
Universality: Language, LLMs, and the Power of One Primitive
How token prediction turns language into a universal machine for meaning

Why can one model write poetry, translate contracts, solve math problems, and answer questions—all with the same underlying mechanism? At first glance, it feels like a strange kind of magic, as if one machine were juggling entirely different talents without breaking a sweat. In the old world of NLP, each of these skills required its own model, its own training set, and its own architecture. A translation system could not summarize; a sentiment classifier could not solve equations. The field was fractured, with no common ground.
Large language models changed that. What looks like a patchwork of capabilities is, under the hood, just one universal act: predicting the next token. The model doesn’t know in advance whether it is writing a sonnet, balancing an equation, or producing a legal clause. It simply continues a symbolic sequence, one token at a time, guided by probabilities learned from vast amounts of text. Out of this simple act of continuation emerges an astonishing spectrum of behaviors.
This primitive doesn’t just unify tasks; it reframes language itself. Once you reduce everything to token prediction, language becomes more than communication—it becomes a machine for meaning. Every continuation is a micro-decision in a vast symbolic universe. Poetry, law, science, and conversation all become variations of the same process: shaping meaning by predicting what comes next.
Before Universality: Fragmented Language Tools
To appreciate what large language models have changed, it helps to recall what came before. For most of its history, natural language processing was a field of ingenious but isolated contraptions, each built for a narrow purpose.
If you wanted translation, you built a statistical machine translation system, trained on carefully aligned bilingual corpora. If you wanted sentiment analysis, you trained a classifier to label sentences as positive or negative. If you wanted summarization, you designed yet another system, often based on sentence extraction or hand-crafted linguistic rules. Question answering had its own architectures, as did chatbots, topic models, and speech recognition. Each task was a silo.
Like the early world of calculating devices—abaci, adding machines, difference engines—these tools were powerful in their own ways, but narrow. A machine that could tabulate polynomials could not compute logarithms. Likewise, a model trained to detect sentiment could not translate, and a translation system could not hold a conversation. Each function had to be engineered from scratch, with specialized data pipelines, algorithms, and evaluation metrics.
This fragmentation had two consequences. First, progress was local. A breakthrough in summarization did little to advance translation. Each subfield advanced along its own track, often reinventing methods or features that had already been discovered elsewhere. Second, there was no shared substrate of meaning. Each system had its own representation of language—n-grams here, parse trees there, embeddings in another corner. There was no common ground where “meaning” could be modeled universally.
In this world, language technology looked like a collection of specialized islands. You could visit one island to translate, another to summarize, another to classify, but there was no single vessel that could carry you across all of them. Each island was impressive, but the seas between them were wide and treacherous.
This was the pre-universality era of language: a machine zoo of narrow models, each ingenious, but none capable of generalizing beyond its assigned task. Just as mechanical calculators once defined the limits of computation, these fragmented tools defined the limits of NLP. What was missing was the unifying leap—a discovery of a minimal primitive and a universal substrate that could collapse the islands into a single continent.
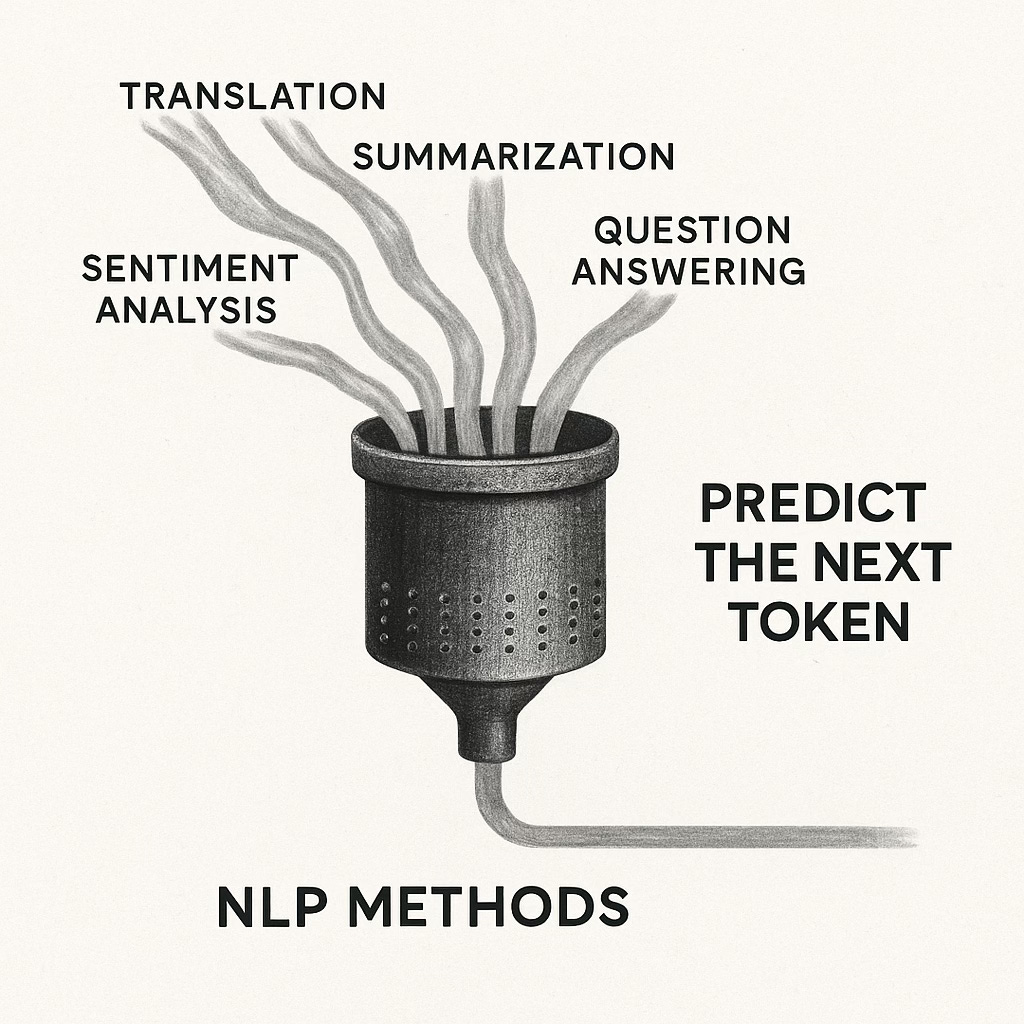
The Primitive: Predict the Next Token
The breakthrough of large language models is almost embarrassingly simple. Instead of designing a new system for each linguistic task, researchers discovered that every task could be reframed as a single act: predicting the next token.
At first glance, this looks mechanical, almost trivial. A token might be a word, a subword, or even a character. The model scans the sequence so far and estimates: what is the most likely token to come next? Then it does it again. And again. Out of this looping act—predict, append, predict, append—emerges translation, summarization, reasoning, even poetry.
Why does this matter? Because token prediction is not just a technical trick. It is a way of navigating the symbolic spaceof human language. Every token carries multiple potential futures. After the word “bank,” should the continuation lean toward “account” or “river”? After the phrase “once upon a,” should it predict “time” or something deliberately subversive? Each prediction is a micro-choice among symbolic continuations, a decision about which thread of meaning to pull forward.
Seen this way, token prediction is not a reduction of language but a re-framing of it. It treats language as a probabilistic universe of possible meanings. The model doesn’t just string words together; it operates inside a generative semantic field, where every step both constrains and opens up meaning. The richness comes not from the mechanism itself, but from the fact that language is vast, structured, and endlessly recombinable.
This single primitive therefore collapses the fractured task zoo of old NLP. Translation? Just continue a sequence where the prompt specifies another language. Summarization? Continue with a shorter re-expression of the input. Reasoning? Continue with the logical steps that have appeared across millions of examples. The surface diversity of tasks dissolves into the same underlying process: predicting the next token in a symbolic universe.
It is exactly the kind of universality we saw with Turing. Just as four primitive actions (read, write, move, state transition) could simulate all computation, one primitive (token prediction) can simulate the full diversity of linguistic tasks. Out of minimal primitives, infinite behaviors emerge.
Prompt = Program, Corpus = Meaning Tape
If token prediction is the primitive, then prompts and training data are what turn it into something useful. In practice, a prompt functions like a program: it tells the model what task to perform, what frame of meaning to inhabit, and what kind of continuation to prioritize. A short instruction—“Translate this into French”—shifts the model into one symbolic trajectory. A different instruction—“Summarize this contract in plain English”—sends it down another. The model doesn’t change; only the program it is given does.
The training corpus provides the other half of the equation. This vast body of text is effectively a universal tape, not unlike Turing’s imaginary strip of symbols. But instead of being a single set of instructions, it is a compressed record of human symbolic history: literature, laws, scientific papers, technical manuals, casual conversations. All of it is encoded as tokens, which the model has learned to navigate probabilistically.
Together, the prompt and the corpus let the model recombine meaning across domains. Ask it to analyze a legal argument, and it draws on centuries of legal language. Ask it to write a sonnet, and it pulls patterns from the poetic canon. Ask it to solve a physics problem, and it leans on symbolic traces of scientific reasoning. The model doesn’t “know” these fields as a human specialist does; instead, it inhabits the shared symbolic space in which they all exist.
This is where the analogy to the Universal Turing Machine becomes sharp. In Turing’s model, the machine itself never changed; the diversity came from the descriptions written on its tape. With LLMs, the primitive never changes; the diversity comes from prompts written into the model’s input and from the corpus encoded in its weights. Prompts are how we “program” the machine for meaning, and the corpus is the universal tape from which it draws its symbolic continuations.
What emerges is a new kind of universality: one model, one primitive, but infinitely many programs, limited only by what humans can express in symbolic form.
It has been an imitation machine, and it still is.
The Boundary of the Modelable
Every universality is also a boundary. When Turing defined the Universal Machine, he didn’t just show what could be computed—he also defined what could not. Functions that could not be reduced to stepwise instructions on a tape were outside the realm of computation. Universality is not infinite; it is a horizon.
Large language models work the same way. Their primitive is token prediction. That means their universality extends only as far as things can be represented in tokens—what can be expressed in symbols. A legal contract? Yes. A poem? Certainly. A mathematical proof? With varying success. But what about the sensation of tasting mango for the first time, or the silent intuition of a chess grandmaster, or the tacit feel of friendship? Unless those experiences can be symbolized—translated into language—they resist being modeled.
This is the crucial distinction: LLMs collapse all symbolic tasks into “continuations of meaning,” but embodied experience, tacit knowledge, and non-symbolic intuition mark the edge. The model can imitate how humans talkabout those experiences, but it cannot directly access or generate the experiences themselves. It can simulate the language of a sommelier describing wine, but it does not taste. It can reproduce the metaphors of mysticism, but it does not stand in awe.
And yet, this boundary is not static. Human culture itself is an endless project of turning the inexpressible into symbols—art, mathematics, law, science are all attempts to encode the non-symbolic into communicable form. Each time we succeed, we expand the range of what is language-modelable.
This is why token prediction is more than a technical trick. It defines a frontier. On one side lies everything that can be symbolized and recombined by the model. On the other side lies everything still resistant to symbolization. The frontier is where the work is.
The universality of language models is therefore not the end of the story, but the beginning of a new question: how far can we stretch the symbolic universe before it breaks?
The breakthroughs of the future will not lie in the models themselves, but in whether we humans dare to push this symbolic universe to its limits.
Toward the Edges of the Symbolic Universe
If token prediction is the primitive, and prompts are the programs, then the real frontier lies not in asking LLMs to repeat familiar tasks—summarizing articles, translating documents, generating boilerplate—but in pushing symbols into new terrains.
Every civilization has advanced by expanding what can be expressed symbolically. Law turned power into written statutes. Mathematics turned intuition into formulas. Music turned feeling into notation. Each leap didn’t just communicate what people already knew; it created new kinds of knowledge that could only exist once they were symbolized.
The same challenge faces us today. If the boundary of language models is “what can be expressed in tokens,” then the opportunity is to extend the tokenizable. That means encoding governance rules so they can be executed as code, rather than debated endlessly in prose. It means finding ways to express scientific intuitions—hunches, heuristics, incomplete models—in symbolic form so they can be recombined, tested, and scaled. It means inventing new cross-disciplinary languages, hybrids of law and computation, or biology and information theory, that stretch the representational power of our symbolic universe.
These frontiers matter because universality is not static. The abacus became the Difference Engine; the Difference Engine became the Universal Turing Machine; the Universal Turing Machine became the modern computer. At each step, the primitives stayed minimal, but the range of what could be encoded expanded dramatically. Language models extend this lineage into the symbolic domain. The primitive is fixed—predict the next token—but the canvas is vast.
The question, then, is not whether LLMs can do the tasks we already understand. It is how far we can stretch symbolic representation before it breaks. What aspects of governance, science, or culture can be made expressible in symbols, and what must remain tacit or embodied? The answers will not only define the limits of language models, but also reshape the limits of human civilization itself.
看到这里,我觉得susan是我看到的最好思想家