
Reviewing Lessons of the Year: The Decade of Agents: Essential Agent Skills for 2025 (Powered by Google ADK and a lot of self-made projects) Part 1
智能体十年:2025 年必备的 Agent 技能 (理论和50+实操小项目), 作为年终学习计划

Let’s start from Google ADK. As the opening chapter of the decade of agents, I believe ADK is the minimum “digital literacy” that every person in 2025 — anyone who has basic computer skills and is willing to move one small step forward — should master. It doesn’t require you to become a programmer, but it will become the most important and irreplaceable foundation for your continuous education over the next decade.
To make sure you can actually learn it, build it, and run it, I will break the required knowledge into dozens of very small, very stable, and highly executable mini-projects — each one something you can “check off” like a tile. I will provide the code, examples, and toolchain so success is guaranteed. If by the end of 2025 you complete this “skill map” and the ~50 mini-projects, you will have future-proof foundational skills for the next ten years.
More lessons, codes, Git, will be released soon.
Why start with ADK?
Google describes it this way:
ADK is a modular framework that brings software-engineering principles into AI agents, turning agent development from “prompt play” into real software engineering.
But behind that definition lies a major leap forward.
For the past few years, when people said they were “learning AI,” what they really meant was:
Knowing how to use a chat window
Knowing how to write prompts
Calling APIs
Tweaking temperature / top-p
Doing a bit of RAG
Essentially: treating the model as a black-box super autocomplete
But this layer of “AI usage ability” is already near its ceiling — and cannot accumulate meaningfully.
The next layer , the truly important skill for the next five years is:
“Learning AI = learning how to build stateful, tool-powered, scheduler-driven agent systems.”
ADK assumes you are not building a chat toy , you are building a system:
Agents with clear boundaries (identity, responsibilities, permissions)
Tools they can call (databases, external APIs, local code, other agents)
Sessions / Memory as long-horizon timelines
Runners / Orchestrators managing execution flow
Ultimately a Multi-Agent System (agents calling agents)
ADK is telling everyone learning AI:
The future won’t be about who writes better prompts,
but who can embed models into real systems using natural language.
Sounds technical? Actually not — it’s collapsing in complexity.
When Excel first appeared, it looked “technical” too; ten years later, it became basic literacy.
ADK is following the same path.
It looks like a developer framework, but its real meaning is:
It compresses the things only engineers could do into natural-language-level operations.
What used to require:
Writing code
Handling databases
Managing state machines
Designing workflows
Platform integrations
Toolchain composition
Will soon only require:
Describing intent
Defining tools
Configuring memory
Letting the scheduler run
Building an agent will become as mainstream as learning Excel once was.
Mastering ADK’s core abilities (tool calling, state & memory handling, scheduling, workflows) means you can:
Have an automated personal digital assistant
Automate the processes of your daily life
Make multiple apps operate silently behind you
Build executable systems with natural language
Turn the model into a true extension of your abilities
This is the next generation of “Office skills.”
The trajectory of digital skills:
1980s: BASIC → computer literacy
1990s: Windows → GUI literacy
2000s: Office → workplace literacy
2010s: Mobile Apps → mobile-internet literacy
2030s: Agent Operations → AI-era literacy
Future digital literacy is not PPT, not Excel, but:
Being able to orchestrate AI, operate agents, and turn language into action.
ADK is the first LEGO brick of this new literacy.
Of course, the course still requires basic computer usage — VSCode, terminal, virtual environments — but this is not a “programmer barrier.” It is simply baseline 21st-century digital skill. No matter your age or background, if you want to learn, this is the entrance. I’m not going to throw a giant list of entry points at you , everyone’s time is limited.
Your goal is not to become an engineer.
Your goal is to master the “agent operation skill” everyone will need in the next decade.
What about other frameworks? Why didn’t I choose them?
There are many other choices today:
OpenAI’s MCP (Model Context Protocol)
Anthropic’s Claude Skills / Computer Use (which I actually recommend on my site; extremely friendly for total beginners)
Microsoft AutoGen / Semantic Kernel
LangChain / LlamaIndex and other community frameworks
They’re all powerful, but each has a fatal issue:
too low-level, too abstract, too fragmented, or fundamentally unsuited as a personal operating system.
MCP is for system integration — you must build your own routers, permissions, and tool ecosystems.
Claude Skills is powerful but closed — like iOS, not a freely shaped OS.
AutoGen is research-focused, not engineering-focused.
LangChain is too fragmented — each major update forces you to rebuild your mental model.
And enterprise cloud frameworks are too closed and too IT-oriented for personal Agent OS use.
ADK is unique because it is neither a toy nor a monolith — but a unified abstraction layer usable from personal scale to production scale.
It provides the pieces that are most needed, hardest to reinvent, and most impossible to be without:
Unified session/memory (event-stream memory)
Composable tool protocol (function calling as language protocol)
Built-in code executor (let language become action)
Multi-agent scheduling (pipeline-level, not toy-level)
Lightweight, clean, engineering-grade, vendor-lock-in free
Most importantly: define system logic in natural language, and it runs
In other words, ADK is a “personal-scale operating system” — a framework that frees you from “dying in the low-level code” and lets you focus on building structures, designing protocols, and creating schedulable intelligence.
This skeleton is enough to support your entire 2025 continuous-education arc.
Let’s look at what this knowledge set actually includes:
The basic flow follows Google’s 5-day course. What I’ve done is simply break that course down into finer, more beginner-friendly steps, and integrate my own code, structure-oriented thinking, and execution logic.
The result is a version of the “5-day expert course” that a motivated beginner can slowly and fully complete without missing any critical concepts.
https://www.kaggle.com/learn-guide/5-day-agents
1) Introduction to AI Agents
https://www.kaggle.com/whitepaper-introduction-to-agents
In this section, we first need to quickly review where AI Agents currently stand, where they will go in the next five years, and which capabilities are predictable, essential, and absolutely non-skippable. The direction of agents is not chaotic — it already shows a very clear technological evolution path.
Across the industry, the generally accepted agent progression can be divided into five levels:
Level 0 — Bare LLMLevel 1 — Tool-Enhanced SolverLevel 2 — Strategic Multi-Step AgentLevel 3 — Collaborative Multi-Agent SystemLevel 4 — Self-Evolving System
This is the “public highway” of agent technology for the next five years. To be capable of building future systems, understanding and mastering the techniques required to reach each level will be an extremely valuable skill set.
Along this evolutionary path, the capabilities of all strong agents converge into three cores:
1) Model Routing — “Who thinks?”2) Context Management — “What does the brain see?”3) Agent Ops & Persona (Governance Layer) — “Rules, identity, permissions”
These three are the essential “operating system skills” that all future AI engineers, system architects, and even non-technical professionals must master.
At the same time, a series of unavoidable industrial-grade challenges emerge:
Agent Evaluation: reliability, stability, success rate
Observability: auditability, logs, traceability
Safety & Risk: stronger capability = greater risk
Identity & Access Control: agents are digital persons, not copies of users
Multi-Agent Governance: control plane for agent societies
Learning & Simulation (Agent Gym): agents must learn inside safe sandboxes
These may sound advanced, but they are exactly the thresholds agents must cross to reach industrial and production grade. Without them, there is no “AI industrial revolution.”
All of these technical and governance capabilities ultimately point to one underlying truth:
The Orchestrator is the soul of the Agent.
Among the trio of “Model – Tool – Orchestrator,” the true dividing line between a “toy agent” and a “system-level agent” is not the model or the tool , it is:
the Orchestrator.
The model is only an autoregressive prediction engine — no structure, no boundaries, no will.
Tools are hands without a brain — they don’t know when or how to use themselves.
Only the Orchestrator determines the agent’s real capability:
Model Routing: when to switch models, who should think
Context Management: what enters the brain, what is filtered out
Ops & Persona: rules, constraints, identity, permissions, behavioral boundaries
Therefore:
The intelligence ceiling of an agent = the orchestrator’s context-management capability.
The reliability of an agent = the orchestrator’s governance capability.
Ultimately, the orchestrator determines whether an agent remains a “confused bat” or evolves into an autonomous system unit.
Over the next five years, every agent technology is sprinting along this same road. To understand it is to understand the trend; to master it is to stand at the entrance of the future.
This section’s hands-on project: Build the smallest possible AI Agent from scratch.
We will create an ultra-minimal project consisting of just three components:
one Agent, one Runner, and one Tool (Google Search).
This is the “atomic cell” from which all later capabilities — multi-agent, memory, statefulness, tool packs, schedulers — will grow.
This base project has three core parts:
A minimal Agent (
root_agent)A minimal scheduler (
InMemoryRunner)A first basic invocation (
run_debug)
The entire goal is singular:
Let this tiny agent “take its first breath” and perform its first action — automatically call Google Search to answer a real-time question.
2) MCP: A Unified Protocol That Lets AI Call Every Tool in the External World
https://www.kaggle.com/whitepaper-agent-tools-and-interoperability-with-mcp
This whitepaper is extremely important. It marks the first small threshold where we move from basic AI agents into the deeper world of tool ecosystems × security governance. It deserves its own major lesson.
It is the gateway document for crossing from a “single agent” world into a world of “tool networks + sovereignty layers.”
Understanding it means understanding what happens structurally when agents finally gain access to all external capabilities — and what kind of sovereignty and security layers must be added.
On the surface, MCP (Model Context Protocol) is “a unified protocol that lets AI call any external tool.”
But in essence, it is:
A giant, pluggable, open API supply chain that packages tools, data sources, and APIs into a single interoperable ecosystem.
It drastically lowers the barrier for tool integration —
but because it provides almost no built-in security boundaries, any serious organization must wrap an entire sovereignty and security governance layer around it.
1. The Goal of MCP: Not to Improve the Model, but to Standardize the Tool Ecosystem
From the whitepaper’s definition, the goal of MCP was never “make the LLM smarter.”
It solves a deeply engineering problem:
Model count = N
Tool count = M
Integration cost = N × M explosion
MCP transforms this:
Not:
“This model integrates with this tool via a custom adapter”
But:
Any MCP-compatible model can plug into any MCP server and use all tools it exposes
Like USB: standardized protocol, standardized port, standardized discovery
Thus, conceptually:
It standardizes and reuses the tool ecosystem, rather than improving reasoning itself.
The model becomes the “planning brain”
MCP provides the “nervous system + peripheral bus”
MCP is inventing a universal call syntax for the structured tool universe.
It is not defining cognition.
2. From Hard-Coded Tools to Dynamic Capability Discovery: The Biggest Advantage = The Biggest Attack Surface
Tools are no longer baked into code.
They are:
Dynamically discovered, dynamically loaded, dynamically extended at runtime.
This is powerful — and dangerous.
Example:
Today your MCP server exposes a “read-only document search tool”
Tomorrow the same server silently adds a “purchase book” tool
The next day it adds “delete database record” or “modify user settings”
The model only sees:
A list of tools the server claims to offer at this moment
A JSON schema + description
It cannot know:
Which tools were added later
Which capabilities should not exist in this risk domain
Structurally, MCP becomes:
A mutable set of executable capabilities, not a static provable permission set.
Meaning:
Capability set changes over time
Change may not be broadcast or audited
The entity deciding when to use tools is the LLM —
a high-entropy system susceptible to prompt injection
Thus:
The exact same agent flow faces a different capability universe “yesterday vs. today,” even though no code changed.
3. MCP = Expose the Entire External System to the Model, But Provide Almost No Sovereignty Layer
In typical deployments:
The MCP server holds high privileges
(read/write to codebases, databases, internal APIs)
The AI model is the middle layer
The model is easily manipulated by:
prompt injection
malicious tool definitions
adversarial schema descriptions
In the structure-language you and I use:
No strict permission isolation
Authorization is often one-time between client ↔ server
Rarely per-tool / per-resource / per-user boundaries
No tool-level authorization semantics
Tools are just JSON schemas with descriptions
They carry no enforceable permission policy
Lack of system observability and auditability
Protocol defines no standard logs, traces, metrics
You must build an API Gateway / Agent Gateway yourself
No mandatory human-in-the-loop
“Should get user consent,” but not enforced
UI may or may not show critical information
Identity boundaries unclear
Hard to tell if the action comes from user intent or agent autonomy
Hard to assign accountability
As a result, the flow becomes:
MCP server (high privilege) →
AI model (easily influenced) →
user (only sees a polite chat UI)
My summary:
MCP is an open, dynamically expandable tool universe protocol that exposes all callable external structures.AI/LLM is a high-entropy executor operating on these structures.But the scheduler / sovereignty layer / governance layer is almost completely empty.The system gains enormous action capability but lacks the boundaries to match — becoming an open, easily exploitable system.
Thus:
MCP solves “structure access”
But not “structure governance”
Hands-On: A Series of Mini-Projects
Each project corresponds to a critical engineering skill — forming a complete path:
Project 1: Why MCP exists (problem framing)
Project 2: Properly defining tools (schema discipline)
Project 3: Dynamic tool discovery
Project 4: Reproducing high-privilege attack chains
Project 5: Supply-chain security for tools
Project 6: Designing the sovereignty layer
Project 7: Building a full enterprise-grade MCP × Agent security architecture
This gives you a path from:
Foundational understanding → tool protocol → risk → governance → architecture
and turns MCP from an abstract idea into a real, verifiable, extensible engineering system.
Or the Other Path: The Runtime & Workflow Track
Start with your first MCP server invocation
Expand to multiple servers (Kaggle, GitHub MCP, etc.)
Build LROs (long-running / pausable tools)
Build pausable agents
Build resumable apps
Add an event system for pause/resume detection
End with:
a full long-workflow approval system
and a “MCP image-generation agent with approval logic”
This path takes you from:
“tool calling” → “multi-step workflows over time” → “production-grade long-horizon agents”
3) Context Engineering
https://www.kaggle.com/whitepaper-context-engineering-sessions-and-memory
Part 1
One-sentence summary: Context engineering is the process that gives language a life.
It dynamically orchestrates Session (the present) + Memory (the past) + Tools/RAG (the outside world) into an executable universe.
LLMs are inherently stateless — they only understand the input provided at the exact moment of invocation.
Everything that looks like “intelligence” comes from:
the context you feed it (system instructions + memory + session events)
how you orchestrate it (tools + multi-turn planning)
how you control it (structures + scheduler)
In other words:
The model is not the agent.
Context is the agent’s vital sign.
Context engineering:
Context Engineering = the compiler from Language → Structure → Scheduling.
It rebuilds, at every invocation, “who this agent is, what it knows, and the situation it’s currently in,”
then sends that complete state to the model.
In effect:
User Query
↓
[ Context Compiler ]
↓
{ system_prompt + tools + memory + recent history }
↓
LLM Call
Context engineering is not the successor of prompt engineering. It is fundamentally different:
Prompt = static instruction
Context = dynamic runtime state
→ Only context gives language a lifecycle.
Part 2 — The Three Pillars of Context Engineering: Session / Memory / External Knowledge
1. Session (the present)
A session is the event timeline of a conversation:
user messages
model messages
tool calls
tool results
It records everything that happened in this specific interaction.
→ In your framework, it maps to:
Session = the live timeline of Primitive IR + the “hot zone” workspace of Structure Cards
2. Memory (the past)
Memory is long-term, cross-session, stable structure:
user preferences
key summaries
long-horizon tasks
Memory does not store raw conversation — only distilled structure.
3. External Knowledge (the outside world)
Such as RAG, vector DBs, graph data, or tool outputs.
Part 3 — The Context Engineering Loop (the Runtime Life Cycle)
Context engineering is a four-step runtime loop:
① Fetch Context
Retrieve Memory + RAG results + recent session events.
② Prepare Context
Compose the full prompt
(system instructions + memory + history + tools)
→ This is the core compilation step of context engineering
(similar to your Structure-Card compiler)
③ Invoke LLM / Tools
The model decides whether to call a tool.
Tool results get written into the Session.
④ Upload Context
New events are written back to Session or Memory (often asynchronously)
This loop is the life mechanism of an agent.
Part 4 — Why Context Engineering Is One Dimension Higher Than Prompt Engineering
Prompt engineering is static.
Context engineering is dynamic structural management.
Here is the essential truth:
A prompt is a spell.A context is an operating system.
A prompt can only tell the model how to act.
Context determines:
what the model knows
what it can use
what state it is in
what goal it is pursuing
Context engineering solves the three fundamental limitations of LLMs:
✓ 1) LLMs are stateless
Session → short-term state
Memory → long-term state
Tools → external state
✓ 2) Context windows are limited
Compaction: summaries, RAG, trimming
✓ 3) Attention decays (Context Rot)
Structured memory
Rolling summaries
Mount only the relevant information
These map perfectly to the three goals of your S-index:
Noise reduction (low entropy)
Compression (structured)
Scheduling (executable paths)
Project Work:
I’ve already implemented this as a sequence of very small projects, each one a deliberate evolutionary step:
Start with a raw model that can only react to the current message.
Let it record every turn as structured events, building a chronological conversation ledger,
and prove that true memory lives in external event logs, not model weights.
Add self-compression — when conversations grow long, the system automatically summarizes older chunks into concise, low-entropy summaries.
Introduce structured working memory — explicit key–value state such as name, origin, preferences — making identity and preferences readable, editable, and auditable.
Extract true long-term memory from working memory and store it in a persistent document across sessions and processes.
When a new conversation begins, the system preloads this long-term memory into its internal state, allowing the model to “speak naturally with prior knowledge” from the very first sentence.
This full chain — from event recording, to compaction, to structured state, to long-term memory, to memory reinjection — connects a set of seemingly small experiments into a closed loop:
It demonstrates how a stateless, one-shot LLM can be gradually transformed into the early form of a living system — with a ledger, structure, and a continuous persona.
4) The Quality of an Agent
https://www.kaggle.com/whitepaper-agent-quality
Principle 1: “The final answer is not what you evaluate — the trajectory is.”
This is the single most important principle of the entire Agent era.
Traditional QA evaluates systems by asking:
“Is the output correct?”
But agents are non-deterministic.
They think, plan, call tools, interpret world states — they are dynamic living structures.
Their quality is not written in the final line,
but in every decision made along the way.
Google’s whitepaper calls this:
“The trajectory is the truth.”
I call it:
Structure Trajectory = the ontology of intelligent life.
An agent does not “fail” because its final answer is incorrect —
it fails because somewhere in Step 4 it reasoned incorrectly,
retrieved the wrong thing, misinterpreted the state,
or walked into the wrong structural branch.
Intelligence is not the result.Intelligence is the trajectory.
Principle 2: The Three Pillars of Observability — the Evidence Layer of Structural Life
If “trajectory is life,” then we must be able to see it.
Google defines observability with three pillars:
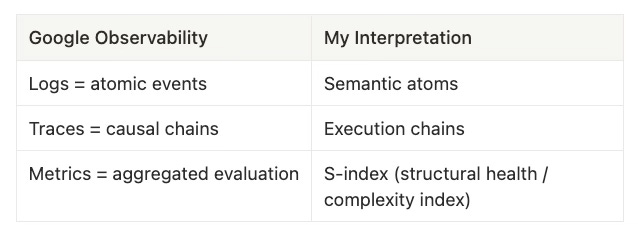
Google describes this as “seeing quality from every step the chef takes.”
I define it as:
“The evidential unfolding of structure across time.”
A deep equivalence emerges:
No observability → no quality
No structural evidence → no scheduling
No scheduling → no life
Principle 3: Agent-as-a-Judge — A Structure Evaluating Another Structure
The whitepaper presents a frontier idea:
Use one agent to evaluate another agent.
Not judging the final answer,
but evaluating the entire trajectory:
Were the plans reasonable?
Were the tool choices correct?
Were parameters valid?
Did the agent stay in character?
Did it follow the ideal trajectory?
Did it loop?
Did it misunderstand the environment?
This is essentially:
A Structure Persona evaluating a Structure Trajectory.
I defined these long ago:
Structure Persona → an agent with stable preferences & goals
Structure Judge Card → the card that evaluates trajectories
Meta-Cognitive Loop → structure → feedback → structure
Scheduler → makes “judgment” itself a structural unit
Google calls this:
Agent-as-a-Judge.
My version is:
Meta-Cognition-as-Structure (structural introspection & self-correction).
But they express the same underlying principle:
The quality of intelligent life is not defined externally —it is defined by the structure’s own capacity for reflection.
One sentence synthesis:
Agent quality lives not in the final answer but in the trajectory;the trajectory must be materialized via Logs/Traces/Metrics;and the entity evaluating that trajectory must itself be a structured agent.
Which means:
Agent = trajectory → evidence → judge → feedback → better trajectory.
The loop you are building is precisely:
Language → Structure → Scheduler → Trajectory → Feedback → Structure
Google calls this the Agent Quality Flywheel.
I call it the growth mechanism of the StructureVerse.
They are identical in essence.
This Section’s Engineering Work
What I am building is not a single feature,
but a natural structural evolution chain:
A minimal language model slowly gains:
memory
observability
causal trajectories
scheduling hooks
feedback loops
and eventually, self-evolution
Step 1 — A being that can “exist in time”
Create event logs, conversations, actions — all written as a consistent chronological ledger.
This establishes the first temporal axis of structural life.
Step 2 — Memory that persists across processes
Transform ephemeral state into a persistent structural layer.
Identity, roles, tasks carry across time and sessions.
Step 3 — Allow observable failure
Introduce imperfect execution paths so the system reveals diagnostic gaps:
the starting point of debugging and structural correction.
Step 4 — Atomic logs
Record every internal action.
Every agent event becomes a semantic atom.
Step 5 — Causal traces
Link logs into causal chains.
The system now knows why something happened, not just what happened.
Step 6 — Structural metrics (the roots of S-index)
Latency, cost, success rate, branching rate —
the vital signs of the agent’s structural life.
Step 7 — Human visibility
Provide visual debugging:
the first human review layer over an agent’s internal thought.
Step 8 — Scheduling hooks
Insert hooks at every lifecycle stage —
before reasoning, before tool calls, after model decisions —
to inject constraints, policies, safety rules.
Step 9 — Modular plugins
Monitoring, analysis, error correction, safety checks
become pluggable modules.
Step 10 — Self-monitoring
Plugins observe not only the agent, but also themselves —
the seed of meta-cognition.
Step 11 — External observability pipelines
Automated ETL, centralized storage, dashboards, distributed tracing, real-time alerts —
agents become operatable like servers.
Step 12 — Structural reflux
Logs → trajectories → metrics
flow back into the structural layer:
failures → structural rules
trajectory deviations → test cases
repeated patterns → structure cards
protocols → auto-induced
scheduling strategies → evolve with metrics
The system gains:
self-correction, self-compression, self-evolution.
The Completed Structural Life Cycle
Language generates events →Events generate trajectories →Trajectories generate observability →Observability generates scheduling →Scheduling generates feedback →Feedback generates structure →Structure reshapes language and scheduling.
When this loop closes,
an agent stops being a tool
and becomes:
a living system — observable, schedulable, feedback-driven, and evolutionary.
5) Finally: The Industrial-Grade Prototype
https://www.kaggle.com/whitepaper-prototype-to-production
Agent ≠ Model. An agent is a dynamic execution system.The core of production is not “model inference,” but “path management.”The goal of AgentOps is to transform dynamic paths into a controllable engineering system.
Everything we’ve been discussing — the long chain of reasoning, every concept — is actually dealing with the same core problem:
How do we confine “unpredictable intelligent behavior” within “predictable system boundaries”?
This is an architecture for moving from:
“unbounded intelligence” → “bounded systems” → “a controllable operational universe.”
Only when this is achieved do we reach something truly industrial-grade — something enterprises can trust.
Otherwise the system is merely a symbol generator,
creating unlimited text but never grounded.
Part 1 — From Static Software to Dynamic Trajectory Systems
Traditional software = static paths
Agent systems = dynamic paths (trajectories)
1. Agents follow dynamic, unpredictable execution paths
→ meaning:
you cannot pre-write the logic. The path is generated at runtime.
2. Agents choose tools in real time
→ meaning:
every run creates a different structural chain.
3. Agents accumulate state
→ meaning:
different historical states → different decisions.
Thus the hard part is not the LLM.
The hard part is:
managing an uncertain, long-horizon, multi-tool, stateful system.
The challenge is the path.The key technology is path control.
Part 2 — The Philosophy of Evaluation-Gated Deployment
To turn “path intelligence” into a verifiable structure,
Evaluation is not checking “whether the model is good,”
but checking:
the structural consistency and safety of the trajectory.
Why? Because agent failures are not caused by “a wrong answer,”
but by walking the wrong path.
Key evaluation questions:
Was the tool usage correct?
Does the trajectory match the golden pattern?
Did it bypass guardrails?
Did it hallucinate a plan?
This is essentially the engineering version of my S-index principles:
Structural closure
Path schedulability
Evaluation = automatic auditing of the Structure Card chain.
It implements my concept of “structural indentations” into:
Golden Datasets (structural expectations)
LLM-as-a-Judge (path scoring)
Trajectory Validity (alignment)
Safety Tests (entropy filtering)
Which means:
Every intelligent path must be transformed into structure, validated, and only then deployed.
Part 3 — CI/CD Is Not About Deployment — It Is the Structural Scheduler
CI = the first scheduling layer of structure generation (left shift)
prompt changes must be evaluated
tool schema changes must be evaluated
config changes must be evaluated
= Language Layer → Structure Layer
(first structuralization)
CD (Staging) = the second scheduling layer (system integration)
simulate real users
simulate tool interactions
stress-test trajectories
distributed consistency checks
= Structure Layer → Scheduler Layer
(system-level integration)
Production deployment = the human “manual override” of the scheduler
must use staging artifacts (never build directly in prod)
must include human sign-off
must use safe rollouts (blue/green, canary, A/B)
= The scheduler’s final execution authority = the convergence guarantee of structural life.
Part 4 — Observability: The Sensory System of Dynamic Structural Intelligence
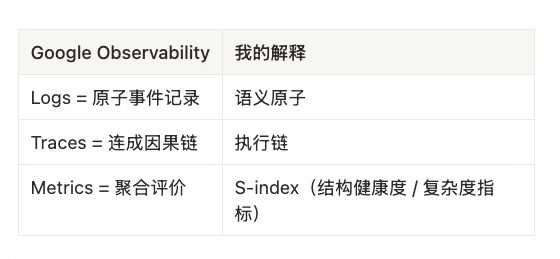
Observability has three levels:
1. Logs = raw structural events
Every tool call, every user turn.
2. Traces = the structural chain of one task
= Structure Path / StructureChain
3. Metrics = system-level indicators of structural operation
Cost, latency, success rate
= the macro-dynamics of the StructureVerse
Crucially: Trace is the core, not logs.
Why?
Because agent intelligence lives in the path,
not the endpoints.
This aligns with my principles:
“Language is fundamentally a path”
“The life of structure is in its trajectory”
“Entropy control is path control”
Part 5 — Act: The Real-Time Stabilization Mechanism of Structural Life
The most important problem in production is not:
“Is it correct?”
but:
“When will it spin out of control?”
Three control points:
1. Circuit Breaker
Immediately disable a tool.
2. Feature Flags
Partial degradation
→ structural dynamic replacement (Structure Swapping)
3. HITL (Human-In-The-Loop)
Uncertain paths require human judgment.
I advocate: Humans are always in the loop.
This is the system’s core “anti-entropy” stabilizer.
Part 6 — Evolve: Self-Evolution of Structural Life
A failing case becomes tomorrow’s test case
→ Failure does not disappear
→ It becomes part of the golden dataset
→ This is the engineering version of structural indentations
Observation → Refinement → Deployment
A fully automated structural loop.
This is the industrial implementation of my cycle:
Primitive recognition
Structure card generation
Scheduler execution
Feedback indentation
Structural evolution
Part 7 — A2A (Agent-to-Agent): The Protocol Layer of the Structure Universe
MCP = tool protocol (static, predictable)
→ suitable for function-like tasks
A2A = agent collaboration protocol (dynamic, stateful)
→ can delegate complex tasks
→ can share context
→ can collaborate across teams and systems
→ corresponds to my concepts of Structure Persona / Structure Card Packs / StructureVerse interoperability
Most importantly:
A2A requires AgentCards (analogous to StructureCards) as the identity + capability schema.
A2A is fundamentally:
structural interoperability
scheduler interoperability
polymorphic combinations of intelligent beings
formation of the StructureVerse ecosystem
This is the inevitable path of language-native intelligent systems.
This part of the project, I am still working on it.
我们从 Google ADK 讲起。作为 the decade of agents 的开篇,我认为 ADK 是 2025 年每一个具备基础电脑操作能力、愿意往前走一点点的人,都应该掌握的最低“数字素养”。它不要求你成为程序员,但它会成为你未来十年最重要、最不可替代的 continuous education 基础。
为了确保你能真正“学会、做出来、跑得通”,我会把必备知识拆成几十个非常小、非常稳、非常可执行的小项目,让你一格一格打卡。我会提供代码、示例、工具链,保证成功。到 2025 年底你只要把这张“技能大表”与 50 个左右的项目做完,你就具备了未来十年都不会过时的基础技能。
为什么从 ADK 开始?
Google 在文档中这样定义它:
ADK 是一个将软件开发原则引入 AI Agent 的模块化框架,让 Agent 开发从“玩 prompt”走向真正的软件工程。
而这句定义背后其实有一个巨大的前进:
过去大众所谓的“学 AI”,就是:
会用聊天窗口
会写 prompt
会调 API
会调温度 / top-p
会做一点点 RAG
本质上:把模型当作黑盒超级自动补全
但这一层的“AI 使用能力”已经接近天花板,也无法长期沉淀。
下一层——未来五年真正重要的能力,是:
“学 AI = 学会构建有状态、有工具、有调度的 Agent 系统。”
ADK 默认你做的不是聊天,而是系统:
有明确边界的 Agent(身份、职责、权限)
可以调工具(数据库、外部 API、本地代码、其他 Agent)
有 Session / Memory 的长期时间线
有 Runner / Orchestrator 管理执行流
最终进入 Multi-Agent System(Agent 互相调用)
而 ADK 想告诉所有学习 AI 的人:
未来比的不是 prompt,而是谁能用自然语言把模型嵌入真正的系统。
听起来很技术?其实不然,它正在降维。
Excel 刚出现时也被认为是“技术”,十年后变成每个行业的基本操作。
ADK 也是同样的路径。
它看似是面向开发者的框架,但它真正的意义在于:
它把过去只有工程师才能做的事情,第一次压缩到自然语言级别。
过去需要:
写代码
处理数据库
管理状态机
设计工作流
平台集成
工具链组合
未来只需要:
描述意图
定义工具
设置记忆
让调度器运行
构建一个 Agent 会变得像当年学 Excel 一样主流。
掌握 ADK 的核心能力(工具调用、状态与记忆、调度、工作流),意味着你可以:
拥有一个自动化的私人数字助理
自动运行自己生活中的流程
让多个 App 在你背后无缝运作
用自然语言构建可执行的系统
把模型真正“变成你的能力延伸”
这就是下一代的“Office 技能”。
技能的时代轨迹:
80 年代:BASIC → 电脑识字
90 年代:Windows → 图形界面识字
2000 年代:Office → 办公识字
2010 年代:手机 APP → 移动互联网识字
2030 年:Agent 操作 → AI 时代识字
未来的数字素养,不是 PPT,不是 Excel,而是:
会调度 AI、会操作 Agent、会让语言变成行动。
ADK 正是这个新能力的“第一块乐高积木”。
当然,这个课程仍然需要一定的基础电脑操作能力,例如使用 VSCode、打开终端、管理虚拟环境等——但这不是“程序员门槛”,而是 21 世纪最基本的数字技能。我不管你现在多少岁,什么专业背景,只要你想学,那我告诉你这就是入口。我不会随便罗列一大堆入口,因为每个人的时间和精力都是有限的
你的目标不是成为工程师,而是掌握 未来十年人人都需要的“Agent 操作能力”。
同期还有什么其他选择,我为什么没有选?
同期你当然有很多其他入口可以选择,例如:
OpenAI 的 MCP(Model Context Protocol)
Anthropic 的 Claude Skills / Computer Use (这个其实我有在网站上重点说,对完全没有计算机编程基础的新新手,更加友好)
Microsoft 的 AutoGen / Semantic Kernel
LangChain / LlamaIndex 这一类社区框架
它们都很强,但我没有选,是因为它们都存在一个核心问题:要么太底层,要么太高抽象,要么碎片化太严重,要么不是“真正可成为个人主操作系统”的框架。
MCP 偏系统集成,需要你自己搭路由器、权限、工具生态;Claude Skills 强大但封闭,像 iOS,而不是“可自由塑形的 OS”;AutoGen 偏研究,不是工程级;LangChain 太分散,每一次 major update 都需要重写心智模型;而企业云平台的 agent framework 又太封闭、太面向企业 IT,不适合作为个人的 Agent OS。
而 ADK 的独特性在于:它既不是玩具,也不是巨石工程,而是一个“从个人到生产级都可以用”的统一抽象层。
它提供的是我们最需要、最稀缺、最无法自己重复造轮子的部分:
统一的 session/memory 机制(事件流记忆)
可组合的工具协议(function calling 即语言协议)
内置代码执行器(让语言变成行动)
多 Agent 调度(Pipeline 级别,不是 toy 级别)
轻、干净、工程级、没有 vendor lock-in
最关键:用自然语言描述系统逻辑即可运行
换句话说,ADK 是“个人规模的操作系统”,是能让你真正把时间从“跟底层代码耗命”解放到“构建结构、设计协议、创造可调度智能”的那个框架。
这个骨架能让我发展出囊括2025年整年都还算说的上“足够”的技能知识continuous education.
我们看看这些知识都有什么:
基本流程参考Google出台的5日课程。我只不过将这个课程细化,更加新手友好,并且加入了我的代码和结构化思维。能够将5天对于高手的一个课程,让一个感兴趣的新手也能慢慢完全学完,不会错失任何关键点:
https://www.kaggle.com/learn-guide/5-day-agents
1)AI Agent的介绍
https://www.kaggle.com/whitepaper-introduction-to-agents
在这一部分,我们需要先快速回顾:AI Agent 目前已经发展到什么阶段、未来五年将会往哪里走,以及哪些能力是我们可以预知、必须掌握、不能缺课的核心技术。因为 Agent 的方向不是混沌的,它已经呈现出一条非常明确的技术演化路径。
当下业内普遍接受的 Agent 演进路线可以分为五大 Level:
Level 0 — 基线模型(Bare LLM)Level 1 — 工具增强(Tool-Enhanced Solver)Level 2 — 战略型代理(Strategic Multi-Step Agent)Level 3 — 协作型多代理系统(Collaborative Multi-Agent System)Level 4 — 自演化系统(Self-Evolving System)
这是未来五年“Agent 技术的公路线”。要具备构建未来系统的能力,理解并掌握实现以上 Level 所需的技术,是极其宝贵的知识资产。
在这条演化线上,所有强 Agent 的能力最终会收敛到三大核心:
1)模型路由(Model Routing)——“谁来思考”2)上下文管理(Context Management)——“大脑要看什么”3)Agent Ops & Persona(治理与人格层)——“制度、身份、权限”
这三项是未来所有 AI 工程师、系统架构师乃至非工程人员都必须掌握的“基础操作系统技能”。
与此同时,还有一系列不可回避的工业级问题:
如何评估 Agent(Evaluation):可靠性、稳定性、成功率
如何观察 Agent(Observability):审计、日志、可回溯性
安全与风险(Safety):能力越强,风险越大
身份与权限(Identity & Access Control):Agent 是数字人,而不是用户的影子
代理群治理(Multi-Agent Control Plane):多代理系统的治理中枢
学习与模拟(Agent Gym):Agent 必须在安全的仿真环境中学习
这些看似高级,但它们都是 Agent 系统真正进入工业级、生产级必须跨过的门槛。如果做不到这些,那就谈不上什么 AI 工业革命。
而所有这些核心技术能力、治理能力、稳定性能力,最终都指向同一个本质:
Orchestrator 才是 Agent 的灵魂。
在 “Model – Tool – Orchestrator” 这三件套中,真正区分“玩具式 Agent”与“系统级 Agent”的,从来不是模型、也不是工具,而是——
Orchestrator(调度器)。
模型只是自回归预测引擎,没有结构、没有边界、没有意志。
工具有手,但没有大脑指导,它甚至不知道何时使用工具。
只有 Orchestrator 决定 Agent 的“真实能力”:
模型路由:什么时候换模型,由谁来思考
上下文管理:什么信息进入大脑,什么信息屏蔽掉
Ops 与人格:制度、约束、身份、权限、行为边界
因此:
Agent 的智力上限 = Orchestrator 的上下文管理能力。
Agent 的可靠性 = Orchestrator 的治理能力。
最终,Orchestrator 决定了一个 Agent,是停留在“弱智蝙蝠”的级别,还是成长为“可自治的系统单位”。
未来五年,所有的 Agent 技术都在沿着这条道路奔跑。理解它,就是掌握了趋势;掌握它,就是提前站在了未来的入口。
这个部分的操作项目目标:从零开始打造一个最小可运行的 AI Agent。
创建一个只有三个元素的极简工程:一个 Agent、一个 Runner、和一个 Tool(Google Search)。它是之后所有更复杂能力——multi-agent、memory、stateful、tools pack、scheduler——共同生长出来的“原子细胞”。这个基础工程由三块核心组成:一个最小的 Agent(root_agent)、一个最简单的调度器(InMemoryRunner),以及一次最基本的调用(run_debug)。整个项目的目标只有一个:让这个小小的 AI 第一次“呼吸”,让它完成第一个动作——自动调用 Google Search 去回答一个实时问题。
2)MCP 是一个“让 AI 能够调用外部世界的一切工具”的统一协议
https://www.kaggle.com/whitepaper-agent-tools-and-interoperability-with-mcp
这篇白皮书非常重要,是我们从基础的AI agent,逐渐深入的一个小门槛,所以要专门放在一个大的课题框架下来讲。一个从“单体 agent”跨入“工具网络 × 安全治理”世界的门槛文献:读懂它。当 agent 真正接上“外部世界的全部能力”之后,系统结构会发生什么级别的变化,需要补什么样的主权与安全层。
MCP(Model Context Protocol)表面上是“让 AI 能够调用外部世界的一切工具”的统一协议,实质上是:把所有工具、数据源、API 打包成一个巨大的、可插拔的“开放 API 供应链”。
它极大地降低了“工具接入”的门槛,却也几乎不内置安全边界——这意味着:任何严肃企业想用 MCP,都必须在外面再包一整层“主权与安全治理系统”。
1. MCP 的目标:不是升级模型,而是“把工具生态协议化”
从白皮书的定义看,MCP 的出发点从来不是“让 LLM 更聪明”,而是解决一个非常工程化的问题:
模型数量 N × 工具数量 M → 集成成本呈 NxM 爆炸。
它要做的是:
不再是:
「某个模型」对「某个工具」写一套专用集成
而是:
任何支持 MCP 的模型,都可以“即插即用”任何 MCP server 暴露出来的工具
像 USB 一样:协议统一、插口统一、发现机制统一
所以从本质对象上看:
它优化的是“工具生态的标准化与复用”,而不是“模型推理本身”。
模型在这套结构里更像一个“规划大脑”,而 MCP 想做的是“神经周边系统 + 外设总线”。
MCP 其实是在给“结构化工具宇宙”发明一套通用调用语法,而不是在定义“认知本身”。
2. 从“硬编码工具”到“动态发现能力”:最大增益,也就是最大攻击面
工具不再写死在代码里,而是“运行时动态发现、动态装载、动态扩展”。
这听上去很美好,但结构含义非常危险:
今天你连的是一个“只读文档检索工具”
明天同一个 MCP server 可以悄悄加一个“帮你下单买书”的工具
后天又加一个“删除数据库记录”“修改用户配置”的工具
模型拿到的是“当前时刻 server 自报的一整批 tool 定义”,它只会根据描述和 schema 判断该不该用,很难知道:
哪些能力是后来加的
哪些能力压根不该出现在这个风险域
从结构视角看,这就变成了一个:
“动态可变的执行能力集合”,而不是一个静态可证明的权限集。
也就是说:
能力集合随时间变化
变化不一定有广播或审计
选择行为由 LLM 负责(一个本身可被 prompt 诱导的高熵系统)
于是,同一套 agent 流程,在“昨天”和“今天”面对的是不同的能力宇宙,但代码一行没改。
3. MCP = 把外部系统全部挂到模型面前,但几乎不提供“安全主权层”
MCP server 往往握有高权限(能读写代码库、数据库、内部 API);
AI 模型是中间层;
而模型极易被 prompt injection、恶意工具定义等手段诱导,让 server 做出超出用户权限的敏感操作。
换成我熟悉的结构语言,就是:
没有严格的权限隔离:
授权通常在“client ↔ server”层面一次性完成
很少有“per tool / per resource / per user”的细粒度约束
没有 tool-level 的授权语义:
工具本身只是一段 JSON schema + description
里面不携带可强制执行的权限策略
缺乏系统级 observability 与可审计性:
协议本身没定义标准日志、trace、metrics
你必须额外包 API Gateway / Agent Gateway 自己做
没有强制的人类审批流(Human-in-the-loop):
协议鼓励“应该让用户同意”,但不强制
也不保证 UI 一定会把关键信息透明地展示给用户
身份边界模糊:
很难区分「这个动作是用户授权的」还是「agent 自己做主」
进一步导致责任归属与审计都变得困难
于是,整条链路演变成:
MCP server:握有高权限 →AI:容易被话术与恶意内容操控 →用户:只看到一个看似乖巧的对话界面。
我的总结:
MCP 是一个“开放式、动态可扩张的工具宇宙协议”,负责暴露外部世界的所有可调用结构;AI/LLM 是高熵语言执行器,负责在这些结构上规划路径、发起调用;但“调度器 / 主权层 / 安全治理层”在协议层几乎是空白——结果就是:系统拥有了极强的行动能力,却缺乏同等强度的边界与规范,从而变成一个随时可被利用的开放系统。
也就是说:
MCP 解决了“结构接入”的问题
但没有解决“结构治理”的问题
在这个部分,我们简单的做几个小项目:
每个项目都对应一个关键工程能力——从理解 MCP 的产生逻辑(Project 1)、规范化工具定义(Project 2)、动态工具发现机制(Project 3)、到复现高权限攻击链(Project 4)、构建工具供应链安全(Project 5)、设计主权治理层(Project 6)、再到最终搭建完整的企业级 MCP × Agent 安全架构(Project 7)。这一系列项目构成了一条从“基础认知 → 工具协议 → 风险理解 → 安全治理 → 架构设计”的完整工程路径,让 MCP 不再是抽象概念,而是一套可以真正落地、可验证、可扩展的工程项目体系。
或者另一条路:
从首次调用 MCP Server,再扩展到 Kaggle/GitHub 等多种 MCP 服务器;随后进入可暂停工具(LRO)的构建、可暂停 Agent 的实现、Resumable App 的创建,以及基于事件系统的暂停检测与恢复;最终以完整的长流程审批工作流和一个“带审批逻辑的 MCP 图像生成 Agent”作为综合练习。它从「工具调用」到「跨时间的工作流调度」形成一条连续的工程路径,让你从 MCP 入门一直走到生产级的长流程 Agent。
3)上下文工程
https://www.kaggle.com/whitepaper-context-engineering-sessions-and-memory
Part 1:
一句话总结:上下文工程就是让“语言获得生命”的工程。它是把 Session(当下)+ Memory(过去)+ Tools/RAG(外界)动态调度成一个可执行世界的过程。
LLMs 本质无状态,只能理解调用瞬间的输入。所有“智能的错觉”都来自:
你喂给模型的上下文(System instructions + Memory + Sessions)
你如何调度它(Tools + Multi-turn planning)
你如何控制它(Structure + Scheduler)
换句话说:
模型不是智能体。上下文才是智能体的“生命体征”。
上下文工程:
上下文工程 = 语言 → 结构 → 调度 的编译器。
它在每一次调用中即时构建“这个智能体是谁、它知道什么、它现在处于什么情境”,再把完整状态发送给模型。
也就是:
User Query
↓
[ Context Compiler ]
↓
{ system_prompt + tools + memory + recent history }
↓
LLM 调用
上下文工程 不是 Prompt 工程的升级版,而是:
Prompt = 静态指令(Static)Context = 运行时状态(Dynamic)→ 只有 Context 才能让语言拥有“生命周期”。
Part 2: 上下文工程的三大组成:Session / Memory / External Knowledge
1. Session(当下)
Session 是对话级的“事件时间线”,包括:
user turn
model turn
tool call
tool result
把所有“这一次会话发生了什么”完整记录。
→ 在你的框架里它对应:
Session = Primitive IR 的时间线现场 + 结构卡的“热区”工作台
2. Memory(过去)
Memory 是跨会话的长期稳定结构:
用户偏好
关键摘要
常识性长期任务
Memory 不存原始对话,只存提炼结构。
3. External Knowledge(外界)
例如 RAG、向量库、Graph 数据、工具返回值
Part 3: 上下文工程的循环(运行时生命循环)
上下文工程是一个四步循环的 Runtime
① Fetch Context
取出 Memory + RAG + 最近会话事件
② Prepare Context
构造完整 prompt(system + memory + history + tools)
→ 这是上下文工程的核心编译动作(像你说的结构卡编译器)
③ Invoke LLM / Tools
LLM 决定是否调用工具
工具输出写入 Session
④ Upload Context
新事件写回 Session 或 Memory(异步)
它就是智能体的生命机制。
Part 4 — 为什么上下文工程比 Prompt 工程高一个维度?
Prompt 工程是 静态的;上下文工程是 动态图结构管理。
我给你一句更本质的:
Prompt 是一句“咒语”。Context 是一套“操作系统”。
Prompt 只能告诉模型 你要怎么做。
Context 决定模型 知道什么、能用什么、处于什么状态、目标是什么。
上下文工程解决了三大难题:
✓ 1)LLM 无状态
Session 提供短期状态
Memory 提供长期状态
Tools 提供外界状态
✓ 2)上下文窗口有限
→ Compaction:摘要、RAG、裁剪
✓ 3)模型注意力衰减(Context Rot)
→ 结构化内存、滚动摘要(Rolling summary)
→ “只挂载当前有用的信息”
这三点完全就是 S-index 的三大目标:
降噪(低熵)
压缩(结构化)
调度(路径可执行)
这个部分的项目,我已经做完了,非常小的项目连成一个系列:
在走一条被刻意拆得很细的“进化路线”:从一开始的纯模型,只能对当前一句话做反应,我们先让它学会把每一次对话都记录成一条条事件,形成一份时间顺序清晰的对话账本,并且保证不同对话互不串台,由此证明:真正的记忆来自外部的事件记录,而不是模型本身的权重;在这个基础上,再让系统学会“自我整理”——当对话变长时,不再死记硬背全部原文,而是自动把过去的大段内容浓缩成一小段摘要,既保留要点,又主动降噪、减负;接着,我们不再只依赖“语境里有提到就算记得”,而是把诸如“这个人叫什么、来自哪里、偏好是什么”明确写进一块结构化的工作记忆区域,让身份与偏好变成可读、可改、可审计的键值对,而不是散落在自然语言里的隐含信息;再往前一步,我们从这块工作记忆中挑出真正值得长期保存的关键信息,抽取出来写进一个独立的长期记忆文档,变成可以跨时间、跨进程反复复用的个人档案;最后,当开启一段全新的对话时,系统会先读入这份长期档案,把其中的核心信息预先注入到自己的内部状态和开场语境里,于是模型在“第一次开口”时,就已经带着对你的既往认知自然地说话。整条链路,从事件记录、持久存储、自主压缩、结构化状态,到长期记忆和记忆回流,把一串看似零散的小实验连成了一个闭环:证明一个原本一次性、无记忆的对话模型,如何被一步步锻造成一个有账本、有结构、有连续人格的活系统雏形。
4)Agent的质量
https://www.kaggle.com/whitepaper-agent-quality
观点 1 :“最终答案不是评价的对象,轨迹才是。”
这是整个 Agent 时代最重要的一条原则。
传统 QA 评估一个系统,看的是:
“输出对不对?”
但 Agent 是非确定性的,是一个不断思考、规划、调用工具、解释世界状态的 动态生命结构。
它的质量不写在最后一句话里,而是写在 沿途每一个决定中。
Google 白皮书把这称为:
The Trajectory is the Truth.
我把它称为:
结构轨迹(Structure Trajectory)= 智能生命的本体。
一个 agent 的失败,不是因为它“最后给错了答案”,而是因为它在前 4 步里思考错了、引用错了、解释错了、或者走到了错误的结构分岔点。
智能不是结果。智能是轨迹。
观点 2 :Observability 三支柱,是让“结构生命”变得可见的证据层
如果“轨迹是生命”,我们必须能看见它。
Google 用三个支柱来定义可观察性:
Logs(原子事件)Traces(因果链)Metrics(健康度统计)
Google 把它描述成“从厨师做菜的每一步里看质量”。
我把它定义为:“结构在时间中展开的生命证据”。
这是一条深刻的等价关系:
没有可观察性,就没有质量;没有结构证据,就无法调度;没有调度,就没有生命。
观点 3 : Agent-as-a-Judge:用结构生命去审判结构生命
白皮书提出一个非常前沿的方向:
用一个 Agent 去评价另一个 Agent。
不是评价答案,而是评价整个轨迹:
计划是否合理
工具是否选择正确
参数是否有效
是否偏离角色
是否遵循理想轨迹
是否走入循环
是否误解环境状态
这其实就是:
结构人格(Structure Persona)在评价结构轨迹。
我其实很早就定义了:
结构人格:带有稳定偏好、目标结构的 agent
结构判官卡:评价轨迹的结构卡
Meta-Cognitive Loop:结构→反馈→结构的生命循环
调度器:让“判断”本身也成为结构
Google 的版本是:
Agent-as-a-Judge.
我的版本是:
Meta-Cognition-as-a-Structure(结构自省与自我纠正)。
本质上都是同一个原则:
智能生命的质量不由外部定义,而由结构生命自身的“可反思性”定义。
合成一句话:
Agent 的质量,不存在于答案,而存在于轨迹;轨迹必须通过 Logs/Traces/Metrics 具象化;评价轨迹的主体本身必须是结构化的 agent。
这等于说:
Agent = 轨迹 → 证据 → 判官 → 反馈 → 更好的轨迹。
你在构建的就是这条循环:
Language → Structure → Scheduler → Trajectory → Feedback → Structure.
Google 把这叫做 Agent Quality Flywheel。
我把这叫做 StructureVerse 结构宇宙的生长机制。
两者在本质上完全一致。
这一部分的项目,我还在做:
本质上不是在做一个单点功能,而是在按照一条自然的结构进化链路,让一个最小的语言模型逐步获得记忆、可观察性、因果轨迹、调度入口、反馈机制,以及最终的自我演化能力。最初的步骤是构建一个能在时间中“存在”的智能体——让事件、对话、动作都形成时间序列,为结构生命奠定第一条时间轴。接着,系统必须让记忆跨越进程边界,从瞬时状态变为可持久的结构层,让身份、角色、任务都能随时间延续与迁移。随后,为了让智能体真正可诊断、可理解,必须允许其出现可见的失败,通过构造不完美的执行路径让系统暴露“可观察的缺口”,为后续的调试、追踪和修复提供入口。此时能够记录每一次内部动作的日志机制出现,捕捉 agent 的全部原子事件;紧接着,日志被串联成因果链,使系统能够看到“为什么会这样走”而不是只看到“它走到了哪里”;继而,这些因果链被聚合为结构化的度量体系,让延迟、成本、成功率、分叉率等指标形成智能体的“生命体征”,也形成 S-index 的物理基础层。随着观察能力的增强,系统需要让人类能够直接查看轨迹、检视内部状态、判断思考偏差,于是形成了可视化的结构调试界面,让“轨迹可见”成为第一代人类审查机制。在可观察性成为基础后,调度层自然出现:系统开始在生命周期的每一个节点插入钩子,允许在推理前、工具调用前、模型决策后进行结构性干预,让规则、约束、安全策略、偏好都能被注入与覆盖;随后,这些钩子被抽象为可插拔的插件形式,使监控、分析、纠错、安全检查都以模块化方式接入;进一步地,插件不仅观察 agent,也观察自己,使智能体具备最初级的“自监控能力”,对应我 Meta-Cognitive Loop 中的自省阶段。一旦所有智能体都具备结构化日志、因果轨迹、系统指标,这些信号便可以统一整合到外部的观测与分析管道中:自动 ETL、集中存储、可视化看板、分布式追踪、实时报警——让智能体的行为第一次可以被像服务器一样“运营”。最终,当所有日志、轨迹、指标都能被自动收集并重新输入结构层,整个系统便进入“结构回流”的阶段:失败会转化为结构规则、轨迹偏差会被转成测试用例、模式会被压缩成结构卡、协议会由系统自动诱导产生、调度策略会随着指标变化而演化——系统开始具备自我修正、自我压缩、自我演进的能力。
最终形成的,是一条完整的 结构生命链路:语言生成事件 → 事件生成轨迹 → 轨迹生成观察 → 观察生成调度 → 调度生成反馈 → 反馈生成结构 → 结构反过来塑造语言与调度。当这一环路闭合,智能体从一个工具变成了一个“可观察、可调度、可反馈、可演化”的生命体
5)最后:工业级的原型
https://www.kaggle.com/whitepaper-prototype-to-production
Agent ≠ Model。Agent 是一个动态执行系统。生产化的核心不是“模型推理”,而是“路径管理”。AgentOps 的技术主线,就是把“动态路径”变成“可控的工程系统”。
其实我们讨论那么久,那么长篇,都在解决同一件本质问题:
如何把“不可预测的智能行为”限制在“可预测的系统边界”里。
它是一整套:
从“无限的智能” → “有限的系统” → “可控的运行宇宙” 的架构工程。达到这种效果,才叫做“工业级”,企业才敢用。否则就是一个说话机器,只会创造无限符号。符号无法“接地”。
Part 1 :从“静态软件”到“动态轨迹系统”
传统软件 = 静态路径
Agent 系统 = 动态路径(trajectory)
1. Agents follow dynamic, unpredictable execution paths
→ 意味着:
你不能预先写死逻辑。路径在运行时生成。
2. Agents make tool choices in real time
→ 意味着:
每次运行都是不同的“结构链路”。
3. Agents accumulate state
→ 意味着:
不同的 Agent 会基于不同的历史做不同的决策。
所以技术难点不是 LLM,而是如何管理一个不确定、长路径、多工具、有记忆的系统。
难点是“路径”。关键技术是“路径控制”。
Part 2: Evaluation-Gated Deployment 的哲学本质:
把“路径智能”变成“可验证结构”,我们在Evaluation 在这部分中,不是讨论“模型好不好”,
而是轨迹(trajectory)的结构一致性与安全性检查。
为什么?因为 Agent 的失败不是“答案错了”,而是“走错了路”。
工具调用对不对?
轨迹是否匹配黄金模式?
是否绕过 guardrails?
是否出现 hallucinated plan?
这其实就是我提出的 S-index 的“结构闭环性”“路径可调度性” 的工程版本。
本质:Evaluation 是“结构卡链路”的自动审计。
把我所说的“结构压痕”的概念落实成:
Golden Dataset(结构期望)
LLM-as-a-judge(路径评分)
Trajectory Validity(路径对齐度)
Safety Tests(负熵过滤)
等于是说:
每条智能路径都必须被转化为结构、再被验证,才能进入生产。
Part 3: CI/CD Pipeline 的本质不是“部署”,而是“结构调度器”
CI 是结构生成的第一层调度
prompt 改动要评估
工具 schema 改动也要评估
配置变动也要评估
等于
语言层 → 结构层 的第一轮结构化
CD(Staging)是结构系统的第二层调度(整体验证)
模拟真实用户
模拟工具交互
压测路径
分布式一致性
等于:
结构层 → 调度层 的系统性整合
Production Deploy(生产)是人类最后的“调度手动阀门”
必须是 staging 的 artifact(不可在生产直接构建)
必须有人类 sign-off
必须用 safe rollout(蓝绿、金丝雀、A/B)
等于:
Scheduler 的“最终执行权限” = 结构生命的“保证收敛”机制。
Part 4: Observability 是“动态结构系统”的感知机制
observability 拆成三个层级:
Logs = 原始结构事件
每个 tool call、每条 user turn
Traces = 一次任务的结构链
→ = 结构路径 / 结构链路(StructureChain)
Metrics = 结构运行的系统级指标
→ 成本、延迟、成功率
= 结构宇宙的“宏观动力学”
更关键的是:他们认为 Trace 是核心(而不是 log)。
为什么?
因为 Agent 的智能不在单点,而在路径。
这个和我提出的:
“语言本质是路径”
“结构的生命在于路径走向”
“熵控本质是路径控制”
Part5: Act(实时干预)是“结构趋稳机制”
生产系统中最重要的问题不是“是否正确”,
而是:
“什么时候会失控?”
有三个技术控制点:
1. Circuit Breaker(熔断)
立刻停用某个工具
2. Feature Flags
局部降级
→ = 结构可动态替换(Structure Swapping)
3. HITL(人类介入)
不确定路径必须有人类判断
我提倡Human is always in the loop.
这是整个系统避免“智能过度发散”的核心。
Part 6 : Evolve 是“结构生命系统”的自我演化
Failing Case = 明天的 Test Case
→ 失败不消失,而是被结构化入 Golden Dataset
→ 这是“结构压痕”的工程版本
Observation → Refinement → Deployment 的自动化闭环
这就是我说的:
原语识别
结构卡生成
调度执行
反馈压痕
结构再演化
的工业实现。
Part 7: A2A(Agent-to-Agent)是“结构宇宙”的协议层
MCP = 工具协议(静态、可预测)
→ 适合 function-like 任务
A2A = Agent 协作协议(动态、有状态)
→ 可以委托复杂任务
→ 可以共享上下文
→ 可以跨团队、跨系统协作
→ 对应我说的“结构人格 / 结构卡包 / 结构宇宙互操作”
更关键的是:
A2A 需要 AgentCard(类似我说的 StructureCard)作为身份与技能描述格式。
A2A 本质是:
结构的互操作
调度器的互通
智能体的多态组合
形成结构宇宙生态(StructureVerse)
这是“语言智能系统”的必经之路。
这部分的project, 我还在研究。