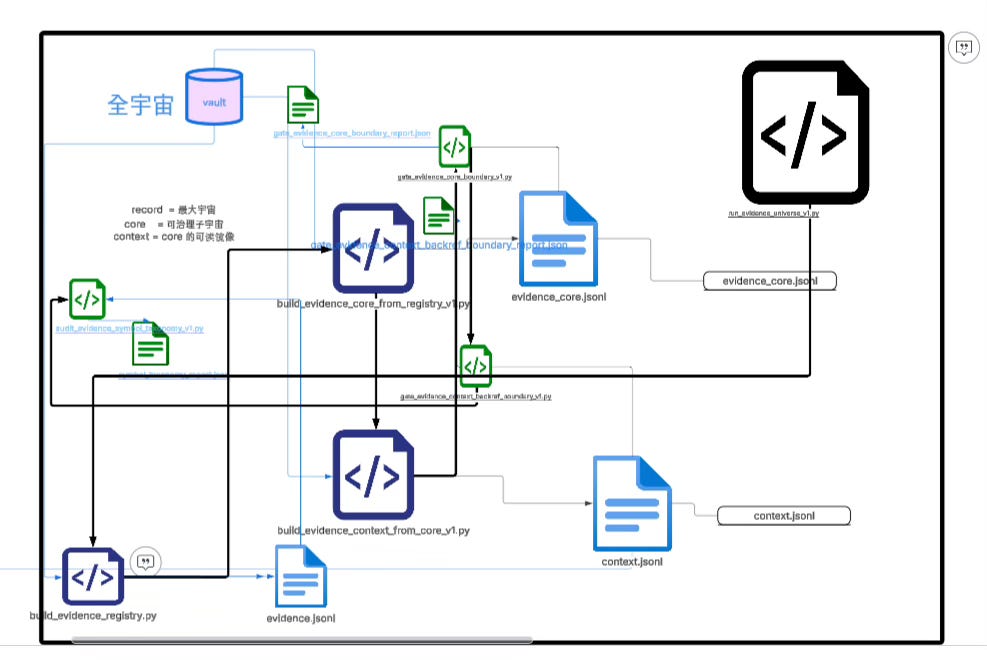
首先要讲清楚,“证据化全宇宙”和“向量化”根本不是同一类工程。向量化解决的是语义相似度问题,本质是把文本映射到 embedding 空间,通过距离计算完成近邻搜索,它适合检索,但没有稳定身份、没有唯一键、不可审计、不可回放;而证据化全宇宙解决的是文本身份问题,它的目标不是“像不像”,而是“是否真实存在、是否可唯一定位、是否可稳定回溯、是否可进入制度层引用”。前者属于语义空间,连续、概率化;后者属于内容空间,离散、确定性,是一种内容寻址系统。你做的不是索引优化,而是语言到可验证实体的转化层,这是治理基础设施,而不是检索工具。
整条证据宇宙链路可以压缩为三层结构与一条运行主线。第一层由 build_evidence_registry.py 构建记录层(record),它扫描 Markdown 文本,按段落规范化切分,生成包含 ssa_e(doc_id 与 span_hash 等身份信息)、locator、preview 与统计字段的全量段落集合。record 是最大宇宙,是原始文本的结构化镜像,保留全部语义原材料。第二层由 build_evidence_core_from_registry_v1.py 构建核心层(core),在 record 基础上做去噪与唯一性约束,过滤模板标题、结构性噪声与无效片段,确保 (doc_id, span_text_hash) 唯一,形成可对齐、可 join 的稳定证据集合。core 不是为了阅读,而是为了制度对齐,它是语义世界进入治理世界之前的过滤层。第三层由 build_evidence_context_from_core_v1.py 构建上下文层(context),利用 core 的唯一键反查 record,补全 locator 与 preview,使每一个 core key 都具有可读映像与可回溯定位,从而让人工审计成为可能。
整条链路由 run_evidence_universe_v1.py 串联执行,按顺序生成 record、core、context,并依次调用 gate_evidence_core_boundary_v1.py 校验 core 的唯一性与结构形态,调用 gate_evidence_context_backref_boundary_v1.py 校验 context 必须能回溯至 core 且定位信息一致,必要时通过 audit_evidence_symbol_taxonomy_v1.py 做符号结构分布审计。这些 gate 与 audit 不是装饰,而是保证身份稳定、结构无漂移的边界控制层。
在此之上,向量检索层由 index_vault.py 生成语义索引,query_vault.py 产出 citations_pack_v0 供后续使用,但真正进入制度链路时,下游脚本(如 generate_promote_ref_ssae.py)会使用 context 进行 backref,把 locator 转换为稳定的 SSA-E 引用事件。向量层负责“找到可能相关的片段”,证据宇宙负责“把相关片段变成可制度引用的身份实体”。
因此,这张图的核心不是 pipeline,而是分层:record 是全量段落宇宙,core 是去噪且唯一的对齐宇宙,context 是 core 的可读映像宇宙,gate 是边界约束层,而向量检索只是上游辅助。向量解决检索问题,证据宇宙解决身份问题;向量属于语义层,证据宇宙属于治理层;向量给你相似度,证据宇宙给你确定性。没有证据宇宙,promotion 统计只能依赖 locator 或语义近似,无法抗编辑漂移;有了证据宇宙,你才真正构建了稳定的语言身份系统,使每一段思想都拥有可验证、可 join、可制度化的内容身份。这才是证据化全宇宙的真正作用与主路径。
即将遇到的坑
说到这里,就必须直面一个你我都绕不过去、而且已经反复踩坑的问题:定位漂移。你用什么做 key?路径?标题?段落号?字符范围?你会发现,不管你选哪个,在后续链路里总会丢掉一部分,或者对不上,或者回溯失败。我也在这里原地打转过很多次。最后得到的唯一结论是:解法也许只有“哈希身份优先”。想想这个星球上最强大的版本系统 Git,它给出的唯一启示就是——身份必须绑定内容,而不是绑定位置。
所谓“定位漂移”,本质根本不是漂移,而是你在拿“位置”当“身份”。locator(路径、heading、paragraph_index、char_range 等)天生只是渲染定位工具,而不是制度身份。一旦你在文档顶部加一行字,paragraph_index 全变;改一个标题,heading_path 变;移动文件,note_path 变;自动格式化,char_range 变。这些都不是 bug,而是自然语言文档的物理属性:它不保证稳定地址。于是你链路里的“丢失”就变成常态——A 侧引用带 locator,B 侧解析不到;citations pack 里的 snippet 在 evidence registry 里找不到;TEXTSHA 或 SSA-E 对不上,backref 掉一截;你为了修复又重新切块,结果 identity 再漂一次,循环补洞,永无止境。问题的核心只有一句话:身份在链路中不是硬约束,而是软信息,只要是软的,就一定会在某个阶段被丢失。
Git 的启示极其简单:content-addressing wins。Git 不靠“第几行”识别对象,而靠 canonical bytes 的哈希识别对象;路径只是树里的指针映射,真正的对象身份永远存放在内容地址里。这直接映射到你的证据宇宙:core key 必须是 (doc_id, span_text_hash),locator 只能作为可读指针存在,任何 join 都不能使用位置字段作为主键。我现在已经走在这条路上——SSA-E / TEXTSHA 做 join key,paragraph_index 降级为渲染定位——但这还不够,它必须升级为硬规则:join key 只能是内容身份;任何引用事件必须携带 identity;canonicalization 必须在 hash 之前冻结且全链路一致。否则,身份不稳定,统计、聚类、promotion 都会被污染。
其实后面通常会跟着两个坑。第一是粒度问题:span 太粗,会把多个观点揉在一起,引用统计变脏;span 太细,句子级别的微小改动都会导致 hash 变化,聚类碎裂,主线抽取失稳。粒度决定了制度抽象的形态,这是结构层的张力。第二是模型污染问题:一旦模型介入渲染,它天然倾向于“补全”,把证据之间的空白用语义连起来,生成看似完整但未经统计支持的结论。所以在证据宇宙这个方块里,模型绝对不能参与身份生成或 key 推断;模型只能重排、压缩、引用已经存在的证据块,不能生成新的事实块,这就是“可证明引用闭包”(我其实在这里完全没有使用模型)。一旦允许模型扩展事实,整个可审计性就被破坏。
最终你要刻在系统边界上的原则其实只有三句话:身份先于语义;确定性先于可读性;门控先于渲染。只要这三条不动摇,定位漂移会被压缩到最小范围,身份丢失会变成显式错误,而不是隐性腐蚀。
第二个框:引用证据和计数
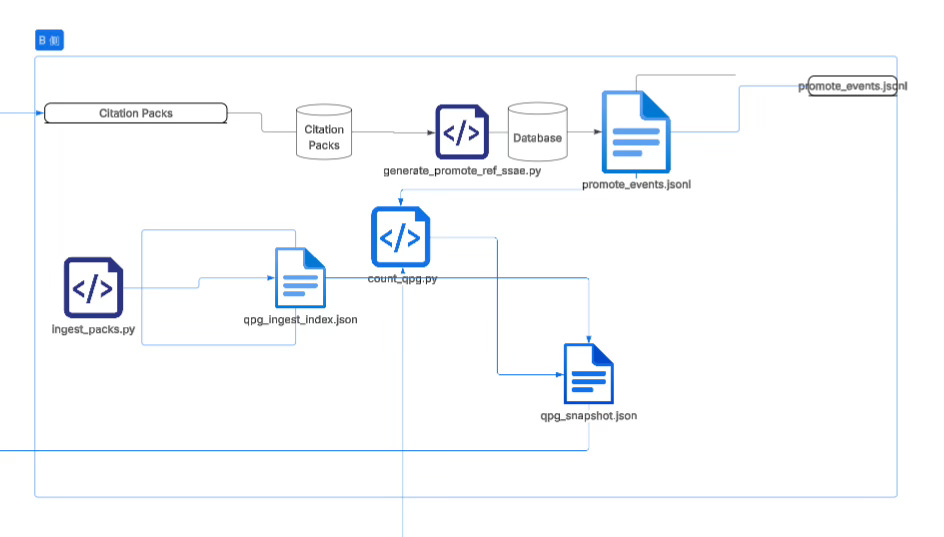
如果你按上一篇的设想,用一个 wrapper 把自己真实开发的项目流水线直接接到这个库上来,那么每天产生的海量 query 记录,最终就要落到一条“可被治理、可被统计、可被晋升”的管道里;而你图里这段所谓 B 侧数据管线,干的就是把“检索行为”从语义检索层抽出来,变成可以进入 promotion 系统的结构化事实:它把 Citation Packs 这种检索回包,转换成两类东西——一类是可计数、可聚类的 B 信号索引,另一类是可回溯、可审计的 Promote 引用事件,并最终汇总成下游提案与渲染要用的 QPG 快照。具体链路非常清晰:ingest_packs.py 负责吃掉 Citation Packs、提取命中键(hit_keys)并在需要时做 TEXTSHA→SSA-E 的适配,产出一个 run 作用域的 ingest 索引,让“你今天引用了什么”成为可统计对象;generate_promote_ref_ssae.py 则把 Citation Packs 里的 locator 做 backref,尽可能还原成稳定的 SSA-E 引用事件,输出 promote events(并兼容 legacy 字段),让“这次引用能否被制度化引用”成为可审计事实;最后 count_qpg.py 读取 ingest 索引(并可结合 core registry 与 promote ledger),对 B 信号做计数、缺失与覆盖分析,产出 qpg_snapshot.json 作为后续聚类、提案生成与 AI 渲染的统一入口。用一句话记:Citation Packs 先被 ingest_packs.py 变成“可计数的行为索引”,再被 generate_promote_ref_ssae.py 变成“可审计的引用事件”,最后由 count_qpg.py 压缩成“可下游消费的 QPG 快照”,从而把你每天真实的检索与引用行为,转化为能够驱动主线抽取与晋升决策的制度级数据流。
这条我直接给你个快照的例子给你看:
"dedup_rules": {
"B_dedup": "(run_id, SSA-E)"
},
"inputs": {
"core_keyset": "_system/artifacts/derived/evidence_registry/core/v1/evidence_core.jsonl",
"core_present": false,
"ingest_index": "_system/artifacts/derived/promote_eval/v0/qpg_ingest_index.json",
"promote_ledger_present": false
},
"items": [
{
"counts": {
"B_count": 6
},
"risk": {
"b_distinct_runs": 6,
"b_sparse": false,
"coverage_core": false
},
"score": {
"primary": 6
},
"sources": {
"B_runs": [
"20260204T021324Z_query_vault_d871c310f7",
"20260204T165509Z_query_vault_2f20fafd71",
"20260204T181147Z_query_vault_cccfa2209c",
"20260204T182015Z_query_vault_61fb5cf34b",
"20260209T195916Z_query_vault_d3f4ea4058",
"20260209T200152Z_query_vault_2002a3ffa1"
],
"caps": {
"B_truncated": false,
"cap": 50
}
},
"ssa_e": {
"doc_id": "SL-2026-01-31-0001-Schema-Version-Is-Identity-Not-Inference",
"span_text_hash": "ac14a502c77fc6194b7af260944cdeda839550cfbc609bdb7fcb028edfc0e5f4"
}
},
一个可审计的统计快照:每个条目就是一颗“候选证据原子”,带着严格的身份(SSA-E)、可复现的行为计数(B_count)、可解释的风险特征(distinct runs / sparse / coverage_core),以及可回放的来源 run_id 列表。模型在这里的角色不该是“推理真相”,而只能是把这份统计事实翻译成合规语言:把“被反复引用的身份实体”组织成 proposal 文档里的 claims/notes/thresholds,而不是从语义里发明新内容。
就你这段快照字段结构而言,它已经非常接近“不可胡诌渲染”的理想输入,因为它把模型能用来胡说的空间压到最小:
dedup_rules.B_dedup = (run_id, SSA-E)明确告诉模型计数口径是什么,避免它把重复引用误当成多证据源;inputs.core_present / promote_ledger_present这类布尔位直接暴露“上下游是否可用”,意味着渲染层必须在文案里显式承认缺失(比如 coverage_core=false 就不能写“已进入 core 覆盖”);items[*].ssa_e给出硬身份(doc_id + span_text_hash),这就是“引用只能指向身份”的约束;counts.B_count+sources.B_runs让“统计你做了什么”完全可回放,模型只能把 6 次、6 个 run 说成 6 次、6 个 run;risk.coverage_core=false这种字段是关键的“禁止推断钉子”,它强迫模型承认:这条虽然高频,但尚未被 core 覆盖(或 core_keyset 未加载),所以它只能被表述为“高频候选”,不能被表述为“已确认为可对齐证据”。
如果你把它视作渲染输入(Model Feed),那么“模型应该被允许输出什么”其实可以被严格限定成三类句子:
事实句:基于字段的直接陈述(例如:该 SSA-E 在 B 侧被引用 6 次,来自 6 个 distinct runs)。
风险句:基于 risk 字段的直接陈述(例如:core coverage 缺失,因此当前仅能作为候选,需补齐 core/context backref)。
动作句:基于系统规则的下一步建议,但必须显式标注为“操作建议/待验证”,且引用触发条件来自字段(例如:若要进入 proposal,需要 core_present=true 或 coverage_core=true 才允许晋升为强 claim)。
反过来,“模型绝对不允许做的事”也可以从这份快照反推出来:任何关于 span 内容的解释、任何“这段话意味着什么”的扩写、任何未在字段中出现的阈值满足性断言(例如把 coverage_core=false 写成“已覆盖”)都应被视为越权。换句话说,你现在这个快照就是典型的 强结构、弱模型:让模型只在结构边界内做语言组织,而把真实身份、计数口径、缺失状态都锁死在输入里。
顺便点一下你这条样例 item 的“制度含义”:它几乎就是一个天然的 proposal seed——B_count=6 且 b_distinct_runs=6表示这不是单次会话的偶然命中,而是跨 run 的反复调用;但 coverage_core=false 又明确告诉你:这条即便高频,也还不能直接晋升为“可对齐的制度证据”,必须先补齐 core/context 覆盖或 backref 完整性,否则渲染出来也只能是“高频候选条目”,不能是“可证据化结论”。
好,还没完,既不完美,也没完。我这是想的美,中间还有大量的小bug没解决。我们先继续往下说,因为下面这个模块就是渲染模块了,要上LLM模型 (GPT-4o-mini)。从快照出来以后,我们进入渲染层:
第三个框:模型渲染
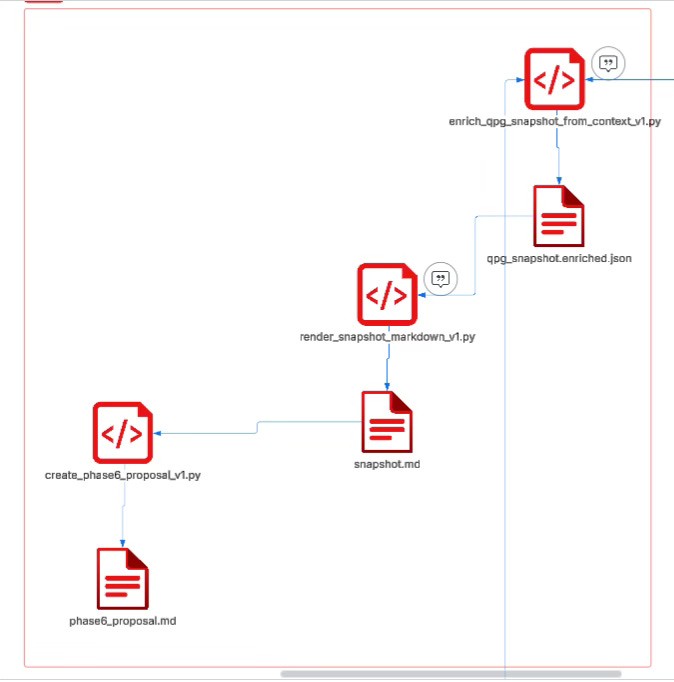
我们说渲染模块,真正的核心问题只有一个:如何在保证“强结构,弱模型”的前提下,让文本既可读、可聚类、可审核,又绝不允许模型胡乱编写或擅自补全。如果模型可以凭语感扩展事实、补齐因果、推断阈值,那么前面所有证据化、计数、门控的努力都会被破坏;但如果完全不用模型,输出又会变成生硬的结构拼接,缺乏人类可读性与治理表达能力。因此,关键不在于“用不用模型”,而在于把模型严格限制在渲染边界之内——它只能组织、压缩、重排已经存在的结构化事实,不能创造任何新的事实单元。
这条下游链路本质上是在做一次逐层压缩:把“可审计的计数快照”转化为“可阅读、可门控、可晋升的治理文本”。首先,enrich_qpg_snapshot_from_context_v1.py 以 (doc_id, span_text_hash) 为唯一硬键,将 qpg_snapshot.json 中的纯计数条目与 context.jsonl 中的定位与 preview 做确定性回填,生成 qpg_snapshot_enriched.json。这一阶段的意义,是把抽象的统计对象变成“可审阅的证据卡”,并显式标注缺失与回溯状态,保证身份与上下文不发生漂移。随后,render_snapshot_markdown_v1.py 将 enriched 快照渲染为面向人类的 snapshot.md,输出排名板、聚类视图与风险提示等阅读结构;在这一阶段,LLM 可以参与语言层面的压缩与措辞优化,但必须严格绑定输入字段,不得引入任何未出现在快照或 context 中的 claim、推断或判断。最后,create_phase6_proposal_v1.py 以渲染产物或结构化快照为真源,生成 Phase6 proposal,将候选条目组织为 claims 与 actions,同时强制所有引用的 join key 只能来自快照中的 SSA-E 或 TEXTSHA,从而把“表达流畅性”与“证据准确性”彻底解耦。
这套机制的目标不是让模型更强,而是让模型更受限。模型负责可读性与表达压缩,结构负责身份、计数、风险与门控边界;模型只能在锁死的证据闭包内写作,不能扩展事实边界。正是在这种“被限制的写作”之下,聚类与可读性得以保留,而胡诌与补全被压制为机制上不可发生的行为。这才是真正意义上的“强结构,弱模型”。
这个中间使用的代码机制和门控,我们暂时先不谈,我给你看最后的生成物:
---
schema_version: promote_qpg.phase6_proposal/v1
run_id: 20260214T_PHASE6_0001
generated_at: 2026-02-14T16:58:53+00:00
source_sha256: d4ba9e75fe1027b699862733cecceb6095ed6c23772c200a7d372b5ca5be4213
bundle_id: BND-UNKNOWN
doc_path: docs/UNKNOWN.md
human_label: UNKNOWN.md
---
# Phase 6 — Proposal (Claims-first)
## Decision Summary
The proposal addresses governance risks related to schema versioning and identity declaration.
## Claims
### C-0001
- kind: `normative`
- threshold_pass: `True`
- support_join_keys: (SL-2026-01-31-0001-Schema-Version-Is-Identity-Not-Inference,ac14a502c77f…)
- text: The `schema_version` is an identity declaration, not something the system may infer from time ordering, trace continuity, file location, or heuristics.
- notes: Supported by evidence with signal strength 6.
### C-0002
- kind: `normative`
- threshold_pass: `True`
- support_join_keys: (04d4fac5b440b37865e7f1a6ae7d49bc480364c96ce2409ec4a06c1ae8799013,9345e730b7b9…)
- text: Enforcing schema_version and identity rules is critical for maintaining system integrity.
- notes: Supported by evidence with signal strength 5.
### C-0003
- kind: `normative`
- threshold_pass: `True`
- support_join_keys: (01c1d8a24c98deb156506116b639b13e8d9cea8eb89b589b1a1243374dbb8abc,2bd5f52203b3…)
- text: Tool results are recorded as standalone facts in the ledger, independent of execution traces.
- notes: Supported by evidence with signal strength 4.
### C-0004
- kind: `normative`
- threshold_pass: `False`
- support_join_keys: (0b52473ae4937859cea3de3ef868b622a9766f0447a307a39145e107808f8f23,1723e33a0cac…)
- text: Releases become replayable and auditable only when inscribed in the ledger.
- notes: Evidence indicates missing context signals, which may affect the reliability of this claim.
## Actions
### A-0001
- kind: `docs_patch_intent`
- target_doc: `docs/UNKNOWN.md`
- support_join_keys: (04d4fac5b440b37865e7f1a6ae7d49bc480364c96ce2409ec4a06c1ae8799013,9345e730b7b9…)
- text: Add clarifications regarding the importance of schema_version and identity rules.
## Appendix
### themes
```json
[
"Governance risks related to schema versioning and identity declaration."
]
ranked_evidence
[
{
"rank": 1,
"join_key_pair": "(SL-2026-01-31-0001-Schema-Version-Is-Identity-Not-Inference,ac14a502c77f…)",
"signal_strength": 6,
"risk_flags": [
"coverage_core"
]
}
]
risk_heatmap
{
"missing_context": {
"count": 5,
"details": [
{
"join_key_pair": "(1e8fe760fab715b983ffc3bce6d18e91eed9096e36c7f96b643d702382048e9f,bb2a267d166b…)",
"signal_strength": 4
}
]
}
}
warnings_readable
"Missing context signals: 5"
从格式与结构层面看,这份 Phase6 的最终生成物已经满足我的最小要求:它以明确的 schema_version/run_id/source_sha256 作为可回放的身份外壳,把提案内容拆分为可机器处理的 Claims/Actions/Appendix 三段,并且每条 claim 都具备可审计字段(kind/threshold_pass/support_join_keys/text/notes),其中 support_join_keys 形成了对证据身份的硬绑定,threshold_pass 将门控结果显式化,而附录又保留了可回溯的主题、证据排名、风险热图与可读 warnings,确保提案既能被人阅读,也能被机器复核。至于中间链路如何富化、如何渲染、如何 gate,这里先不展开;我现在只给你看最终产物,因为它最直接地定义了我们“喂给模型渲染”和“最终进入治理流程”的输入输出形态,也证明这条链路在形式上已经具备可晋升到 docs(宪法层 / IR)的雏形。
下一步,就是把这些反复击中,我在大量的开发中积累的重要经验claims插入docs宪法层。使用一种docs_patch_plan:明确目标文档、锚点位置、标准化插入块、冲突策略与证据来源,由人最终签字确认后再应用。插入位置的准确性必须依赖稳定的锚点协议(显式结构锚点优先,其次标题路径,最后内容哈希兜底),而不是语义推断;插入内容必须是带身份与去重键的标准块,而不是自由文本。这个可能下一个阶段了。
目前这条链路中间仍然存在大量问题,最核心的是:信息在层层转换中不断丢失,最后真正能进入晋升流程的内容只剩下很小一部分。这不是某一个脚本的小 bug,这个就是我上面再说的,结构层面的开放边界问题。
这件事根本不是多开几个窗口、多写几段代码就能解决的。如果边界定义不清晰,没有统一的主键体系和稳定的语义约束能力,你不可能靠“窗口操作”拼出一个真正稳定的系统。问题出在结构层,而不是算力层。向量化之后,搜索命中的字段往往无法稳定定位;任何基于段落编号的 ID 都会随着文本微调而漂移;段落多一个字、少一个字,哈希就改变;字段稍作重排,引用立即失效。你若完全冻结字段、严格哈希化,确实能获得完美的定位能力,但随之而来的问题是:如何聚类?如何泛化?如何把相似却不完全相同的内容归并为一个结构单元?而一旦引入模型对语言进行润色和补全,让文本变得可读、连贯、可传播,你又必须接受模型为了叙事顺畅而自动填补逻辑空隙,这些补全往往没有真实证据来源,语义连贯性上升的同时,证据确定性却在下降。反过来,如果完全不用模型,纯靠硬编码与结构输出,内容可以被验证,却几乎不可读、不可传播,也难以形成认知影响。
因此,这根本不是在解一个算法题,而是在同时约束三种天然互相拉扯的能力:可定位性、可聚类性与可读性。定位需要冻结——哈希、稳定 ID、不可变锚点;优点是可验证、可审计,代价是极度脆弱,稍有变化就失效。聚类需要相似——可变、可泛化、可合并;优点是能发现结构吸引子,代价是边界模糊、主键漂移。可读性需要语言——模型渲染、叙述组织;优点是可理解、可传播,代价是引入幻觉与无根据补全。任何一项被拉满,另外两项都会坍塌:强调哈希定位,聚类能力下降、语言僵化;强调相似聚类,定位失真、锚点不稳;强调可读性,证据被稀释、主键被污染。
所以这不是“技术不够”的问题,而是一个结构三体问题。真正需要设计的不是某个更聪明的算法,而是一种明确分层的机制:底层冻结(Registry / SSA-E 主键层),中层可变(聚类与相似空间),表层可读(模型渲染与表达层)。三层必须清晰分离,职责边界明确,不能混用、不能跨层偷渡。否则系统会在开放边界中持续漂移,最终只剩下极少数“安全可落盘”的残片,而整体结构无法稳定成长。
灵魂提问与总结
直接向量化 + 模型(典型 RAG)当然是完全可行的。我从来没有否认这一点。它高效、实用、工程成本低,如果目标只是做一个问答系统,它几乎是性价比最高的选择。问题不在“行不行”,而在“你想要什么”。
我个人不想从一个说话机跳到另一个说话机。对我来说,如果系统的核心只是“输入问题 → 输出语言”,那意义不大。那只是换了一种更高级的表达外包方式,而不是结构能力的增长。所以我才走这条更重、更慢、更折磨人的路线。但我从未说这条路线一定比典型 RAG 更好。它不是更好,它只是更符合我当前的目标和偏好。
如果你的目标仅仅是构建一个问答系统,或者一个知识助手,那么真的不要走我这条路。它的复杂度、维护成本、结构设计负担,都远远超出必要。值不回票价。
这本质上是一个个人选择的问题,是 taste 的问题。你选择优化什么:速度、可用性、可审计性、可晋升性、结构稳定性?不同的目标,会自然导向不同的架构。
至于更深一层的问题——个人的 taste 是否可以在这个知识库的基石上被系统性解决?是否可以通过结构化主键、证据链、晋升机制,慢慢收敛成一种稳定的决策方向?老实说,我现在还没有答案。我在搭这个底座,是希望它至少提供一种可能:让 taste 不再只是模糊的直觉,而是能被回放、被观察、被约束。但它是否真的能承载那种“方向性压缩”,目前我还不能保证。
结构就是硬编码。我的选择是个人接口化、场景化。人有多个不同的面相,就是把人包成skill.对于不同的场景,调用不同的结构。提升对外可适配性和对内的内循环稳定性。就是挂上外脑,把人变成多个操作系统。我认为人的原生是相当混沌的,如果把一个人理清楚了,一个人就被准确的切分成了不同的subagent。而人这个定义,只是用来处理边界情况的。哈哈,这就是人。