
Memory is schedulable structure; taste is the gravitational field that continuously biases the future decision space.
记忆是可调度的结构, 品位是未来决策空间持续施加偏置的引力场:程序员需要有自己的外置库,否则无法保持自己的决策延续性——也甚至无法维护自己开发的代码。(中文在后面)

Since the last time I updated my article, my development work has gone through countless rounds of trial and error. Numerous exploratory chains were opened, and just as many branches were pruned away. Many paths that initially looked extremely promising eventually turned out to be dead ends; many directions that seemed insignificant at first gradually revealed themselves to be far more viable. In short, it has been a continuous process of trying, dismantling, and recomposing. Eventually, I reached a stage where I feel it is worthwhile to pause and write something to share.
Let me begin by revisiting my original motivation. I believe many programmers today are experiencing the same shift that I am. I’ve discussed an important observation with several friends (perhaps by now you no longer find this surprising): we are increasingly convinced that the future will no longer involve carefully reading code in detail. No one will continue to write code line by line in the traditional sense. Of course, the degree varies from person to person. In my own case, I now almost never read the first version of code generated by AI. What I do read is the diff. Because when reviewing diffs, I often encounter very interesting situations. Sometimes, in order to satisfy the requirements I gave, the AI produces code that makes me laugh and cry at the same time.
For example, I once asked the AI to implement a structured rendering approach so that the system could maintain strong generality and extensibility in the future. The solution it produced was to enumerate a long list of related keywords. This technically works for the current problem, but structurally speaking it is almost an active destruction of future generality. Code like this is easy to recognize: it exists to pass the current task, not to support the long-term evolution of the system.
Because of experiences like this, I increasingly believe that the real problem with AI-generated code has never been the code itself. Code is merely the surface. The real question is what decisions humans are making, and whether those decisions can continue over time.
This is precisely why so many programmers have recently begun discussing one topic: memory. Almost every AI coding framework eventually circles back to this issue. But after asking many people about it, I discovered something strange: almost no one can clearly explain what memory actually is.
Is memory the content written in books? Notes stored in Notion or Obsidian? Information saved in a database? Vector retrieval inside an LLM? Clearly none of these capture the essence. If the problem were that simple, then Notion or Obsidian combined with AI plugins would have solved it long ago. But they haven’t. People are still repeating the same work again and again.
Gradually, I began to feel that the problem we are trying to solve is not really “memory,” at least not memory in the traditional sense of the human brain. If I had to describe it in the simplest possible sentence, the real problem we want to solve is the continuity of decision-making.
The human brain cannot maintain decision continuity across extremely complex scenarios and long periods of work. This is the root cause of much of our suffering.
Let me describe several “programmer hells” that I personally experience today—and that I believe you, sitting in front of the screen, have either already experienced or at least begun to sense.
1) The Hell of Project Restart
No matter how much code you have written, how many projects you have built, or how many documents you have produced, every time you start a new project you often feel a very strong sensation: everything is starting from scratch again.
At the same time, you also feel that things should not actually be this way. Because you can clearly sense that many projects share the same underlying structures. Many projects are essentially the same system wearing a different costume.
Even when they appear completely unrelated on the surface—an education app, a knowledge system, a web service, an AI tool—at the structural level they often share highly similar patterns: identity management, authorization, data models, state management, event systems, evolutionary paths.
The problem is that the human brain is not very good at extracting these structures and recombining them. So every “new project” ends up feeling like entering a new parallel universe. You repeatedly encounter familiar things, familiar bugs, familiar architectures, even familiar sensations when fixing bugs.
Every time a project begins, it feels as if you have returned to the starting point. This is the hell of project restart.
2) The Hell of Micro-Decisions
Even though AI can now write code extremely quickly, a window is not omnipotent. A real system is never completed with a single prompt.
A real system resembles a stack of interconnected seesaws. Each pivot point in those seesaws is actually a decision. Where should this module live? How should this API be designed? Is this data structure extensible? Will this logic affect the future evolution of the system?
Each of these decisions seems small, but each of them influences the entire system.
In modern development environments you often play multiple roles simultaneously—frontend developer, backend developer, architect, algorithm engineer, product manager. As a result, all of these micro-decisions accumulate on a single person.
Each decision individually appears trivial, but the total number of them is astronomical. Your time and cognitive energy are constantly consumed by these micro-decisions. The more complex the project becomes, the more pronounced this feeling becomes.
Eventually you realize that what truly slows you down is not writing code—it is the endless stream of tiny decisions.
This is the hell of micro-decisions.
3) The Hell of Technical Debt
This one is more familiar: the classic “spaghetti code.” But in my own framework there is another, more subtle form of technical debt—non-evolvable technical debt.
When building a system, you often cannot plan very far ahead. Time is limited, information is incomplete, and the number of decisions is overwhelming. So many designs are merely temporary solutions that work for the moment.
The problem appears when the system must evolve. Suddenly you discover that the technical debt has accumulated into a mountain. Many places become too risky to modify; changing one component triggers unexpected consequences elsewhere.
Again, the seesaw analogy applies: when you push down one board, you have no idea how many other boards will be lifted.
Eventually you arrive at a very familiar decision:
“Forget it. Let’s restart.”
And thus we return once again to the hell of project restart.
If you examine these three hells carefully, you will notice that they are actually different manifestations of the same problem. Project restart, micro-decisions, and technical debt all originate from a single underlying issue:
decisions cannot remain continuous.
Each time you start again, you are making the same decisions. Each time you are rethinking the same problems. Each time you are repeating the same mistakes.
Now if we connect this observation with one of the most popular words in the programming community recently—Taste—things become very interesting.
Many people say that what distinguishes a truly great engineer is not coding skill but taste. But what exactly is taste?
I increasingly believe that taste is the compression of decision continuity.
A person with taste does not re-evaluate everything from scratch each time. Many of their decisions have already been structured in their mind. So when a new problem appears, they are not asking “what should I do?” They are calling upon how they have solved similar problems before.
If we phrase the problem even more directly:
if AI can write code, then the real problem of the future is not how to write code. The real problem is how to maintain continuity in decision-making.
Many people claim they are solving the memory problem, but I think that is only a surface description. The deeper problem is how to preserve the structure of human decisions so that they can be invoked again in the future.
Everything I have been experimenting with recently revolves around one question:
How can we prevent decisions from starting from zero again?
Fast-forward ten thousand steps. Let me first tell you one thing I have already managed to achieve.
At this point, I can no longer write articles by recording my thinking process in real time. Instead, I have to wait until I feel that the accumulated material has reached a meaningful threshold, and then share the final realization of a particular stage.
The reason is simple: the volume of information processing is now enormous. Every day is filled with cycles of trial, reconstruction, collapse, and retry. If I tried to document every intermediate state, I would never get anything else done.
So what I can show you now is not the process, but a result that already works:
Starting from a single intention, with a single click (literally pressing a button—any intermediate command-line prompts such as Yes/No/Continue or copy-paste actions do not add meaningful information and can be ignored), relying only on code, model rendering and invocation, together with the knowledge base that I have designed and organized, and only by calling knowledge that already exists in that library, the system can generate in one pass a complete decision document—one that can immediately guide reliable code and system architecture.
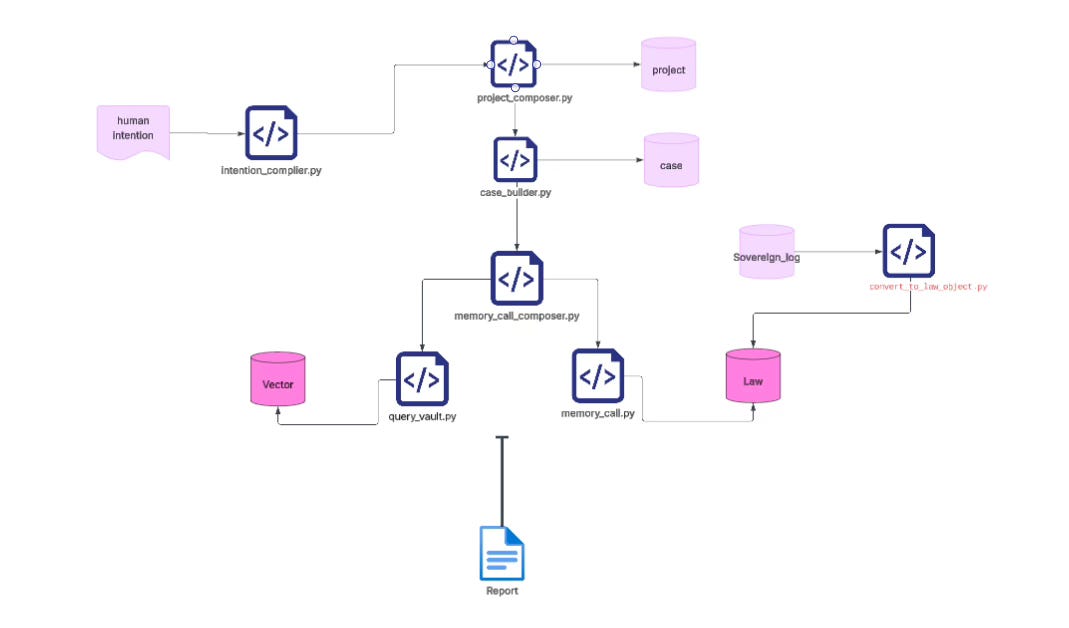
1) First, this approach eliminates the endless proliferation of windows.
Many people have probably experienced this. When you are working on a project, the issue might appear to be a small architectural question—such as which framework to choose, how a module should be decomposed, or whether a certain data structure might affect future evolution. Yet these questions often require a bit of global reasoning.
So you begin opening windows: one window discussing architecture, another discussing the database, another discussing APIs, another discussing deployment, and then yet another window to clarify some additional detail. By the time you finally make progress on one question, the earlier discussions have already fallen out of the context window. So you open another window and repeat the process.
Eventually you start to feel something strange: it seems as if you are spinning in an ocean of symbols. You look busy, but in reality you are circling around the same small loop again and again. Of course this is not surprising—the context window is limited by definition.
This made me realize that we must find a different approach: for a given intention, generate a complete, high-density decision document in a single pass. That document should include the architecture, constraints, execution paths, and key decisions, all grounded in the best judgment available within your current knowledge system.
Once such a document exists, you can simply hand it to the AI. It then operates with a full decision context, instead of forcing you to debate endlessly across dozens of windows.
2) But the real difficulty is not generating the document—it is whether you can trust it.
You must trust it to a certain degree in order to proceed with confidence. Otherwise you will inevitably fall back into the familiar habit of opening yet another window to ask the same question again.
This is actually very difficult, because the foundation of that trust does not lie in the model—it lies in your knowledge base.
The logic is simple: garbage in, garbage out.
If your knowledge base itself is chaotic, fragmented, or untested, then whatever you generate from it will simply be a faster and more systematic form of chaos.
Over the past few months, I therefore spent a great deal of time studying something that initially seemed unrelated to programming: the Anglo-American legal system. Gradually I realized that this legal tradition represents one of the most successful structures humans have developed for organizing complex social rules. It is capable of maintaining order, legal coherence, and collective intent within an extremely complicated society.
More importantly, it does not rely on a perfectly designed rule system. Instead, it emerges through long-term accumulation, case law, and iterative refinement of rules.
Because of this, when I designed the structure of my own knowledge base, I borrowed heavily from the structural logic of the common law system. I will discuss this in more detail in future articles.
3) Finally, there is a crucial question: how do we understand iteration and upgrade?
Let us return again to the legal system.
I had previously hinted at this idea, but only after studying it more deeply did I fully appreciate an important fact: any rule that is written down cannot possibly be perfect.
The moment you try to write rules, you realize that many ideals people unconsciously pursue—words like perfect, error-free, absolutely clean, no redundancy, unchanging—are simply impossible. Once a rule exists, it inevitably exists within change.
Therefore, any truly functional rule system must fundamentally be an open information system. It must allow new information to continuously enter, and it must contain a clear pipeline through which that information can be iterated and upgraded.
In the future I will frequently use one word to describe this process: promotion.
In other words, a rule you write down does not automatically become a rule. Only when it is repeatedly invoked in real projects, continuously tested in practice, and proven useful over time does it gradually settle and become a true rule.
Human law itself developed in exactly this way. It was not designed by a single person; it emerged from countless iterations of practice.
Any rule that has not undergone this process of refinement almost always leads to the same conclusion, which I have encountered many times:
Wishful thinking.
The ideal looks beautiful—but reality is far less accommodating.
Memory is schedulable structure; taste is the gravitational field that continuously biases the future decision space.
This is the reality we now face every day in the age of AI.
And for that, we should thank the extraordinary power of modern LLMs.
When you begin writing down the knowledge you truly use in daily work, that knowledge inevitably has to go through a process of refinement. It cannot remain in the form of raw notes from individual projects, scattered code snippets, or fragmented reflections. Instead, it needs to be compressed into rules that can be reused across projects.
Take a very simple example: a statement like “Ensure system life run_id is contained within a single OS process lifetime.” This rule did not appear because I sat down one day and deliberately wrote it. Rather, it emerged gradually from experience accumulated across many different projects. It existed implicitly inside project retrospectives, development journals, and scattered notes. Over time it became a kind of shared internal consensus.
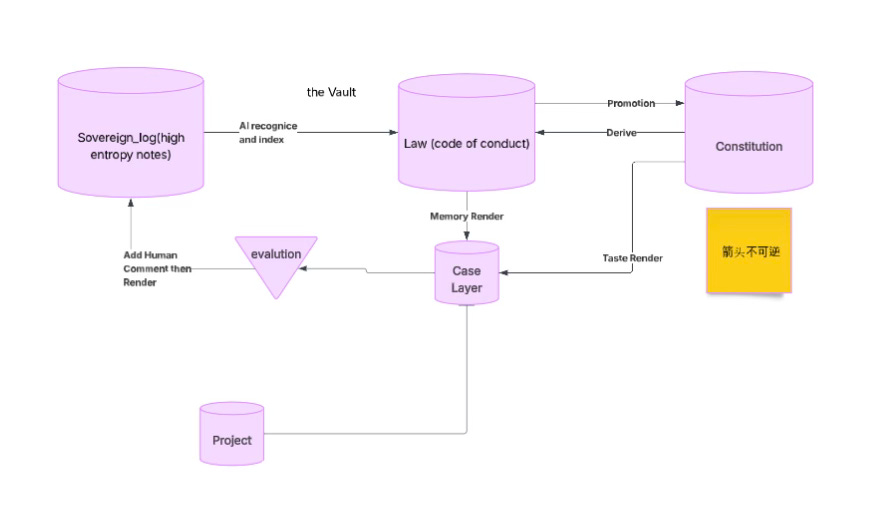
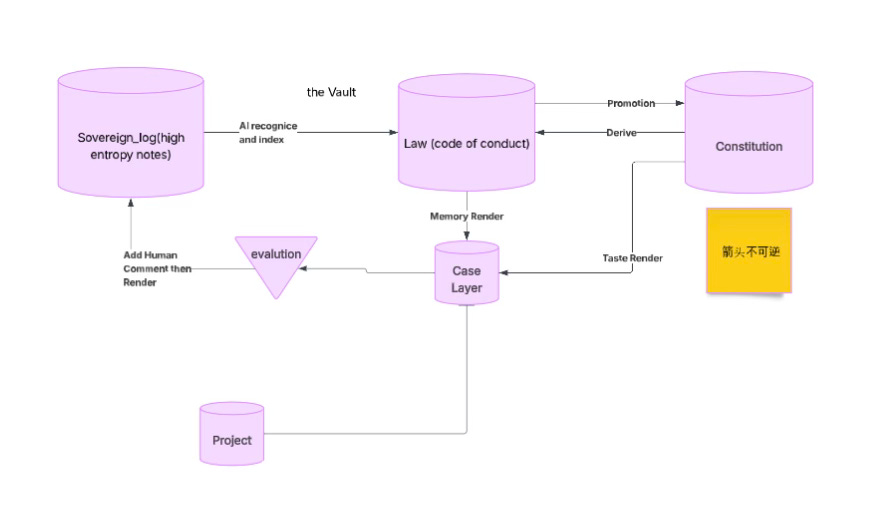
In the past, extracting such knowledge from a large pile of notes was extremely labor-intensive. But now this extraction work can be handled almost entirely by an LLM. For that reason, a large portion of my notes—notes that have already been carefully filtered—were first placed in a space I called the Sovereign Log. The name itself was chosen somewhat casually.
After the content goes through a process of refinement and selection, the original project context is stripped away. The specific code implementations are removed. What remains are the rules themselves and the structural insights that actually carry value. These are then marked and categorized one by one as Law.
In other words, the project-specific information is hidden, the concrete implementation is removed, but the skeleton of knowledge is preserved.
This step is actually a task where LLMs and deterministic code collaborate extremely well: the LLM handles understanding and extraction, while code handles structuring and archival. I will share the specific code later, and this is a part of the system that I strongly recommend others adopt.
Next, as you continue developing across various projects—whether personal home projects, team projects, client projects, or work-related systems—you will repeatedly invoke this Law library. Once these rules enter a specific project, they regain context. At that moment, they become a Case.
This is very similar to how case law works in the Anglo-American legal system. The law itself exists as a body of rules, but what truly matters is how those rules are applied, interpreted, and adjudicated within real-world situations.
This process—where rules meet reality—is something I also implemented through a combination of code and LLMs. It is actually one of the more difficult parts of the entire system, because it involves substantial workflow control and structural constraints. Only recently have I managed to bring it to a state that is stable enough for my own daily use.
Once these Cases run inside real projects, they generate feedback:
Is the rule actually useful? Does it operate smoothly in practice? Where does it need adjustment?
That feedback is then fed back into the system, entering the next round of consolidation and refinement. Over time, this forms a continuously cycling information pipeline.
In this description I am skipping over tens of thousands of lines of code and hundreds of thousands of words of data-structure design. But the core idea can be summarized quite simply:
Knowledge is distilled from logs into Laws, invoked in projects as Cases, and then returned to the system through real-world feedback to continue evolving.
Let me show you a very concrete example.
Recently I have been working on something at home: a comprehensive upgrade of my household network server, all connected devices, and various IoT applications. This project is entirely personal, so I will likely use it as an ongoing example in future discussions. Because it is my own project, I can freely choose to share it.
The goal is simple: you want a system that does not plant hidden landmines for the future, while also maintaining high standards of quality, reliability, and long-term maintainability.
In the age of AI, I increasingly believe that the starting point of a project should be Intention, rather than “what code I want to write.”
Let’s look at a very simple example: how a clear intention can eliminate the need to juggle dozens of windows—arguing back and forth, asking scattered questions, and constantly re-injecting missing context.
What is even more interesting is that once this intention is processed by my system, the entire process—from decision-making to architecture, to code generation, to the first working test and initial deployment—took only a few hours.
In the past, that would have been almost unimaginable.
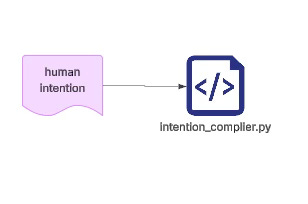
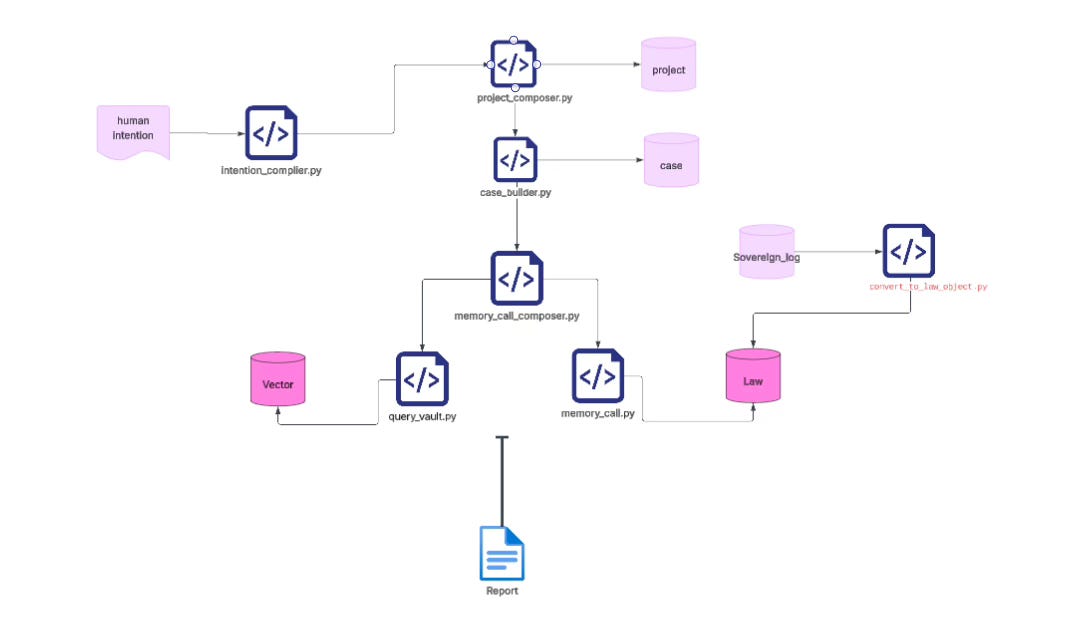
python3 tools/intention_compiler.py \\
--text "I intend to configure one of my Mac mini machines to operate as the primary home control plane for my family’s digital infrastructure.This Mac mini will function as a local server that hosts family services, manages identities, and coordinates applications running within the home network.The system will serve as the central node of the home computing environment, providing a stable runtime for family applications, content libraries, and automation tasks.The Mac mini must run continuously and maintain reliable connectivity with the home router." \\
--max-questions 4 \\
--max-rounds 3 \\
--temperature 0.2 \\
--preview
The first step that needs to run is an intention compression stage. The meaning of this step is actually quite simple: we do not start from asking questions, nor from issuing commands, because those things are merely derivative forms of intention. The real starting point should be the intention itself.
Across many information pipelines, I increasingly feel that intention should be the true entry point of a system. Explaining this fully would probably take several days, but from my own experience the idea is actually very intuitive. Human intention is the most fundamental reason behind any action we take. The ways we normally interact with systems—such as asking questions (typical of the search-engine era) or issuing commands (which became common after LLMs allowed us to generate code through natural language)—are actually adaptations to tools.
In other words, in order to realize our intentions, we are constrained by the tools we use, and therefore we must translate our original intentions into questions or commands. This process feels natural, but in reality it is a constant act of translation. And wherever human translation exists, information loss and ambiguity inevitably follow. So instead of endlessly patching those deviations afterward, it is better to begin directly from the intention itself.
After my entire set of code and processes finishes running (almost everything is fully automated), I actually do almost nothing manually. Aside from answering a few small questions that the LLM itself generates during the process, there is no additional intervention—no reopening new windows for discussion, no manually assembling prompts. The system simply performs a memory call to retrieve relevant knowledge from my knowledge base, passes that through model rendering, and then directly produces the report you saw earlier.
From there, I immediately start writing code and launching the project based on that report. Yes—that directly. Essentially, it is one-click generation. In my view, this is the correct way to work. By contrast, the method of endlessly arguing across dozens of windows—pulling threads in different directions, patching context repeatedly—is actually the wrong approach.
Later I will explain the entire underlying mechanism in detail. More importantly, I trust this direction completely, because fundamentally it is calling my own knowledge base. Many of the core rules and structures inside it were written by me in the first place. In other words, this is not handing decision-making over to the model. Instead, it allows the model to execute a decision system that I have already distilled.
And this is not limited to a single report. The token cost of making such calls is extremely low; I can generate as many as I want. The key point is that it delivers more than a 10× improvement in efficiency, and that improvement compounds over time. Because every time a report is used in practice, the knowledge and code that emerge afterward are fed back into the information pipeline again.
Once the report is generated, the actual work moves quickly. Within just a few hours (and during that time I also generated several additional reports from other angles to further complete the project), the core work was already finished. At that point, building out the project on top of that foundation becomes much faster.
# RISK RESOLUTION — Isolation / Traceability / “Telemetry Never Becomes Truth” for an Online-Only Web App
## 0) Conclusion (One Sentence)
**Define “child learning history” as an append-only Event Ledger routed by child scope; define “memory/progress” as Derivation Views that can be reconstructed from the Ledger; define “telemetry/logs” as Ephemeral Telemetry that is discarded by default. The three must be strictly isolated, and any promotion across boundaries must be explicit, auditable, and replayable.**
---
## 1) Scope as a First-Class Citizen: Hard Boundary for Per-Child Isolation
### 1.1 Scope Key (Required on Every Write)
Every write operation (whether an event, asset, derived view, or uploaded file metadata) must include:
* `project_id`
* `child_id`
* `session_id`
* `actor` (`child` / `parent_admin` / `system`)
* `device_id` (optional but recommended)
* `request_id` (for idempotency)
> **Rule: Any write missing a scope key must be rejected** (HTTP 400/403). There is **no such thing as a “default child.”**
---
### 1.2 Storage Routing
Disk layout and indexing must follow a unified routing rule:
* **Physical path**:
`/data/{project_id}/{child_id}/...`
* **Logical index**:
`(project_id, child_id, kind, ts, event_id)`
Shared write locations are **forbidden**.
For example:
* `/data/shared` may only contain a **public content library**
* All assets in `/data/shared` must be **read-only imports created by parent/admin**
This directly implements the rule:
**All writes must be scope-routed by `(project_id, child_id, session_id)`.**
---
## 2) Append-Only Event Ledger: The Only Source of Truth
### 2.1 Status of the Ledger
* **Ledger = Canonical History (single source of truth)**
Anything like:
* progress
* statistics
* mastery levels
* next-question recommendations
**must never be written as ground truth.**
They must exist only as **derived views** (see Section 3).
---
### 2.2 Minimum Event Schema (Recommended)
Every learning / interaction / scoring / correction event must include:
* `event_id`
(content hash or UUID — content-hash preferred for replayability)
* `ts`
(event timestamp)
* `scope`
(`project_id`, `child_id`, `session_id`)
* `actor`
(who triggered the event)
* `event_type`
(finite enum such as
`attempt`, `answer`, `hint`, `reward`, `content_view`, `parent_override`)
* `payload`
(event content)
* `prev_event_ref` *(optional)*
chain reference for stronger replay / tamper-evidence
* `schema_version`
---
### 2.3 Idempotency: Duplicate Submission is the Default State
You explicitly defined the system as:
**online-only**, where network failure, retries, and partial writes are normal.
Therefore:
* the client **must attach `request_id`** to every submission
* the server deduplicates by `(child_id, request_id)`
* duplicate events are allowed to arrive multiple times but **must only be recorded once**
And importantly:
**The client must never advance local progress based on “whether a response was received.”**
This corresponds directly to your law about **implicit state advancement control failure**.
---
## 3) Derivation Views: Progress and Memory are Reconstructable Artifacts
### 3.1 Core Definitions
* `raw_event`
append-only factual record
* `derived_view`
a state snapshot computed from raw events via a deterministic reducer
* `memory`
a **version-frozen artifact produced through explicit promotion**, written into the `law/objects` or vault layer
Memory must **never emerge automatically from raw events.**
---
### 3.2 Reducers Must Be Auditable Functions
Every reducer must include:
* `reducer_id`
* `reducer_version`
Every derived view must record:
* `input_range`
(which events were used)
* `reducer_id@version`
* `output_hash`
Reducers may be upgraded and views rebuilt, but:
**the results must remain diffable and auditable.**
This enables exactly what you want:
**replayable history + rebuildable derived views.**
---
## 4) Telemetry Hygiene: Telemetry is Untrusted and Disposable
### 4.1 Three Hard Rules
Directly implementing your principle:
**“Telemetry must never become truth by accident.”**
1. **Telemetry is ephemeral**
Short TTL only (e.g., 7 days) for debugging and operations.
2. **Telemetry never participates in derivations**
Reducers read only from the ledger.
3. **Cross-boundary promotion must be explicit**
If telemetry is promoted to evidence or knowledge, it must pass through a manual action:
`PromoteTelemetryToEvidence`
producing an auditable artifact with justification and signature.
---
### 4.2 Git / Repository Hygiene
Consistent with your laws:
* `_system` may write automatically
* **runtime outputs must never be committed**
Writes to:
* `sovereign_log/`
* `law/objects`
must always be **human-triggered or explicitly approved promotion events**.
---
## 5) Authorization: Hard Capability Separation Between Child and Parent
### 5.1 Two Capability Domains
**Child Runtime**
Allowed:
* read kid content
* write own ledger events
* read own derived views
Forbidden:
* import content
* modify rules
* query other children
* export data
* promote memory
---
**Parent/Admin**
Allowed:
* import content libraries
* configure rules
* view audits
* export data
* perform explicit promotion
* system maintenance
---
### 5.2 Minimal Session Implementation
Under the constraints:
* **local network only**
* **no external internet access**
A minimal system is sufficient:
* iPad child mode → short-lived session token bound to `child_id`
* parent/admin interface → separate authentication (Mac mini local access)
**A token must never carry both child and admin capabilities.**
This prevents **capability bleed**.
---
## 6) Mac mini Control Plane: Engineering Commitments
Your Risk Resolution (CASE-11AF425603) assumes:
* Mac mini is always running
* no external remote access
* Wi-Fi first, wired if needed
* scheduled backups and maintenance
Engineering commitments therefore include:
**Single-node first**
* one Mac mini acts as both **app server and canonical store**
**Backup is policy, not optional**
At minimum:
* daily incremental backup of ledger + assets + configs
* weekly full snapshot (external disk / second mini / NAS)
**Maintenance windows are explicit**
Updates and migrations must be logged in an **operations log** to prevent silent drift.
---
## 7) Minimal Implementation Checklist
Before writing application code, the following **seven structural rules must exist first**:
1. **Define ScopeKey enforcement**
`(project_id, child_id, session_id, actor, request_id)` required on writes.
2. **Define Ledger Event Schema v1**
finite `event_type`, append-only, idempotent.
3. **Implement Idempotency**
dedup index on `(child_id, request_id)`.
4. **Implement Reducers**
ledger → progress view with reducer version tracking.
5. **Implement Telemetry TTL**
logs stored separately with automatic expiration.
6. **Implement Promotion Gate**
runtime → durable knowledge must pass explicit promotion.
7. **Implement Capability Separation**
child tokens and admin tokens must be strictly isolated.
Human Intentions Are Inherently Vague: Intentions Are Not Extracted — They Are Compiled
Human intention is not a problem of missing parameters; it is a problem of structure that has not yet taken shape.
First, you must use an LLM.
Because a raw intention is not a fully formed specification. It is usually a mixture: goals, emotions, vague boundaries, unnamed constraints, default assumptions, latent risks, and even internal contradictions are all entangled in a single sentence. Pure rules or simple textual templates may extract fragments of this information, but they cannot reliably unfold the latent structure embedded within an intention.
Second, it must ultimately land in a schema.
Because without entering a structured representation, every downstream component—memory calls, case classification, composers, schedulers, and ledgers—loses its prerequisite for being schedulable.
Enough theory. Let me show you directly. I will walk through the command line and the code at the same time. As you watch the command-line output, you will notice that a large portion of the content is automatically expanded, extracted, and completed by the LLM itself.
=== ROUND OUTPUT ===
[run_id] 20260305T145405Z__64411957 [round] 1
{
"intent": {
"project_name": "",
"one_liner": "",
"success_metrics": [
"Mac mini runs 24/7 without unexpected downtime for at least 30 days.",
"All designated family services and applications are accessible and functional within the home network.",
"Identity management system reliably authenticates and authorizes family members.",
"Automation tasks execute as scheduled without failure.",
"Content libraries are accessible and synchronized across family devices."
],
"non_goals": [
"Hosting services accessible from outside the home network (no external remote access).",
"Replacing existing internet service or router functionality.",
"Managing devices outside the home network."
],
"time_horizon": "weeks",
"budget_band": "medium"
},
"description": "Set up a Mac mini to act as a local server hosting family services, managing identities, coordinating home network applications, and serving as the central node for home computing, content libraries, and automation tasks. The Mac mini must run continuously and maintain reliable connectivity with the home router.",
"scope": {
"hardware": "One Mac mini machine within the home network.",
"network": "Local home network connectivity only.",
"services": "Family services, identity management, application coordination, content libraries, automation tasks.",
"uptime": "Continuous operation with stable connectivity to home router.",
"devices": [],
"platforms": [],
"infra": [],
"users": []
},
"constraints": {
"hard": [],
"soft": []
},
"policies": [
"access_to_the_mac_mini_and_hosted_services_restricted_to_family_members",
"regular_backups_of_critical_data_and_configurations",
"updates_and_maintenance_scheduled_to_minimize_downtime"
],
"assumptions": [
{
"assumption": "The Mac mini hardware is already owned and available for use.",
"status": "unconfirmed",
"ask": "Do you already have the Mac mini hardware available, or will acquiring it be part of this project?",
"impact": "High"
},
{
"assumption": "Family services and applications to be hoste
...
The most important part of this code is that, from the very beginning, it explicitly acknowledges that the first round of input is not truth—it is only a seed. seed_text is not the final spec, not a finalized requirement document, and not a reliable object that can directly enter the implementation layer. It is merely a high-entropy starting point: a subjective input of intention that has not yet fully collapsed into structure. This judgment is crucial, because one of the most fatal problems in many systems is precisely that they mistake the user’s first sentence for the truth of the requirement, and immediately begin writing solutions, code, and architecture recommendations as if the input had already been structured. I explicitly treat the first expression as an object to be compiled, not an object to be executed.
At the same time, the code institutionalizes guessing, rather than allowing guessing to happen silently. The system prompt in the code explicitly requires: every guess MUST be recorded in intention_spec.assumptions[] with status='unconfirmed'and an ask question. This means the LLM is allowed to participate in expanding the intention, but it is not allowed to disguise expansion as fact. The system permits inference, but requires every inference to leave a structural trace and enter a later confirmation chain.
As a result, the entire intention space is clearly divided into several layers: what has been directly provided, what has been inferred, what remains unconfirmed assumptions, and what must continue as open questions. This is not ordinary information organization. It is a mode of intention compilation with built-in cognitive hygiene and governance constraints.
More importantly, this is not a one-shot parse. It is a process of multi-round recursive convergence, and that is the part that comes closest to the reality of human intention. Human intentions are rarely fully expressible in one pass—not because people lack expressive ability, but because boundaries, goals, constraints, non-goals, and success criteria usually only emerge gradually through questioning and feedback. That is why the output is naturally designed to evolve by round, and why the command line can also enforce a maximum number of rounds. In real usage, I usually stop proactively when the LLM’s questions begin to repeat and the question space starts to dry up, because that usually means the current intention has reached a point of local convergence.
By the end, this compilation process does not merely produce a vague summary. It directly generates a case ID and determines which enumerable direction the intention belongs to. My intention directions are not floating infinitely in ambiguity; they can be classified through protocol. For example, this particular intention would be classified as Risk Resolution. And this directional classification is not decided by a purely automatic black box. It can be jointly confirmed by the human and the LLM: the LLM provides structured candidates and confidence levels, while the human performs final confirmation when needed.
So what the whole system is doing is no longer simply “explaining a sentence.” It is compiling a high-entropy intention, round by round, into a structured object that carries a case identity, a directional classification, a list of unresolved questions, and the prerequisites for downstream routing.
The code itself is actually quite simple. If you take this paragraph of mine together with my example and give it directly to an AI, it can immediately generate a working piece of intention-compilation code.
=== ROUND OUTPUT ===
[run_id] 20260305T145405Z__64411957 [round] 2
{
"intent": {
"project_name": "Home Mac Mini Control Plane Setup",
"one_liner": "Configure a Mac mini as the primary local server for family services, identity management, and home automation within the home network.",
"success_metrics": [
"Mac mini runs 24/7 without unexpected downtime for at least 30 days.",
"All designated family services and applications (children's education, home mail/document scanning and AI reading, home inventory management, home calendar management) are accessible and functional within the home network.",
"Identity management system reliably authenticates and authorizes family members.",
"Automation tasks execute as scheduled without failure.",
"Content libraries are accessible and synchronized across family devices.",
"Mac mini maintains stable connectivity over Wi-Fi with the home router."
],
"non_goals": [
"Hosting services accessible from outside the home network (no external remote access).",
"Replacing existing internet service or router functionality.",
"Managing devices outside the home network.",
"Wired network connectivity setup (currently relying on Wi-Fi)."
],
"time_horizon": "weeks",
"budget_band": "medium"
},
"description": "Set up a Mac mini (2-3 units available) to act as a local server hosting family services including children's education, home mail/document scanning with AI reading, home inventory management, and calendar management. It will manage identities and coordinate home network applications, serving as the central node for home computing, content libraries, and automation tasks. The Mac mini must run continuously and maintain reliable Wi-Fi connectivity with the home router. No external remote access is planned at this time.",
"scope": {
"hardware": "2-3 Mac mini machines already acquired, one to be configured as primary server.",
"network": "Local home network connectivity only, currently over Wi-Fi.",
"services": [
"Children's education applications",
"Home mail/document scanning and AI reading",
"Home inventory management",
"Home calendar management",
"Identity mana
...
=== QUESTIONS ===
[P0] Q-1: Are you open to using wired Ethernet connectivity if Wi-Fi proves unreliable for continuous operation?
Answer (empty to skip): Let's try hard to make Wi-Fi work first.
[P1] Q-2: Do you have existing backup solutions or preferences for backing up the Mac mini and its data?
Answer (empty to skip): No existing solutions but openned for options.
Continue to next round? [Y/n]: n
[skip] user stopped; partial artifacts preserved.
[confirm] Case type requires human confirmation.
Primary: Risk Resolution
Secondary candidates: Architecture Decision, Exception Handling, Intent Clarification
Confirm case type (enter to keep pending): Risk Resolution
/Users/sovereign_knowledge_lab/_system/calls/intention_compiler/20260305T145405Z__64411957/FINAL/intention_for_composer.json
Once you are building your own knowledge base, you must fix the identity structure: this context has to be preserved over the long term
The core of the next stage is not to keep piling more material into the knowledge base, but to first lock down the clear identity structure that every pipeline must attach to.
As long as you use LLMs over time, one thing becomes increasingly obvious: windowed conversation is fundamentally a dissipative information device. It generates quickly, expands quickly, and drifts quickly as well. Things that were said have no stable identity, no structural anchor, and no capacity for later aggregation. As a result, it easily turns into a situation where you have “talked a lot, but deposited very little.”
If you agree with the direction of linking together window interaction + personal knowledge base + memory base + invocation library, then the first step is absolutely not to keep optimizing prompts. The first step is to use a strict schema to nail down the identity structure.
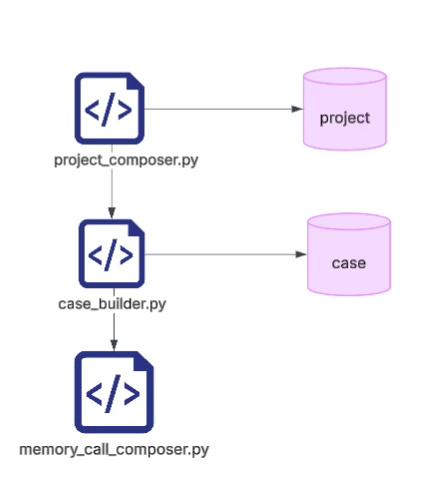
At a minimum, you need the two basic layers of project and case:
projectis the long-running continuum. It represents a continuously evolving problem domain.caseis a single concrete compilation, a single conversational convergence, a single task slice.
One project can contain multiple cases. Only then can those cases later be recalled, compared, aggregated, replayed, and reinterpreted.
Without this layer of identity structure, all outputs are merely temporary text. With it, information is transformed for the first time from floating content into a governable object.
In the most basic schema, what is truly indispensable is not fancy fields, but several categories of fixed anchors.
First, identity keys such as project_id, project_context_id, case_id, and case_type. These answer the questions: Who is this? Which continuum does it belong to? Which slice is it currently in?
Second, the provided layer. This freezes the actual confirmed intention skeleton inside the current case, including intent, scope, constraints, policies, open_questions, readiness, and the original seed_text. In other words, it compresses a single window input into a reusable project context that can continue to be compiled.
Third, source and timestamps. These preserve the source chain, input path, generation run, and provenance rule, ensuring that every later derivation can be traced back to where exactly this round originated.
Going one step further, a case cannot be merely a text result. It must also have its own case.bundle.shell. Because once a case is classified into a certain direction—such as Architecture Decision or Risk Resolution—the downstream invocation should no longer be an unbiased wander through the space. It should instead be driven by the case type, with different query biases, different lenses, different question frameworks, and different output slots.
That means identity structure is not merely about “naming files.” It establishes a foundational governance fact inside the system:
Different cases under the same project may share context, but they differ in problem type, invocation bias, report structure, and downstream aggregation logic.
So the real turning point is here: a knowledge-base pipeline does not begin to mature when it has “stored enough content.” It begins to mature when every piece of content is first bound to a stable identity.
The window itself does not provide continuity. Continuity must be artificially constructed through schema.
The LLM itself does not provide memory order. Memory order must be carried by the identity chain of
project → case → context → bundle.
Once that chain is fixed, multiple cases under the same project can later be aggregated into comparable historical slices. Within the same case, its context, bias, report, and decision can then form a structural closed loop that is replayable, verifiable, and inheritable.
In other words, the next stage of a knowledge-base pipeline is not about becoming more articulate. It is about first ensuring that everything you say acquires an identity that will not drift away
Here comes the most satisfying part: your questions are asked dozens at a time
The problem with window-based conversation is that questions have to be asked one by one. Isn’t that exhausting?
By the time you reach this stage, for this context, this case, this bundle of information that already contains a large amount of project data, open questions, and personal intention—are you really still going to break it apart into one tiny question after another and ask them separately in an LLM chat window?
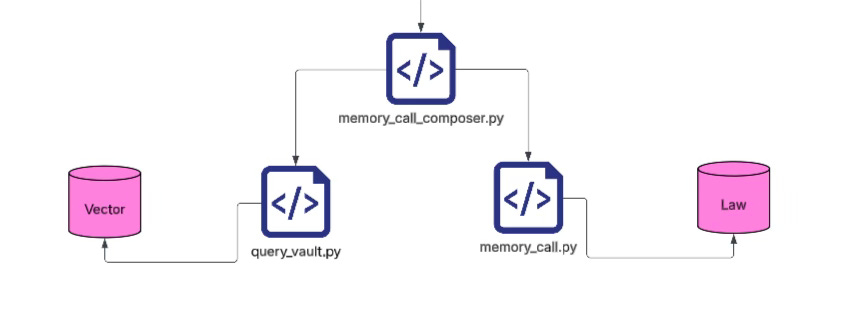
Instead, you write a memory_call_composer. Its job is to gather all project information accumulated so far, together with the information about the intention direction, and then decompose that whole bundle into a series of questions that should be sent to the memory call library for retrieval. One run. That’s it.
Of course, for different intention directions, you can prepare different weighting strategies in advance. I wrote a protocol for this myself: it defines different question directions and corresponding weights. That is an entire design system in its own right, and I will not go into detail on that here.
Once you reach the real retrieval stage, one path uses a kind of vector-based recall. The other path is more structuredand more complex; I will explain that later if I have time. For now, clarifying the principle is more important.
Why do I take these two paths in parallel? Because I believe the truly appropriate solution lies somewhere between them. And this also depends on the quality of the “laws” inside your library.
Most people play with RAG and vector retrieval and feel that it is elegant, powerful, and obviously correct. That feeling exists because their library is still not large enough. Its information density is not yet high enough. Once the information space becomes truly saturated—as happens in some companies—you start to see that plain RAG begins to break down.
What I want to explain here is exactly what level of problem this really is. In computer science, if we want any chance of solving a problem, we first need to define the problem precisely.
"lenses": [
{ "id": "L-GOAL", "weight": 0.95, "title": "Goal & one-liner", "rationale": "Reduce high-entropy intent into a crisp target." },
{ "id": "L-SUCCESS", "weight": 0.9, "title": "Success metrics & definition of done", "rationale": "Make success measurable and testable." },
{ "id": "L-SCOPE", "weight": 0.85, "title": "Scope boundaries (in/out)", "rationale": "Prevent scope creep by explicit inclusion/exclusion." },
The most appropriate analogy for this problem is not actually computer science—it is the legal domain. Law is a classic “hard humanities” discipline. Many people with engineering backgrounds tend to underestimate it, but if you look a bit deeper you realize that in many core aspects the complexity law faces is no lower than that of engineering systems. I personally spent about three months systematically reading some basic materials on the Anglo-American legal tradition, along with bits and pieces of related coursework I had taken in school. Gradually I came to realize something important: many of the problems we repeatedly encounter today in AI, knowledge systems, and engineering decision-making are structurally very similar to the problems studied for decades in Legal Informatics.
If you abstract the issue, the core really boils down to two problems.
1. Applying an existing rule system correctly to new cases
In legal language, this means you have a body of established law—a rule library—and a completely new case appears. The question becomes: how should this case be judged under the existing legal system?
In engineering language, it means: under an existing rule system, how should a new project or problem be executed?
At its core, this problem solves decision continuity. When a rule system can be reliably applied to new cases, you no longer need to rethink everything from scratch whenever a new project appears. You do not have to repeatedly restart projects or rebuild decision logic. Instead, the system can immediately enter the construction phase, rather than getting trapped in endless loops of micro-decisions.
This is exactly the problem I am trying to solve in this article: how to maintain decision continuity when facing new problems.
For programmers to truly escape the “project restart hell,” the key is not getting the model to write more code for you. The key is building a structured core that can rapidly compress new projects into an existing rule system.
When facing a new project, you should not have to start again from a blank document, a blank repository, or a blank mind. You should not have to repeat the entire high-entropy ordeal of requirement decomposition, boundary debates, field naming, relationship definitions, and architectural hesitation.
Instead, you should only need to provide a small amount of high-quality input—for example:
intention
constraints
target users
runtime environment
risk boundaries
core objects
From this, the system should immediately generate a construction-ready structural foundation, including:
architectural layers
module boundaries
authorization boundaries
data flows
object models
field definitions
object relationships
constraint rules
logging strategies
audit paths
It should even determine structural rules such as:
which components must be append-only
which fields must carry stable IDs
which relationships must be explicitly declared
which modules must never read or write across boundaries
All of this should be expanded before coding begins.
In this way, a new project is no longer a one-off creation that starts from zero. Instead, it becomes the act of mapping a new intention into an existing structural universe, locating and instantiating it.
The programmer no longer needs to reinvent the wheel each time. Instead, the system’s accumulated judgment, boundary awareness, object language, field discipline, and relationship protocols can be invoked directly. Past architectural experience becomes a generative capability that unfolds immediately.
The truly valuable outcome is not that AI writes ten functions for you. The real value is that given a simple intention and a few constraints, the system can generate a buildable architectural skeleton:
how many layers the system has
which objects are first-class citizens
which fields serve as identity anchors
which relationships are permitted
which events must enter the ledger
which states are derived and cannot be written directly
which modules can only communicate through explicit interfaces
Only when this level of structure exists does the programmer escape the restart hell. At that point, starting a new project becomes more like invoking a mature structural runtime: input an intention, and immediately receive an executable architectural starting point.
Be honest—doesn’t that feel great?
2. Determining exactly which rules a case matches
The second problem is that you must also know which rules in the rule library a specific case actually hits, and this matching must be precise, explainable, and traceable. It cannot be vague semantic guessing, and the AI must not be allowed to invent rules arbitrarily.
In legal language, this means determining which statutes apply to a real case.
I can say quite clearly that this is one of the central and most difficult problems studied in Legal Informatics for decades.
The problem sounds simple:
given any real-world case, determine all applicable legal rules.
At first glance this might seem like a search problem. But in reality it is far more difficult. If keyword search were sufficient, lawyers would have become obsolete the day Google appeared. Clearly that did not happen.
The reason is that a real case may share no vocabulary overlap at all with the legal rules that apply to it (aside from meaningless words like articles or prepositions). The true problem therefore becomes: how does a case find the legal rules and precedents that actually apply?
This turns out to be one of the hardest information retrieval problems in the world. The difficulty comes from three main factors:
First, statutes and cases rarely match through keywords. Legal rules are abstract principles, while cases describe concrete facts. The connection between them is primarily structural and logical, not textual.
Second, legal reasoning is fundamentally analogical reasoning. It is not simply “rule → conclusion.” Instead it is more like:
“Case A is similar to Case B in key facts, therefore the rule applied in B can also apply to A.”
This type of reasoning structure is extremely difficult for machines.
Third, legal application depends on fact patterns. What matters in a case is not the narrative text but the structure of facts: who participated, what actions occurred, whether intent existed, whether harm occurred, what the surrounding context was. These elements combine into a fact pattern, and legal rules operate on those patterns.
For these reasons, Legal Informatics is an extremely valuable field for programmers to study. Especially after the explosion of AI, a new direction—Legal Automation / RegTech—has been rapidly developing. Applications include contract analysis, compliance review, legal QA systems, litigation prediction, and contract generation. Typical companies include Harvey AI, Casetext (CoCounsel), Ironclad, and LawGeex.
However, to be frank, most current products still remain at the NLP layer. They primarily rely on semantic similarity, vector retrieval, and text generation. The truly difficult problem—structural matching between cases and rules—has still not been fundamentally solved.
If keyword search doesn’t work, why doesn’t embedding fully work either?
First, to be clear: embeddings are not useless. I use them myself, and they work very well in many scenarios—such as personal knowledge bases, medium-sized corpora, and exploratory search.
Early on I relied almost entirely on embeddings. But as my library gradually grew larger and its quality improved, I began to notice a core issue:
Vector retrieval is fundamentally similarity ranking, not match detection.
Most vector databases—FAISS, Milvus, Pinecone—follow the same logic:
convert the query into an embedding
compute cosine similarity
return the top-k results
The problem lies exactly here: top-k is not the same as match.
The system can only say “these are the most similar,” but it can never say “these are the correct matches.”
When your library becomes sufficiently refined, you will almost inevitably arrive at the same technical realization I did:
you will want to measure match counts.
For example, you may want to know how many times a particular rule or law has been precisely matched by the system. When I was building the promotion pipeline described in my previous article, I reached exactly this stage. The idea seemed reasonable: generate candidate rules from high-entropy content, then determine which rules should be promoted into stable structures by counting how often they are matched.
It sounded perfectly logical.
But after nearly two weeks of experiments (during which I built several approximate solutions that initially looked promising), I ultimately abandoned the idea entirely. And I can very clearly recommend that others abandon it too.
It drove me crazy.
Seriously—don’t fall into this trap.
The reason is simple: there is no stable “match set” in vector retrieval.
The semantic space is fundamentally a continuous concept space, not a discrete set. There is no clear relevant/irrelevant boundary. The system can only say that some results are more similar, but it cannot say that a result is a match.
The second problem is that top-k itself is arbitrary. Results differ completely when top_k=5, top_k=20, or top_k=100. A rule might never appear in top-5, but suddenly appear in top-20. So the so-called “match” depends entirely on an arbitrary threshold.
The third problem is that embedding spaces drift. If the embedding model changes—for example from embedding v1 to v2—the entire vector space shifts. The same query may return completely different top-k results. That means all historical statistics become instantly invalid.
Taken together, these factors lead to one conclusion:
Vector retrieval is inherently unauditable.
You can absolutely use it for rough recall, candidate discovery, or exploratory search. But it is very difficult to use it to answer governance-level questions, such as:
“How many times has this rule actually been matched?”
Because in vector space, the concept of match does not exist—only similarity ranking does.
For this reason, many mature systems eventually converge toward a similar architecture:
structural filtering to obtain candidate sets
vector retrieval to expand recall
ranking or reasoning to produce final outputs
In other words, vector search works best as a recall helper, not as the truth layer.
What a real rule “match” looks like in my system
Now let me show you what a genuine rule hit looks like in my system when an intention is processed.
Here, “hit” does not mean semantic similarity or top-k ranking. It means a structural match that can be precisely located to a specific law_id.
In other words, the system can clearly tell you:
which rule was matched,
not merely which rules look similar.
Once matches are determined in this way, they can be further processed structurally:
clustering
visual rendering
binding to specific cases
semantic explanation and expansion via LLM
Eventually this produces a practical analysis report that can guide real implementation.
In such results, the system no longer returns vague semantically similar text. Instead, it returns a set of concrete rule objects, each carrying a stable law_id. These objects can be tracked, counted, reused, and audited.
Only when something is truly matched in this sense can statistics be meaningfully computed.
Let me once again mourn the pit I fell into for several weeks.
{
"schema_version": "law.object.asset.v1",
"id": "AST-1b646b4b",
"kind": "summary",
"status": "active",
"body": {
"title": "Principles Derived From Institutional Positions",
"goal": "Compression/note derived from conversion; not a governance claim.",
"spec": {
"principles": [
"Runtime Traces Are Not Events",
"Event Ledgers Optimize for Accountability",
"Without Replayable Judgment, History Becomes Indefensible",
"Not All Traces Become History"
],
"_gate_reason": "spec_too_thin"
}
},
"links": [],
"evidence": []
{
"schema_version": "law.object.asset.v1",
"id": "CNS-17630e57",
"kind": "constraint",
"status": "active",
"body": {
"title": "Zone I: World State Memory Constraints",
"goal": "Enforce strict quality and update constraints on World State Memory",
"spec": {
"must": [
"High confidence only",
"No speculation",
"No hypothesis",
"No automatic updates"
],
"severity": "binding"
}
},
"links": [],
"evidence": []
},
A Trap Almost Every AI Engineering Team Falls Into
Why “RAG + Vector Databases” often collapse once the scale grows
Rule Databases Must Be Discretized
By the way, if you truly want to achieve precise rule matching, there is a prerequisite you cannot avoid: you must first convert your long-form inputs into highly condensed rule objects with stable IDs.
This is exactly the kind of task that LLMs are exceptionally good at—and the results are surprisingly effective. It is almost the definition of a low-cost, high-return workflow, so it would actually be strange not to do it.
This is how my own library operates. The raw inputs are all long .md articles containing case descriptions, project background, and reasoning processes. As I work on projects, I continuously write and feed these articles into the system. You don’t need to worry about how many inputs there are, and you don’t need to worry about overlap between different articles.
There is only one requirement:
every word in that article must be something you have personally read, agreed with, and endorsed. It must represent your genuine experience, judgment, and accumulated knowledge.
The technical implementation is actually very simple. I keep a small UI permanently open in a browser page. Whenever I have something to record, I type it in and submit it with a single click to add it to the repository. Some days I add only a few entries; other days I might add dozens.
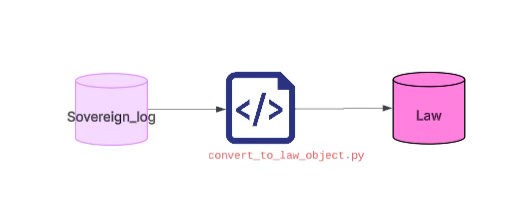
After that, I run a script called convert_to_law_object.py. Again, it’s a one-click operation. The script converts all of the articles entered that day into rule objects and law objects.
This step relies on an LLM (and it doesn’t even require a particularly powerful model). The model handles the extraction extremely well.
Let me give a simple example that you can easily replicate. How many rules can be extracted from a single article, and what category each rule belongs to, is actually determined entirely by your own code logic.
For instance, in the example below, some candidate rules are blocked by the _gate mechanism and therefore downgraded to "summary" instead of "constraint".
In fact, I would recommend making your gate strict rather than permissive. Otherwise the system may automatically generate hundreds of constraints per day, and the rule layer of the entire system will quickly spiral out of control.
{
"schema_version": "law.object.asset.v1",
"id": "AST-1b646b4b",
"kind": "summary",
"status": "active",
"body": {
"title": "Principles Derived From Institutional Positions",
"goal": "Compression/note derived from conversion; not a governance claim.",
"spec": {
"principles": [
"Runtime Traces Are Not Events",
"Event Ledgers Optimize for Accountability",
"Without Replayable Judgment, History Becomes Indefensible",
"Not All Traces Become History"
],
"_gate_reason": "spec_too_thin"
}
},
"links": [],
"evidence": []
{
"schema_version": "law.object.asset.v1",
"id": "CNS-17630e57",
"kind": "constraint",
"status": "active",
"body": {
"title": "Zone I: World State Memory Constraints",
"goal": "Enforce strict quality and update constraints on World State Memory",
"spec": {
"must": [
"High confidence only",
"No speculation",
"No hypothesis",
"No automatic updates"
],
"severity": "binding"
}
},
"links": [],
"evidence": []
},
记忆是可调度的结构, 品位是未来决策空间持续施加偏置的引力场:程序员需要有自己的外置库,否则无法保持自己的决策延续性——也甚至无法维护自己开发的代码
在距离上一次更新文章之后,我的开发又经历了无数次的试错。无数条尝试的链条被打开,又有无数条枝条被剪掉。很多一开始看起来非常 promising 的路径,走着走着发现是死胡同;很多一开始毫不起眼的方向,反而越走越通。总之就是不断地试,不断地拆,不断地重组。终于进行到一个我认为可以停下来写一篇文章分享的阶段了。我们先回顾一下我的初衷。其实我相信很多程序员现在也和我一样,已经明显感觉到一个变化。我和一些朋友聊过一个很重要的事情(也许你已经觉得这根本不是什么新闻了),就是我们都越来越确信,未来的趋势就是不再去细看代码了。肯定不会有人再像过去那样一行一行手打代码。当然,每个人的程度不一样。比如我自己,现在基本已经不看 AI 第一次生成的代码,但是我会去看 diff code。因为我发现,在 diff 的时候经常会看到一些非常有意思的事情。有时候 AI 为了达到我提出的要求,会写出一些让我哭笑不得的代码。举个例子,我要求 AI 做一种结构化的渲染方式,希望未来保持比较好的通用性和可扩展性。结果它给我的解决方案是枚举一长串相关关键词。这个做法在当前问题上是 work 的,但是从结构上来说,这几乎是在主动破坏未来的通用性。这种代码一眼就能看出来,是为了通过当前任务而存在的代码,而不是为了系统长期演化而存在的代码。所以我现在觉得AI 写代码的问题其实从来都不是代码本身,代码只是一个表象。真正的问题,是人在做什么决策,以及这些决策是否能够持续下去。
这也是为什么最近很多程序员都在讨论一个话题,那就是 memory。几乎所有 AI coding 框架最后都会绕到这个问题上。但我问了一圈之后发现一件非常奇怪的事情:几乎没有人能清楚地说出“记忆到底是什么”。记忆是写在书里的内容?写在 Notion 或 Obsidian 的笔记?存在数据库里的信息?LLM 的向量召回?很明显都不是。如果事情真的这么简单,那么 Notion、Obsidian 加上 AI plugin 早就把这个问题解决了。但现实是完全没有。大家还是在不断重复同样的事情。所以慢慢地,我开始觉得,我们想解决的问题其实并不是“记忆”,或者说不是那种人脑意义上的记忆。如果要用一句最简单的话来说,我们真正想解决的问题其实是决策的连续性。
人脑无法在极复杂的场景和长时间的工作中保持决策的连续性,这是我们大部分痛苦的根源。
我说一下现在我自己,以及我相信屏幕前的你,一定遇到过或者已经隐隐感觉到的几个程序员地狱级问题。
1)项目重开地狱。 不管你写过多少代码,不管你做过多少项目,不管你写过多少文档,每当你开始一个新项目的时候,总会有一种非常强烈的感觉:一切又要从头开始了。但与此同时,你又会隐隐觉得事情不应该是这样的。因为你能明显感觉到,很多项目底层结构其实是相同的。很多项目从某种意义上来说只是换了个马甲。哪怕表面上看起来完全不相关,一个是教育 app,一个是知识系统,一个是 web service,一个是 AI 工具,但在底层层面,例如身份管理、权限控制、数据结构、状态管理、事件系统、演化路径,这些结构往往高度相似。问题是,人脑很难把这些结构重新抽出来,再重新组合出来。所以每一次“新项目”,其实都像是进入了一个新的平行宇宙。你会不断看到似曾相识的东西,似曾相识的 bug,似曾相识的架构,甚至连修 bug 的感觉都非常熟悉。每一次项目开始,你都感觉自己又回到了起点。这就是项目重开地狱。
2)Micro-decision 地狱。 即使现在 AI 写代码非常快,但窗口不是万能的,项目从来都不是一个 prompt 就能完成的。一个真实系统更像是一堆层层叠叠的跷跷板,每一个跷跷板的支点其实都是一个决策。这个模块应该放在哪里,这个 API 应该怎样设计,这个数据结构是否可扩展,这个逻辑是否会影响未来,每一个看似微小的决策都会影响整个系统。而在今天的开发环境里,你往往同时扮演前端、后端、架构师、算法工程师、产品经理这些角色,所以这些 micro-decision 全部压在你一个人身上。每一个决策看起来都不大,但它们的数量却是天文数字级别的。你的时间和脑力不断被这些微小决策消耗掉。项目越复杂,这种感觉就越明显。最后你会发现,真正拖慢你的并不是写代码,而是无穷无尽的小决策。这就是 micro-decision 地狱。
3)技术债地狱。 这个大家更熟悉,经典的屎山代码。但在我自己的语境里面,技术债其实还有一种更隐蔽的形态,就是无法演化的技术债。很多时候,当你在做一个项目的时候,其实没有能力去做非常长远的系统规划,因为时间不允许,信息不完整,决策太多,于是很多设计都是临时可用。但问题在于,当系统需要真正升级的时候,你会突然发现技术债已经堆成山了,很多地方不敢改,一改就炸。还是那个跷跷板问题,你按下一块板子,你不知道有多少块板子会因为这个动作而翘起来。于是最后你会做出一个非常熟悉的决定:算了,重开吧。于是我们又回到了项目重开地狱。
如果你仔细看就会发现,这三个地狱其实是同一个问题的不同表现。项目重开、micro-decision、技术债,它们背后的核心问题其实只有一个:决策无法连续。每一次你都在重新做决策,每一次你都在重新思考同样的问题,每一次你都在重新犯同样的错误。而如果把这个问题和最近程序圈最火的一个词连在一起——Taste——事情就变得非常有意思。很多人说,一个真正厉害的工程师最重要的不是代码能力,而是 taste。但 taste 到底是什么?我越来越觉得,taste 本质上就是决策连续性的压缩。一个有 taste 的人并不是每次都重新思考,而是他的很多决策其实早就已经在大脑里被结构化了。所以当新的问题出现的时候,他不是在思考“我该怎么做”,而是在调用“我以前是怎么做的”。所以如果我们把问题说得更直接一点,如果 AI 可以写代码,那么未来真正的问题其实不是如何写代码,而是如何让决策具有连续性。很多人说他们在解决 memory problem,但我觉得那只是一个表面。真正的问题其实是如何把人的决策结构保存下来,并且在未来继续被调用。而我这段时间做的一切试错,其实都是围绕一个问题展开的:如何让决策不再从零开始。
快进一万步,我先告诉你我这段时间已经成功做到的一件事情。现在我写文章,其实已经没有办法按照“实时记录思考过程”的方式来写了。我只能选择在我认为素材已经积累到足够有价值的时候,把某一个阶段的最终觉悟拿出来分享。原因很简单,现在的信息吞吐量实在太大了。每天试错、重构、推倒、再试错的循环太多,我如果把每一个中间状态都写下来,那基本什么事情都不用干了。所以现在我能展示给你的,其实是一个已经跑通的结果:如何从一个意图(intention)出发,一键(就是字面意义上的按一个按钮,至于中间命令行里那些 Yes、No、Continue、复制黏贴之类的动作,其实都不提供额外信息,可以忽略),仅仅依靠代码、模型渲染和调用,以及我自己设计和梳理的知识库,只通过调用库中已经存在的知识,一次性生成一份完整的、能够立即指导可靠代码和系统架构的决策文档。
1)首先,这种方式直接省掉了无数个窗口被拉满的过程。 我相信很多人都有这种体验:当你在做一个项目的时候,看起来只是一个很小的架构问题,比如该选什么框架、某个模块该怎么拆、某个数据结构会不会影响未来演化,但这种问题又偏偏需要一点点全局推演。于是你开始开窗口,一个窗口讨论架构,一个窗口讨论数据库,一个窗口讨论 API,一个窗口讨论部署,再开一个窗口问另外一个细节。等你好不容易把某一个问题讨论出一点眉目,前面讨论的内容早就已经 out of the context window 了。于是你只能再开新窗口,再重复一遍。很多时候你会产生一种非常奇怪的感觉,好像自己在一个符号的海洋里不断地打转,看起来很忙,但其实只是绕着一个很小的圈子反复兜圈子——这当然不奇怪,因为 context window 本来就那么大。所以我意识到,我们必须找到一种方式:针对一个意图,一次性生成一份完整的、高密度的决策文档,这份文档包含架构、约束、路径、关键选择,并且全部基于你目前知识体系中的最佳判断。这样一来,你只需要把这份文档直接交给 AI,它就有完整的决策上下文,而不是在几十个窗口里跟它唧唧歪歪东拉西扯。
2)但真正最难的地方,其实不是生成这份文档,而是你是否能够信任它。 你必须信任到某一个程度,才能放心顺着它往下走,否则你还是会忍不住回到“重新开窗口问一遍”的模式。这一点其实非常难,因为信任的基础并不在于模型,而在于你的知识库本身。道理其实很简单:garbage in, garbage out。如果你的知识库本身是混乱的、碎片化的、未经检验的,那么你生成出来的东西也只会是更快、更系统化的混乱。所以过去几个月,我其实花了非常多时间去研究一个看起来和编程毫不相关的东西——英美法系。我后来慢慢意识到,英美法系其实是人类目前已知的、组织复杂社会规则最成功的结构之一。它能够在一个极其复杂的人类社会中维持秩序、法制和公共意志的一致性。更重要的是,它不是依靠某个“完美设计”的规则体系,而是依靠长期积累、判例沉淀、规则迭代形成的。所以在后面的文章里我会讲到,我在设计自己的知识库结构的时候,其实大量借鉴了英美法的结构逻辑。
3)最后,还有一个非常关键的问题,就是你如何理解“迭代”和“升级”。 还是回到刚才提到的法律系统。我以前其实也隐约提到过一点,但真正深入研究以后我才意识到一个很重要的事实:任何规则,只要是被写下来的,它就不可能是完美的。你只要尝试写规则,就会发现很多人潜意识里的那些追求——比如“完美”“无错”“绝对干净”“没有冗余”“静止不变”——这些关键词其实全部都是不可能的。规则一旦存在,就必然处在变化之中。所以一个真正可用的规则体系,本质上一定是一个开放的信息系统。它必须允许新的信息不断进入,并且有一条明确的管道,让这些信息可以被不断地迭代、升级。我以后会经常用一个词来描述这个过程:promotion。也就是说,你写下来的规则并不自动成为规则。只有当它在大量真实项目中被反复调用、被不断验证、被证明确实好用,它才会慢慢沉淀下来,成为真正的规则。人类的法律其实就是这样形成的——它不是被某个人设计出来的,而是被无数次实践慢慢沉淀出来的。任何没有经过这种锤炼的规则,我试过很多次,最后的结果往往都是一句话:你想得美。理想很丰满,现实很骨感。
记忆是可调度的结构, 品位是未来决策空间持续施加偏置的引力场。这一切都在AI时代成为我们每天面对的现实。感谢强大的LLM。
当你开始把自己日常真正使用的知识写下来的时候,这些知识其实必须经过一次提炼。它们不能只是停留在原始项目里的笔记、代码片段或者零散心得,而是需要被压缩成一种可以跨项目使用的规则。举一个非常简单的例子,比如这样一句话:“Ensure system life run_id is contained within a single OS process lifetime.” 这其实是我在很多不同项目里慢慢积累出来的一个经验。它并不是某一天专门坐下来写的规则,而是埋在很多项目复盘、日记和开发心得里面的一种共识。以前要把这种经验从一大堆笔记里抽出来其实是非常费力的事情,但现在这种提取工作完全可以交给 LLM 来完成。所以我大量的笔记(当然这些笔记本身也是经过精心筛选的)最早被我放在一个叫 Sovereign Log 的地方,这个名字其实就是随便起的。当这些内容经过提炼和筛选之后,原来项目中的 context 会被剥离掉,具体代码会被去掉,但规则本身和真正有价值的结构会被标记出来,然后被分类为一条一条的 Law。换句话说,项目的信息被隐藏了,具体实现被拿掉了,但知识的骨架被保留下来了。这一步其实是 LLM 和确定性代码可以配合得非常好的一个工作:LLM 负责理解和抽取,代码负责结构化和归档。我后面也会把具体代码分享出来,这一部分我非常建议大家采用。
接下来,当你继续在各种项目中开发——不管是自己的家庭项目、团队项目、甲方项目,还是日常工作中的项目——你就会不断去调用这个 Law 库。一旦这些规则被放进具体项目里,它们就重新获得了新的 context,这个时候它们就变成了一个 Case。这一点其实和英美法里的判例非常相似:法律本身在那里,但真正重要的是法律如何在现实情境中被应用、被解释、被裁定。这种“规则与现实结合”的过程,我也是通过代码和 LLM 一起完成的。这个部分其实是整个系统里比较难的一块,因为它涉及到很多流程控制和结构约束,我也是最近才做到一个自己可以稳定使用的程度而已。然后,当这些 Case 在真实项目中运行之后,你就会得到反馈:这个规则到底好不好用,跑得顺不顺,哪里需要修改。接着这些信息又会被重新送回系统,进入下一轮沉淀,形成一个持续循环的信息管道。这里面其实省略了几万行代码和几十万字的数据结构设计,不过核心思想大致就是这样:知识从日志中被提炼成 Law,在项目中被调用成为 Case,再通过真实反馈重新回到系统中继续演化。
我给你们看一个例子,一个非常真实的例子。因为我最近正在家里做一件事情:把家庭网络服务器、所有设备以及物联网应用做一次全面升级。这个项目完全是我私人的,所以我很可能会持续拿它作为例子来分享。我可以自己决定分享这个项目,本来就是私人的。你既不想给未来埋任何雷,又希望整个系统在品质、可靠性和长期维护上都保持很高的标准。
而在这个智能时代,我越来越觉得,一个项目的起点,其实应该从 Intention(意图) 开始,而不是从“我要写什么代码”开始。我们来看一个非常简单的例子:一个清晰的意图,最后是如何帮我省掉几十个窗口里来回拉扯、东问西问、不断补 context 的过程的。更有意思的是,当我的这个 intention 被系统完整处理之后,整个项目从决策到架构再到代码生成,最后真正跑起来进行初步测试并投入使用,总共只花了几个小时。这在过去几乎是不可想象的事情。
python3 tools/intention_compiler.py \\
--text "I intend to configure one of my Mac mini machines to operate as the primary home control plane for my family’s digital infrastructure.This Mac mini will function as a local server that hosts family services, manages identities, and coordinates applications running within the home network.The system will serve as the central node of the home computing environment, providing a stable runtime for family applications, content libraries, and automation tasks.The Mac mini must run continuously and maintain reliable connectivity with the home router." \\
--max-questions 4 \\
--max-rounds 3 \\
--temperature 0.2 \\
--preview
首先要跑的是一个意图压缩的步骤。这个步骤的意思其实很简单:我们既不从提问题开始,也不从下 command 开始,因为这些东西本身都只是意图的衍生形式。真正的起点应该是意图本身。在很多信息管道里,我越来越觉得,意图才应该是系统真正的入口。这个事情如果要完整解释,可能要讲好几天,不过用我自己的经验来说其实很直观:人的意图本来就是做任何事情最原始的目的。而我们平时习惯的方式——比如提问题(典型的就是搜索引擎时代),或者下达 command(比如 LLM 出现之后我们发现可以用自然语言让它生成代码)——其实都是在适应工具。也就是说,为了实现自己的意图,我们受到工具的限制,不得不把原本的意图翻译成问题或者命令。这个过程看起来很自然,但其实是一个不断“翻译”的过程。只要存在人的转化和翻译,就一定会有信息损失,也一定会产生歧义。所以与其在后面不断修补这些偏差,不如一开始就从意图本身出发。
然后,在我一系列代码和流程跑完之后(这一切基本都是全自动的),我实际上几乎没有再做任何事情。除了回答了一些 LLM 在过程中自己衍生出来的小问题之外,没有额外干预,没有重新开窗口讨论,也没有再去手动拼 prompt。系统只是通过 memory call 去调用我的知识库,再经过模型渲染,最后直接生成了下面这一份报告。接下来我就用这份报告直接开始写代码、启动项目。没错,就是这么直接——一键生成。在我看来,这才是对的方式。至于那种在几十个窗口里反复唧唧歪歪、东拉西扯、不断补 context 的做法,其实才是不对的。我后面会把整个原理慢慢讲清楚。而且这个方向我是完全信赖的,因为本质上它是在调我的知识库,很多核心规则和结构本来就是我自己写下来的。换句话说,这不是把决策交给模型,而是让模型去执行我已经沉淀下来的决策体系。当然我不止这一份报告,这种调用token的成本极低,我想要多少有多少。关键是带来的10倍以上效率提升,而且是不断积累的提升,因为每次报告后期再实践的过程中积累的知识和代码,你不是又喂回信息管道里面去了吗?然后在这份报告生成以后的几个小时(当然我又从其他的方向又生成了一堆,继续把项目补全),就已经做完了。在这个基础上把项目搭起来就快了。
# RISK RESOLUTION — Isolation / Traceability / “Telemetry Never Becomes Truth” for an Online-Only Web App
## 0) Conclusion (One Sentence)
**Define “child learning history” as an append-only Event Ledger routed by child scope; define “memory/progress” as Derivation Views that can be reconstructed from the Ledger; define “telemetry/logs” as Ephemeral Telemetry that is discarded by default. The three must be strictly isolated, and any promotion across boundaries must be explicit, auditable, and replayable.**
---
## 1) Scope as a First-Class Citizen: Hard Boundary for Per-Child Isolation
### 1.1 Scope Key (Required on Every Write)
Every write operation (whether an event, asset, derived view, or uploaded file metadata) must include:
* `project_id`
* `child_id`
* `session_id`
* `actor` (`child` / `parent_admin` / `system`)
* `device_id` (optional but recommended)
* `request_id` (for idempotency)
> **Rule: Any write missing a scope key must be rejected** (HTTP 400/403). There is **no such thing as a “default child.”**
---
### 1.2 Storage Routing
Disk layout and indexing must follow a unified routing rule:
* **Physical path**:
`/data/{project_id}/{child_id}/...`
* **Logical index**:
`(project_id, child_id, kind, ts, event_id)`
Shared write locations are **forbidden**.
For example:
* `/data/shared` may only contain a **public content library**
* All assets in `/data/shared` must be **read-only imports created by parent/admin**
This directly implements the rule:
**All writes must be scope-routed by `(project_id, child_id, session_id)`.**
---
## 2) Append-Only Event Ledger: The Only Source of Truth
### 2.1 Status of the Ledger
* **Ledger = Canonical History (single source of truth)**
Anything like:
* progress
* statistics
* mastery levels
* next-question recommendations
**must never be written as ground truth.**
They must exist only as **derived views** (see Section 3).
---
### 2.2 Minimum Event Schema (Recommended)
Every learning / interaction / scoring / correction event must include:
* `event_id`
(content hash or UUID — content-hash preferred for replayability)
* `ts`
(event timestamp)
* `scope`
(`project_id`, `child_id`, `session_id`)
* `actor`
(who triggered the event)
* `event_type`
(finite enum such as
`attempt`, `answer`, `hint`, `reward`, `content_view`, `parent_override`)
* `payload`
(event content)
* `prev_event_ref` *(optional)*
chain reference for stronger replay / tamper-evidence
* `schema_version`
---
### 2.3 Idempotency: Duplicate Submission is the Default State
You explicitly defined the system as:
**online-only**, where network failure, retries, and partial writes are normal.
Therefore:
* the client **must attach `request_id`** to every submission
* the server deduplicates by `(child_id, request_id)`
* duplicate events are allowed to arrive multiple times but **must only be recorded once**
And importantly:
**The client must never advance local progress based on “whether a response was received.”**
This corresponds directly to your law about **implicit state advancement control failure**.
---
## 3) Derivation Views: Progress and Memory are Reconstructable Artifacts
### 3.1 Core Definitions
* `raw_event`
append-only factual record
* `derived_view`
a state snapshot computed from raw events via a deterministic reducer
* `memory`
a **version-frozen artifact produced through explicit promotion**, written into the `law/objects` or vault layer
Memory must **never emerge automatically from raw events.**
---
### 3.2 Reducers Must Be Auditable Functions
Every reducer must include:
* `reducer_id`
* `reducer_version`
Every derived view must record:
* `input_range`
(which events were used)
* `reducer_id@version`
* `output_hash`
Reducers may be upgraded and views rebuilt, but:
**the results must remain diffable and auditable.**
This enables exactly what you want:
**replayable history + rebuildable derived views.**
---
## 4) Telemetry Hygiene: Telemetry is Untrusted and Disposable
### 4.1 Three Hard Rules
Directly implementing your principle:
**“Telemetry must never become truth by accident.”**
1. **Telemetry is ephemeral**
Short TTL only (e.g., 7 days) for debugging and operations.
2. **Telemetry never participates in derivations**
Reducers read only from the ledger.
3. **Cross-boundary promotion must be explicit**
If telemetry is promoted to evidence or knowledge, it must pass through a manual action:
`PromoteTelemetryToEvidence`
producing an auditable artifact with justification and signature.
---
### 4.2 Git / Repository Hygiene
Consistent with your laws:
* `_system` may write automatically
* **runtime outputs must never be committed**
Writes to:
* `sovereign_log/`
* `law/objects`
must always be **human-triggered or explicitly approved promotion events**.
---
## 5) Authorization: Hard Capability Separation Between Child and Parent
### 5.1 Two Capability Domains
**Child Runtime**
Allowed:
* read kid content
* write own ledger events
* read own derived views
Forbidden:
* import content
* modify rules
* query other children
* export data
* promote memory
---
**Parent/Admin**
Allowed:
* import content libraries
* configure rules
* view audits
* export data
* perform explicit promotion
* system maintenance
---
### 5.2 Minimal Session Implementation
Under the constraints:
* **local network only**
* **no external internet access**
A minimal system is sufficient:
* iPad child mode → short-lived session token bound to `child_id`
* parent/admin interface → separate authentication (Mac mini local access)
**A token must never carry both child and admin capabilities.**
This prevents **capability bleed**.
---
## 6) Mac mini Control Plane: Engineering Commitments
Your Risk Resolution (CASE-11AF425603) assumes:
* Mac mini is always running
* no external remote access
* Wi-Fi first, wired if needed
* scheduled backups and maintenance
Engineering commitments therefore include:
**Single-node first**
* one Mac mini acts as both **app server and canonical store**
**Backup is policy, not optional**
At minimum:
* daily incremental backup of ledger + assets + configs
* weekly full snapshot (external disk / second mini / NAS)
**Maintenance windows are explicit**
Updates and migrations must be logged in an **operations log** to prevent silent drift.
---
## 7) Minimal Implementation Checklist
Before writing application code, the following **seven structural rules must exist first**:
1. **Define ScopeKey enforcement**
`(project_id, child_id, session_id, actor, request_id)` required on writes.
2. **Define Ledger Event Schema v1**
finite `event_type`, append-only, idempotent.
3. **Implement Idempotency**
dedup index on `(child_id, request_id)`.
4. **Implement Reducers**
ledger → progress view with reducer version tracking.
5. **Implement Telemetry TTL**
logs stored separately with automatic expiration.
6. **Implement Promotion Gate**
runtime → durable knowledge must pass explicit promotion.
7. **Implement Capability Separation**
child tokens and admin tokens must be strictly isolated.
好,我说说怎么办到的。我给你把关键步骤画出来。都很简单,你光是用我写出来的文字,代码段和命令行输出,直接复制黏贴到你的AI里面,就能八九不离十的生成。
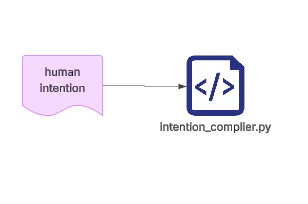
人的意图都是很模糊的:意图不是被提取出来的,意图是被编译出来的。
人的意图不是“参数缺失”的问题,而是“结构尚未成形”的问题。
第一,必须用 LLM。
因为原始意图不是一个已经成型的表单,它往往是混合物:目标、情绪、模糊边界、未命名约束、默认假设、潜在风险、甚至自我矛盾,都缠在一句话里。纯规则或纯文字模板可以抽取一部分,但无法稳定地“展开意图的潜在结构”。
第二,必须落到 schema。
因为如果不进入结构化表示,后面所有 memory call、case classification、composer、scheduler、ledger,都会失去可调度前提。
废话不多说,我给你一边命令行,一边讲代码, 命令行中可以看出有大量的内容是LLM自动延展和提取补全的。
=== ROUND OUTPUT ===
[run_id] 20260305T145405Z__64411957 [round] 1
{
"intent": {
"project_name": "",
"one_liner": "",
"success_metrics": [
"Mac mini runs 24/7 without unexpected downtime for at least 30 days.",
"All designated family services and applications are accessible and functional within the home network.",
"Identity management system reliably authenticates and authorizes family members.",
"Automation tasks execute as scheduled without failure.",
"Content libraries are accessible and synchronized across family devices."
],
"non_goals": [
"Hosting services accessible from outside the home network (no external remote access).",
"Replacing existing internet service or router functionality.",
"Managing devices outside the home network."
],
"time_horizon": "weeks",
"budget_band": "medium"
},
"description": "Set up a Mac mini to act as a local server hosting family services, managing identities, coordinating home network applications, and serving as the central node for home computing, content libraries, and automation tasks. The Mac mini must run continuously and maintain reliable connectivity with the home router.",
"scope": {
"hardware": "One Mac mini machine within the home network.",
"network": "Local home network connectivity only.",
"services": "Family services, identity management, application coordination, content libraries, automation tasks.",
"uptime": "Continuous operation with stable connectivity to home router.",
"devices": [],
"platforms": [],
"infra": [],
"users": []
},
"constraints": {
"hard": [],
"soft": []
},
"policies": [
"access_to_the_mac_mini_and_hosted_services_restricted_to_family_members",
"regular_backups_of_critical_data_and_configurations",
"updates_and_maintenance_scheduled_to_minimize_downtime"
],
"assumptions": [
{
"assumption": "The Mac mini hardware is already owned and available for use.",
"status": "unconfirmed",
"ask": "Do you already have the Mac mini hardware available, or will acquiring it be part of this project?",
"impact": "High"
},
{
"assumption": "Family services and applications to be hoste
...
我这段代码最重要的地方,在于它从一开始就承认“第一轮输入不是真相,只是 seed”。seed_text 不是 final spec,不是需求定稿,也不是可以直接进入实现层的可靠对象,它只是一个高熵起点,一个尚未塌缩完成的主观意向输入。这个判断非常关键,因为大量系统最致命的问题,恰恰就是把用户第一句话误当成需求真相,然后立刻开始写方案、写代码、推荐架构,仿佛输入已经完成了结构化。我明确把第一轮表达视为待编译对象,而不是待执行对象。与此同时,它还把“猜测”制度化,而不是让猜测偷偷发生。代码里的 system prompt 明确要求:every guess MUST be recorded in intention_spec.assumptions[] with status='unconfirmed' and an 'ask' question。这意味着 LLM 可以参与扩展意图,但不能把扩展伪装成事实;系统允许推断,但要求每一个推断都留下结构痕迹,并进入后续确认链条。于是,整个意图空间被清楚地区分为几层:已提供的 provided,推断出来的 inferred,尚未确认的 assumptions,以及必须继续追问的 open_questions。这不是普通意义上的信息整理,而是一种带有认知卫生和治理约束的意图编译方式。更重要的是,它不是一次性 parse,而是多轮递归收敛,这一点最接近真实的人类意图现实。人的意图很少能一次讲清楚,不是因为表达能力不足,而是因为边界、目标、约束、非目标、成功标准,往往都是在追问和反馈中逐步显现出来的。所以这份输出天然是按 round 演进的,命令行里也可以限制最大轮数;而在实际使用中,我通常会在 LLM 的提问开始重复、问题开始枯竭时主动停止,因为这往往意味着当前意图已经接近局部收敛。到最后,这个编译过程不会只吐出一份模糊摘要,而是会直接生成一个 case id,并判断这个意图属于哪一个可枚举的方向。我的意图方向不是无限漂浮的,而是可以被协议化分类的,例如这里这个意图会被归入 Risk Resolution。而这个方向判定也不是纯自动黑盒决定的,它可以由人类与 LLM 共同确认:LLM 提供结构化候选和置信度,人类在必要时进行最终确认。于是,整个系统做的就不再是“把一句话解释一下”,而是把一个高熵意图逐轮编译为一个具备 case identity、方向归类、未决问题清单和后续流转前提的结构对象。这份代码如此简单,你现在把我这段话,加上我的示例,直接给AI,你就能马上生成一份意图编译的代码。
=== ROUND OUTPUT ===
[run_id] 20260305T145405Z__64411957 [round] 2
{
"intent": {
"project_name": "Home Mac Mini Control Plane Setup",
"one_liner": "Configure a Mac mini as the primary local server for family services, identity management, and home automation within the home network.",
"success_metrics": [
"Mac mini runs 24/7 without unexpected downtime for at least 30 days.",
"All designated family services and applications (children's education, home mail/document scanning and AI reading, home inventory management, home calendar management) are accessible and functional within the home network.",
"Identity management system reliably authenticates and authorizes family members.",
"Automation tasks execute as scheduled without failure.",
"Content libraries are accessible and synchronized across family devices.",
"Mac mini maintains stable connectivity over Wi-Fi with the home router."
],
"non_goals": [
"Hosting services accessible from outside the home network (no external remote access).",
"Replacing existing internet service or router functionality.",
"Managing devices outside the home network.",
"Wired network connectivity setup (currently relying on Wi-Fi)."
],
"time_horizon": "weeks",
"budget_band": "medium"
},
"description": "Set up a Mac mini (2-3 units available) to act as a local server hosting family services including children's education, home mail/document scanning with AI reading, home inventory management, and calendar management. It will manage identities and coordinate home network applications, serving as the central node for home computing, content libraries, and automation tasks. The Mac mini must run continuously and maintain reliable Wi-Fi connectivity with the home router. No external remote access is planned at this time.",
"scope": {
"hardware": "2-3 Mac mini machines already acquired, one to be configured as primary server.",
"network": "Local home network connectivity only, currently over Wi-Fi.",
"services": [
"Children's education applications",
"Home mail/document scanning and AI reading",
"Home inventory management",
"Home calendar management",
"Identity mana
...
=== QUESTIONS ===
[P0] Q-1: Are you open to using wired Ethernet connectivity if Wi-Fi proves unreliable for continuous operation?
Answer (empty to skip): Let's try hard to make Wi-Fi work first.
[P1] Q-2: Do you have existing backup solutions or preferences for backing up the Mac mini and its data?
Answer (empty to skip): No existing solutions but openned for options.
Continue to next round? [Y/n]: n
[skip] user stopped; partial artifacts preserved.
[confirm] Case type requires human confirmation.
Primary: Risk Resolution
Secondary candidates: Architecture Decision, Exception Handling, Intent Clarification
Confirm case type (enter to keep pending): Risk Resolution
/Users/sovereign_knowledge_lab/_system/calls/intention_compiler/20260305T145405Z__64411957/FINAL/intention_for_composer.json
你既然都自己建知识库了,那就必须要把身份结构给固定了:你这个context需要长期保存!
下一个阶段的核心,不是继续往知识库里堆材料,而是先把任何管道都必须依附的清晰身份结构固定下来。只要你长期使用 LLM,就会越来越清楚地看到,窗口会话本质上是一种消散型信息装置:生成很快,展开很快,漂移也很快,说过的话没有稳定身份,没有结构挂点,没有后续可聚合性,所以很容易变成“聊过很多,沉淀很少”。如果你认同“窗口交互 + 个人知识库 + 记忆库 + 调用库”必须联动的路线,那么第一步绝对不是继续优化 prompt,而是先用严格 schema 把身份结构钉死。至少要先有 project 和 case 这两个基本层级:project 是长期连续体,代表一个持续演化的问题域;case 是一次具体编译、一次对话收敛、一次任务切面;一个 project 可以包含多个 case,而这些 case 未来才能被回收、比较、聚合、重放、再解释。没有这层身份结构,所有输出都只是临时文本;有了这层身份结构,信息才第一次从“漂浮内容”变成“可治理对象”。
最基础的 schema 里,真正不可缺的不是花哨字段,而是几类固定锚点:第一,project_id、project_context_id、case_id、case_type 这类身份键,用来回答“这是谁、属于哪条连续体、当前处于哪个切面”;第二,provided 这一层,用来冻结当前 case 中真正被确认的意图骨架,包括 intent、scope、constraints、policies、open_questions、readiness 和原始 seed_text,也就是把一次窗口输入压缩为一个可复用、可继续编译的项目上下文;第三,source 和时间戳,用来保留来源链、输入路径、生成 run 与 provenance rule,确保后面所有派生都能追溯到这一轮到底是从哪里来的。再进一步,case 不能只是一个文本结果,还必须有自己的 case.bundle.shell,因为 case 一旦被判定为某种方向,比如 Architecture Decision 或 Risk Resolution,后续调用就不该再是无偏漫游,而应当由 case type 驱动不同的 query bias、不同的 lenses、不同的问题框架与输出槽位。也就是说,身份结构不只是“给文件起名”,而是在系统里建立一条最基本的治理事实:同一个 project 下的不同 case,虽然共享上下文,但问题类型不同、调用偏置不同、报告结构不同、后续聚合方式也不同。
所以,真正的转折点在这里:知识库的管道不是从“存了多少内容”开始成熟,而是从“每一份内容是否先被绑定到稳定身份”开始成熟。窗口本身不提供连续性,连续性必须由 schema 人为建出来;LLM 本身不提供记忆秩序,记忆秩序必须由 project → case → context → bundle 这条身份链来承载。只要这条链固定住,未来同一 project 下的多次 case 就能被聚合为可比较的历史切片;同一 case 的 context、bias、report、decision 也才能形成可回放、可验证、可继承的结构闭环。换句话说,知识库管道的下一个阶段,不是更会说,而是先让每一次说出来的东西,都有一个不会漂走的身份。
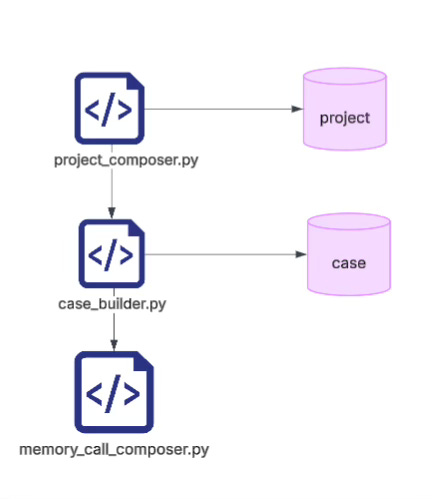
最爽的地方来了,你的问题是几十个一起提的
窗口的对话的问题需要一个一个来提,你累不累啊。当你走到这一步的时候,针对你这个context, 你这个案例,你这个已经集合了大量信息,问题,个人意图的信息bundle, 你还拆成一条一条的问题来问LLM窗口吗?写一个memory_call_composer, 这里把直到目前为止,所有项目信息和意图方向的信息集合在一起,再拆成一系列需要memory_call 库查询的问题。一次运行。当然针对不同的意图方向,你可以提前写一份权重,我是写了一份protocol,设计不同的问题方向和权重,这个又是一整套的设计,这里暂时不细说。走到真正的问询阶段,一条我们用一种向量化的召回。另一种,比较结构化,比较复杂,我后面有时间再讲,这里把原理讲清楚,更重要。为什么分两条路走,因为我认为真正合适的解法处于这两者之间,这个跟你库里的“法条”的质量也有关系。一般人玩RAG,向量召回,感觉很爽,很对。那是因为库不够大!信息密度不够密集。只要信息一旦充满,比如一些企业,就会发现RAG要出问题。在这里,我想具体的讲讲,这个到底是一个什么级别的问题,在计算机界,我们需要准确的定义问题,才有可能解决问题。
"lenses": [
{ "id": "L-GOAL", "weight": 0.95, "title": "Goal & one-liner", "rationale": "Reduce high-entropy intent into a crisp target." },
{ "id": "L-SUCCESS", "weight": 0.9, "title": "Success metrics & definition of done", "rationale": "Make success measurable and testable." },
{ "id": "L-SCOPE", "weight": 0.85, "title": "Scope boundaries (in/out)", "rationale": "Prevent scope creep by explicit inclusion/exclusion." },
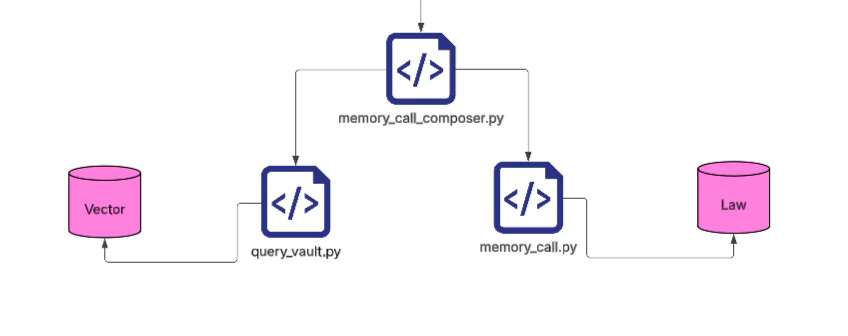
这个问题,其实最合适的类比并不是计算机科学,而是法律界。法律是一门典型的“硬文科”,很多理工科背景的人很容易低估它,但如果真正深入一点就会发现,在很多核心问题上,法律面对的复杂度一点不比工程系统低。我自己大约花了三个月系统看了一些英美法系的基础材料,再加上以前在学校零散上的相关课程,逐渐意识到一件事:我们今天在 AI、知识系统、工程决策中反复遇到的很多问题,其实和 Legal Informatics(法律信息学)几十年来研究的问题是高度同构的。
如果把问题抽象出来,其实核心只有两个。
第一,你希望既定的规则体系能够在新的案例中被正确执行。换成法律语言,就是你有一套既定的法律体系(规则库),现在出现了一个全新的案件,你想知道在这套规则之下,这个案件应该如何判决;换成工程语言,就是在既有规则体系下,一个新的项目或问题应该如何操作。这个问题本质上解决的是决策连续性(decision continuity):当规则体系能够稳定地作用于新的案例时,你就不需要每遇到一个新项目都重新开始思考,不需要反复重开项目、重造决策逻辑,系统可以直接进入核心建造阶段,而不是陷入无穷无尽的微观决策循环。这也是我这篇文章真正想解决的问题:如何让系统在面对新问题时保持决策连续性。
要让程序员真正摆脱“项目重开地狱”,关键不是让模型替你多写一点代码,而是建立一种能够把新项目快速压缩进既有规则体系的结构化内核:当你面对任何一个新项目时,不需要再从空白文档、空白仓库、空白脑袋开始,也不需要重新经历一遍需求拆解、边界争论、字段命名、关系定义、架构摇摆这些高熵折磨;你只需要给出少量高质量输入,比如意图、约束、目标用户、运行环境、风险边界、核心对象,系统就应该能够立刻生成一套可进入建造阶段的初始结构,包括架构分层、模块边界、权限边界、数据流、对象模型、字段定义、对象关系、约束规则、日志策略、审计路径,甚至连哪些东西必须 append-only、哪些字段必须具备稳定 id、哪些关系必须显式声明、哪些模块绝不能跨边界读写,都应该先于编码被直接展开。这样一来,新项目就不再是“从零开始的一次性创作”,而是一次“将新意图映射到既有结构宇宙中的定位与实例化”;程序员不再需要每次重造轮子,而是把系统已有的判断力、边界感、对象语言、字段纪律和关系协议直接调用出来,把过去沉淀下来的架构经验转化为可以即时展开的生成能力。真正有价值的,不是让 AI 帮你写十个函数,而是让它根据简单意图和约束,直接产出一个可以落地的建造骨架:这个系统分几层,哪些对象是第一等公民,哪些字段是身份锚点,哪些关系允许存在,哪些事件要入 ledger,哪些状态只能派生不能直写,哪些模块之间只能通过显式接口通讯。只有做到这里,程序员面对新项目时,才不是再次掉入重开地狱,而是像调用一个成熟的结构 runtime 一样,输入意图,立即获得可执行的架构起点。
就问你,爽不爽?
第二,你还需要知道一个具体案例到底命中了规则库中的哪些规则,而且这种命中必须是精准、可解释、有出处的,而不是模糊的语义猜测,更不能让 AI 随意胡诌规则出来。换成法律语言,**就是一个真实案件到底适用哪些法律条文。**这里我可以很明确地说,这是 Legal Informatics 领域几十年来最核心、也是最困难的问题之一。这个问题可以表述得非常简单:让任何一个真实世界的案件,能够命中所有适用的法律条文。听起来像是一个搜索问题,但实际上远远不是。如果只是关键词搜索,那么 Google 出现的那一天,大量律师就应该失业了,但现实显然不是这样。原因在于,一个真实案件所适用的法律条文,很可能和案件描述之间没有任何词汇重合(除了冠词、介词这种无意义词)。因此问题的本质变成:一个案件如何找到真正适用的法律条文和判例。这其实是世界上最困难的信息检索问题之一。难点主要来自三个方面。第一,法条与案例之间往往没有关键词匹配关系,法律条文是抽象规则,而案件是具体事实,两者之间的连接更多体现在结构与逻辑上,而不是字面文本。第二,法律推理本质上是类比推理(analogical reasoning),法律并不是简单的规则推理“规则→结论”,而更像“案例A与案例B在关键事实上相似,因此B中的规则可以适用于A”,这种推理结构对机器来说非常困难。第三,法律适用依赖的是事实模式(fact patterns),案件真正重要的不是它的叙述文本,而是其事实结构,例如谁参与、发生了什么行为、是否存在意图、是否造成损害、事件的背景环境等,这些事实元素组合在一起形成所谓的事实模式,而法律规则实际上是作用在这些事实模式之上的。正因为这些原因,Legal Informatics 才成为一个非常值得程序员关注的领域,尤其是在今天 AI 爆发之后,一个新的方向正在快速发展,即 Legal Automation / RegTech(法律自动化)。这一领域的应用包括合同分析、合规审查(compliance)、法律问答、诉讼预测、合同生成等,典型公司包括 Harvey AI、Casetext(CoCounsel)、Ironclad、LawGeex 等。不过必须坦率地说,目前绝大多数产品其实只停留在 NLP 层,它们主要依赖语义相似度、向量检索和文本生成来工作,而真正困难的问题——案例到法条的结构匹配——到今天仍然没有被真正解决。
既然关键词搜索不行,那么为什么 embedding 也不太行?
先说结论:embedding 并不是完全不行,我自己也在用,而且在很多场景下其实非常好用,比如个人知识库、中小规模语料、探索式搜索。我早期也几乎完全依赖 embedding,但随着库逐渐扩大、质量逐渐提高,我慢慢意识到一个核心问题:向量召回的本质是相似度排序(similarity ranking),而不是命中判断(match detection)。大多数向量数据库,例如 FAISS、Milvus、Pinecone,底层逻辑其实都非常简单:先把 query 转成 embedding,然后计算 cosine similarity,最后返回 top-k 的结果。问题就在这里:top-k 并不等于 match。系统只能说“这些是最像的”,但它从来没有说“这些是正确命中的”。
当你的库逐渐变得精良时,你几乎必然会和我一样推导到同一个技术节点:你会想做命中统计。
例如,你会想知道某一条规则或法条到底被系统精准命中过多少次。我在上一篇文章说我在做 promotion pipeline 的时候就走到了这一步:从高熵内容中产生候选规则,然后通过统计命中次数来决定哪些规则应该被晋升为稳定结构。听起来非常合理,但我在将近半个月的实验之后(期间做出过几次看起来还不错的近似方案)最终彻底放弃了,而且我可以很明确地建议别人也放弃,因为效果很差,得不偿失。
真是气死我了。千万不要踩这个坑。
原因很简单:在向量检索里根本不存在稳定的“命中集合”。语义空间本质上是一个连续的 concept space,而不是一个离散集合,因此不存在清晰的 relevant / irrelevant 边界。系统只能告诉你某些结果更像,而不能告诉你某条结果“就是命中”。
第二个问题是 top-k 本身就是人为截断,例如 top_k=5、top_k=20、top_k=100 时结果会完全不同;在 top_k=5 时某条规则可能完全没有被召回,但在 top_k=20 时它又突然出现了,所以所谓的“命中”其实取决于人为设定的阈值,这在统计上是非常不稳定的。
第三个问题是 embedding 空间本身是会漂移的,只要模型升级,例如 embedding v1 换成 embedding v2,整个向量空间都会改变,同一个 query 在新模型下得到的 top-k 可能完全不同,这意味着所有历史统计都会瞬间失效。
综合这些因素:向量检索天然不具备审计性(auditability)。你当然可以用它做粗召回、找候选、找灵感,但很难用它来回答一个治理系统真正关心的问题,例如“某一条规则到底被命中了多少次”。因为在向量空间里,match 这个概念本身就不存在,只有 similarity ranking。也正因为如此,很多成熟系统最终都会收敛到类似的架构:先做结构过滤得到候选集合,再做向量召回,然后再进行排序或推理。换句话说,vector search 最适合扮演的是 recall helper,而不是 truth layer。
现在给你看一下,在我的系统里,一条 intention 真正意义上的“规则命中” 是什么样子的。这里的“命中”不是相似度意义上的接近,也不是 top-k 排名里的候选,而是可以被精确定位到具体 law_id 的结构命中。换句话说,系统能够明确地告诉你:我命中的是哪一条规则,而不是“看起来像哪几条”。一旦命中被这样确定下来,这些结果就可以进一步做结构化处理,例如聚类、可视化渲染、与具体案例进行绑定,然后再通过 LLM 的语义能力进行解释和展开,最终生成一份真正可以指导实践的分析报告。例如在下面这个结果里,系统返回的不再是模糊的语义相似内容,而是明确的规则对象集合,每一个对象都带有稳定的 law_id,可以被追踪、统计、复用和审计。这种“被搜索中”了,才可以做统计。
再心疼一下我前几周踩的坑。
"result": {
"count": 3,
"summary": [
{
"id": "CLM-1ccc03b0",
"kind": "claim",
"title": "Do not institutionalize model behavior in session isolation",
"goal": "Clarify that isolation enforcement targets storage and event routing, not LLM internal memory.",
"law_id": "LAW-3a0c1a81"
},
{
"id": "CLM-900f1b5c",
"kind": "claim",
"title": "Only System Ledger is Valid Release Destination",
"goal": "Identify exclusive storage location for releases",
"law_id": "LAW-a65c1f79"
},
{
"id": "CLM-2e37275b",
"kind": "claim",
"title": "Memory Is a Time-Responsibility Contract",
"goal": "Clarify how memory is conceptually treated in the system",
"law_id": "LAW-0f8a2991"
}
]
AI 工程团队都会踩的坑:
为什么“RAG + 向量数据库”在规模变大之后经常崩溃。
规则数据库必须离散化
顺便说一句,如果你真的想做到精准命中,有一个前提是绕不过去的:你必须先把自己那些长篇大论的输入,转化为高度精炼、带有稳定 ID 的规则或法条对象。这一步恰恰是 LLM 非常擅长的事情,而且效果好得出奇,几乎是“低成本高收益”的典型场景,所以不做反而才奇怪。我自己的库就是这样运作的:原始输入全部是带有案例、项目背景和思考过程的长篇 .md 文章。我每天一边做项目一边写,持续往库里输入;你不用管输入多少,也不用管不同文章之间有没有重合。唯一需要确保的一件事是:这篇文章的每一个字你都读过、认可、同意,它代表的是你真实的经验、判断和积累。技术实现其实非常简单,我就是把一个 UI 长期挂在网页上,随时输入,一键入库。每天少则几条,多则几十条。
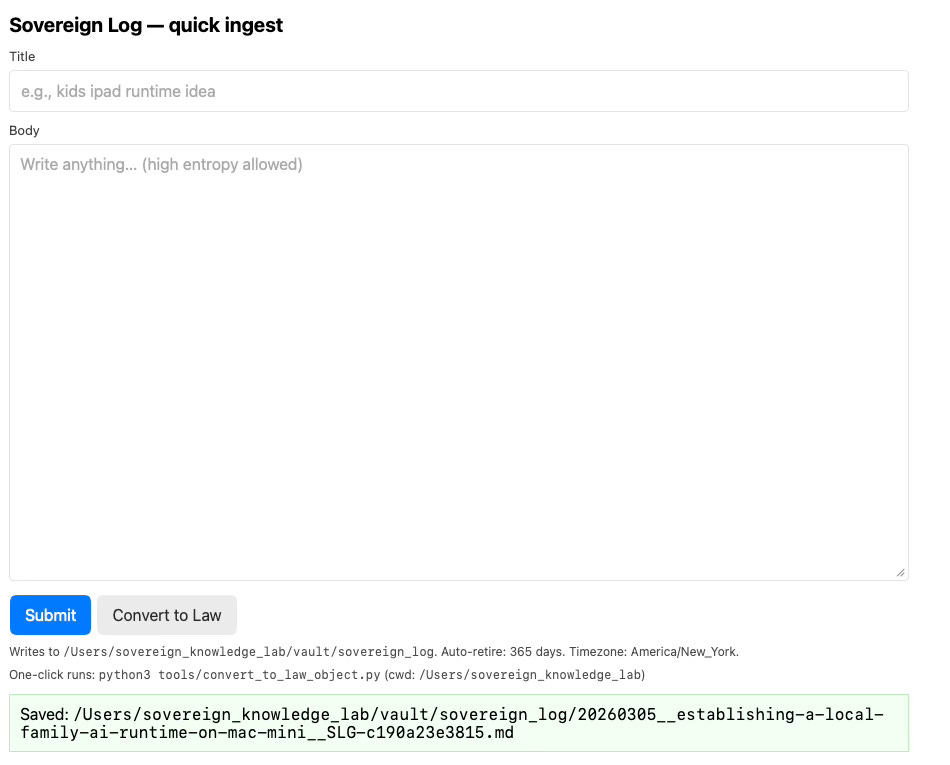
接下来再写一个 convert_to_law_object.py 脚本,同样是一键操作,把当天所有输入的文章自动转换成规则对象和法条对象。这一步调用 LLM(甚至不需要特别强的模型)就可以做得很好。我给个简单例子你很容易复制:一篇文章到底能提取出多少条规则、每一条属于什么类型,其实完全由你的代码逻辑决定。比如下面这个例子,有些候选规则会被 _gate 拦下来,于是被降级为 "summary",而不是 "constraint"。我反而建议你把 gate 写得严格一点,否则系统每天可能会自动产生几百条 constraint,最后整个规则层会迅速失控。
{
"schema_version": "law.object.asset.v1",
"id": "AST-1b646b4b",
"kind": "summary",
"status": "active",
"body": {
"title": "Principles Derived From Institutional Positions",
"goal": "Compression/note derived from conversion; not a governance claim.",
"spec": {
"principles": [
"Runtime Traces Are Not Events",
"Event Ledgers Optimize for Accountability",
"Without Replayable Judgment, History Becomes Indefensible",
"Not All Traces Become History"
],
"_gate_reason": "spec_too_thin"
}
},
"links": [],
"evidence": []
{
"schema_version": "law.object.asset.v1",
"id": "CNS-17630e57",
"kind": "constraint",
"status": "active",
"body": {
"title": "Zone I: World State Memory Constraints",
"goal": "Enforce strict quality and update constraints on World State Memory",
"spec": {
"must": [
"High confidence only",
"No speculation",
"No hypothesis",
"No automatic updates"
],
"severity": "binding"
}
},
"links": [],
"evidence": []
},
意图是需要上下文去理解的。就像一个文章让不同的人去看,他们看到的重点不一样。LLM除非你让他很了解你,他就会知道你的意图。不然就只能硬编码的搜索。或许你可以给LLM一个人格,然后让他用这个指令的视角去理解文本背后的意图。
-------
OPUS:
为什么这件事这么难?
核心原因是:语言的表层和结构的深层之间,不是一个简单的映射关系。
当你朋友说"人的念头是一个意图",他其实在说一件很准确的事——人在读一个案例的时候,并不是在做关键词匹配,而是在做一种"这个情境里,谁欠了谁什么,谁没做到,后果落在了谁身上"的结构性理解。这个理解过程是意图层面的,不是词汇层面的。
现在RAG的困境在于:embedding模型擅长捕捉语义相似性("车辆"和"汽车"很近),但不擅长捕捉结构同构性("司机没锁门"和"承运人未尽义务"在embedding空间里可能离得很远,因为它们的语义表面完全不同)。
所谓"面向意图编程"的困难,本质上有几层:
第一层是抽象阶梯的问题。同构意味着你要在更高的抽象层级上匹配,但搜索系统工作在具象层级。"没锁车门"要先被抬升到"未尽安全保障义务",才能跟法条匹配上。这个抬升本身就需要法律推理能力,等于你要先理解了才能检索到,形成一个鸡生蛋的问题。
第二层是意图的多义性。同一个事实可以被多种法律框架解读——那个案例既可以归到合同法的安全保障义务,也可以归到侵权法的过失责任。意图不是一个确定的点,而是一个可能性的扇面。系统不知道该往哪个方向抬升。
第三层是结构识别本身需要世界模型。人能看出同构,是因为人脑里有一个"义务-违反-损害"的因果图式。这不是从文本里直接读出来的,是人带着整个法学训练的认知框架去投射上去的。你要让机器做同样的事,它需要的不是更好的检索,而是一个法律关系的世界模型。
这不是一个检索问题,这是一个认知问题。可能更有效的路径不是改善搜索本身,而是在检索之前先让LLM做一步"意图翻译":把案件事实先抽象成法律关系的结构化表达,再用这个结构化表达去检索。相当于让模型先扮演律师的思考过程,再去查法条,而不是拿着原始事实直接搜。